知乎专栏同步发布: https://zhuanlan.zhihu.com/p/41133862
本来打算自己写写的,但是发现了David Foster的神作,看了就懂了。我也就不说啥了。

看不清的话,原图在后面的连接也可以找到。
没懂?!!!那我再解释下。
AlphaGo Zero主要由三个部分组成:自我博弈(self-play),训练和评估。和AlphaGo 比较,AlphaZero最大的区别在于,并没有采用专家样本进行训练。通过自己和自己玩的方式产生出训练样本,通过产生的样本进行训练;更新的网络和更新前的网络比赛进行评估。
在开始的时候,整个系统开始依照当前最好的网络参数进行自我博弈,那么假设进行了10000局的比赛,收集自我博弈过程中所得到的数据。这些数据当中包括:每一次的棋局状态以及在此状态下各个动作的概率(由蒙特卡罗搜索树得到);每一局的获胜得分以及所有棋局结束后的累积得分(胜利的+1分,失败得-1分,最后各自累加得分),得到的数据全部会被放到一个大小为500000的数据存储当中;然后随机的从这个数据当中采样2048个样本,1000次迭代更新网络。更新之后对网络进行评估:采用当前被更新的网络和未更新的网络进行比赛400局,根据比赛的胜率来决定是否要接受当前更新的网络。如果被更新的网络获得了超过55%的胜率,那么接收该被更新的网络,否则不接受。
那么我们首先来看一下AlphaZero的输入的棋局状态到底是什么。如图所示,是一个大小为19*19*17的数据,表示的是17张大小为19*19(和棋盘的大小相等)的特征图。其中,8张属于白子,8张属于黑子,标记为1的地方表示有子,否则标记为0 。剩下的一张用全1或者是全0表示当前轮到 黑子还是白子了。构成的这个数据表示游戏的状态输入到网络当中进行训练。

那么我们来看一下,AlphaZero的网络到底是怎么样的呢?
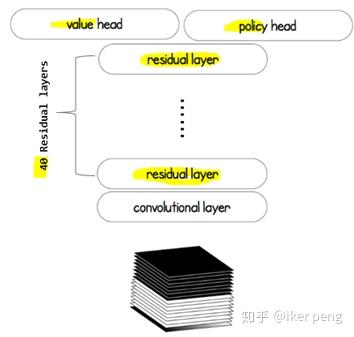
这个网络主要由三个部分组成:由40层残差网络构成的特征提取网络(身体),以及价值网络以及策略网络(两个头)。该网络当中价值网络所输出的值作为当前的状态的价值估计; 策略网络的输出作为一个状态到动作的映射概率。而这两个部分的输出都被引入到蒙特卡罗搜索树当中,用来指导最终的下棋决策。那么显然,价值网络输出的是一个1D的标量值,在-1到1之间;策略网络输出的是一个19*19*1的特征图,其中的每一个点表示的是下棋到该位置的概率。那我们来看一下,该网络是如何指导蒙特卡罗搜索树的。
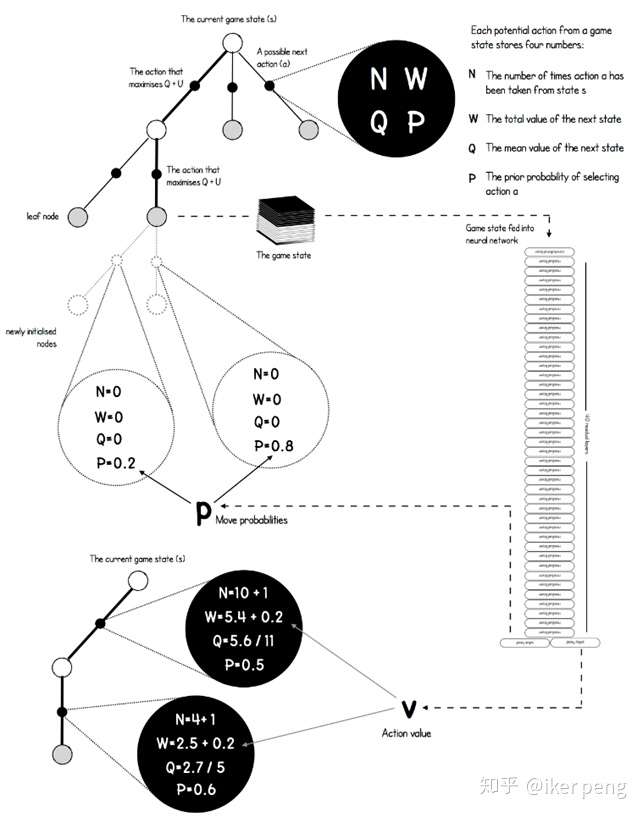
如图所示,在图中的搜索树当中,黑色的点表示的是从一个状态过渡到另一个状态的动作a;其余的节点表示的是棋局的状态,也就是之前所说的输入。从一个非叶子节点的状态开始,往往存在多种可能的行动,而其中的状态节点a具有4种属性,他们决定了到底应该如何选择。具体来讲,其中的N表示的是到目前为止,该动作节点被访问的次数;P表示网络预测出来的选择该节点的概率;W表示下一个状态的总的价值,而价值网络输出的动作的价值会被累及到这个值当中;这个值除以被访问到的次数就等于平均的价值Q。实际上,还会给Q加上一个U来起到探索更多的动作的效果。我想应该是非常清楚的。那么如何根据构建出来的搜索树进行下棋的步骤呢?在一定的阈值范围内(比如说,1000个迭代之前),采用最大化Q函数的方式来选择动作;那么当大于这个阈值之后采用蒙特卡罗搜索树的方式(例如PUCT算法,也就是根据概率和被访问的次数)来选择执行的动作。
那我们来看一下蒙特卡罗搜索树在这里面时如何实现的。首先是其中的节点:
class Node:
def __init__(self, parent=None, proba=None, move=None):
self.p = proba
self.n = 0
self.w = 0
self.q = 0
self.children = []
self.parent = parent
self.move = move
其中主要为之前所说的4个属性以及父子节点的指针。而最后一个move指出了在当前状态下的合法下棋步骤。在训练的过程中,这些值都会被更新,那么在更新之后如何通过他们来进行动作的选择呢?
def select(nodes, c_puct=C_PUCT):
" Optimized version of the selection based of the PUCT formula "
total_count = 0
for i in range(nodes.shape[0]):
total_count += nodes[i][1]
action_scores = np.zeros(nodes.shape[0])
for i in range(nodes.shape[0]):
action_scores[i] = nodes[i][0] + c_puct * nodes[i][2] * \
(np.sqrt(total_count) / (1 + nodes[i][1]))
equals = np.where(action_scores == np.max(action_scores))[0]
if equals.shape[0] > 0:
return np.random.choice(equals)
return equals[0]
这里表示的是对于任何一个节点,从其所有的子节点当中,通过PUCT算法找出最大得分的那个节点。在这个得分action_scores[i]的计算过程中,网络预测的概率和该节点被访问的次数都有被考虑。对于被访问到的非叶子节点继续进行扩展;而如果是叶子节点则进行最终的评估。至于其中的残差网络模块,价值网络,策略网络就不再一一叙述了。详细参考:
https://github.com/dylandjian/superGogithub.com
References:
https://medium.com/applied-data-science/alphago-zero-explained-in-one-diagram-365f5abf67e0