前些天学习python,完成了python练习册的大部分习题:https://github.com/Show-Me-the-Code/python(我的github上有习题代码,欢迎自取)。之后看到@salamer的一个python爬虫项目,觉得很不错。于是自己花了4天的时间完成了一个大规模爬取知乎用户信息的爬虫,由于个人网络原因,爬取12小时,获得了34k用户的信息(理论上可以爬全站的信息,可能时间要长一些,最好放在服务器上跑)并整理成直观的图表(文章末尾显示)。
好了,说一下主要的技术点:
(1)使用python的request模块获取html页面,注意要修改自己的cookie,使得我们更像是使用浏览器访问
(2)使用xpath模块从html中提取需要的关键信息(姓名,职业,居住地,关注人等)
(3)使用redis作为队列,很好的解决并发和大规模数据的问题(可以分布式)
(4)使用bfs宽度优先搜索,使得程序得以不断扩展持续搜索用户
(5)数据存储至no-sql数据库:mongodb(高效轻量级并且支持并发)
(6)使用python的进程池模块提高抓取速度
(7)使用csv,pandas,matplotlib模块进行数据处理(需要完善)
接下来我们进行仔细的分析:
(一)数据的获取
主要使用了python的request进行html的获取,另外,header中的cookie携带了我们的登陆信息,所以,按下你的F12将自己的cookie添加至程序中。
知乎上有很多水军,我们为了更加高质量的抓取用户信息,使用了这样一个策略:只抓取每个人的关注者,这样可以相对有效的减少水军和小号。

#cookie要自己从浏览器获取
self.header["User-Agent"]="Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:35.0) Gecko/20100101 Firefox/35.0"
self.cookies={"q_c1":"8074ec0c513747b090575cec4a547cbd|1459957053000|1459957053000",
"l_cap_id":'"Y2MzODMyYjgzNWNjNGY4YzhjMDg4MWMzMWM2NmJmZGQ=|1462068499|cd4a80252719f069cc467a686ee8c130c5a278ae"',
"cap_id":'"YzIwNjMwNjYyNjk0NDcyNTkwMTFiZTdiNmY1YzIwMjE=|1462068499|efc68105333307319525e1fc911ade8151d9e6a6"',
"d_c0":'"AGAAI9whuwmPTsZ7YsMeA9d_DTdC6ijrE4A=|1459957053"',
"_za":"9b9dde53-9e53-4ed1-a17f-363b875a8107",
"login":'"YWQyYzQ4ZDYyOTAwNDVjNTg2ZmY3MDFkY2QwODI5MGY=|1462068522|49dd99d3c8330436f211a130209b4c56215b8ec3"',
"__utma":"51854390.803819812.1462069647.1462069647.1462069647.1",
"__utmz":"51854390.1462069647.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic",
"_xsrf":"6b32002d2d529794005f7b70b4ad163e",
"_zap":"a769d54e-78bf-44af-8f24-f9786a00e322",
"__utmb":"51854390.4.10.1462069647",
"__utmc":"51854390",
"l_n_c":"1",
"z_c0":"Mi4wQUFBQWNJQW9BQUFBWUFBajNDRzdDUmNBQUFCaEFsVk5LdkpNVndCRlQzM1BYVEhqbWk0VngyVkswSVdpOXhreDJB|1462068522|eed70f89765a9dd2fdbd6ab1aabd40f7c23ea283",
"s-q":"%E4%BA%91%E8%88%92",
"s-i":"2",
"sid":"1jsjlbsg",
"s-t":"autocomplete",
"__utmv":"51854390.100--|2=registration_date=20140316=1^3=entry_date=20140316=1",
"__utmt":"1"}
使用xpath提取html中我们需要关注的信息,这里给个小例子,关于xpath的用法请自行百度:)
def get_xpath_source(self,source):
if source:
return source[0]
else:
return ''
tree=html.fromstring(html_text)
self.user_name=self.get_xpath_source(tree.xpath("//a[@class='name']/text()"))
self.user_location=self.get_xpath_source(tree.xpath("//span[@class='location item']/@title"))
self.user_gender=self.get_xpath_source(tree.xpath("//span[@class='item gender']/i/@class"))
(二)搜索和存储
准备搜索的url队列可能会很大,我们使用redis作为队列来存储,不仅程序退出后不会丢失数据(程序重新运行可以继续上次的搜索),而且支持分布式水平扩展和并发。
核心采用BFS宽度优先搜索来进行扩展,这里不清楚的,恐怕要自己去学习下算法了。存储提供两种方式,一种直接输出至控制台,另一种就是存储至mongodb费关系数据库。
# 核心模块,bfs宽度优先搜索
def BFS_Search(option):
global red
while True:
temp=red.rpop('red_to_spider')
if temp==0:
print 'empty'
break
result=Spider(temp,option)
result.get_user_data()
return "ok"
def store_data_to_mongo(self):
new_profile = Zhihu_User_Profile(
user_name=self.user_name,
user_be_agreed=self.user_be_agreed,
user_be_thanked=self.user_be_thanked,
user_followees=self.user_followees,
user_followers=self.user_followers,
user_education_school=self.user_education_school,
user_education_subject=self.user_education_subject,
user_employment=self.user_employment,
user_employment_extra=self.user_employment_extra,
user_location=self.user_location,
user_gender=self.user_gender,
user_info=self.user_info,
user_intro=self.user_intro,
user_url=self.url
)
new_profile.save()
(三)多进程提高效率
python由于GIL锁的原因,多线程并不能达到真正的并行。这里使用python提供的进程池进行多进程操作,这里有一个问题需要大家注意:
实际测试下来,在选取将数据存储至mongodb数据库这个方式下,多进程没能提高效率,甚至比单进程还要慢,我分析了下原因:由于计算的部分花时间很少,主要的瓶颈在磁盘IO,也就是写进数据库,一个时刻只能有一个进程在写,多进程的话会增加很多锁机制的无端开销,造成了上述结果。
但是直接输出的话速度会快很多。这也提示我们多进程并不是一定能提高速度的,要根据情况选择合适的模型。
使用多进程,注意,实际测试出来,并没有明显速度的提升,瓶颈在IO写;如果直接输出的话,速度会明显加快
res=[]
process_Pool=Pool(4)
for i in range(4):
res.append(process_Pool.apply_async(BFS_Search,(option, )))
process_Pool.close()
process_Pool.join()
for num in res:
print ":::",num.get()
print 'Work had done!'
(四)数据分析
这里我们使用csv,pandas模块进行数据分析,关于模块的使用请自行google,这里贴出自己做出的一些分析图:
知乎用户城市分布:
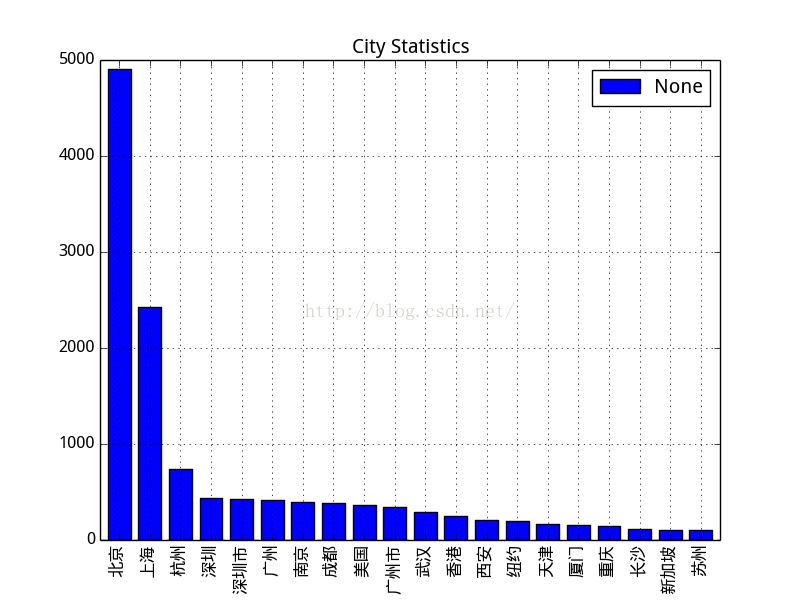
一线城市的用户高居榜首,尤其北京。美国的也好多啊..
知乎用户专业分布:
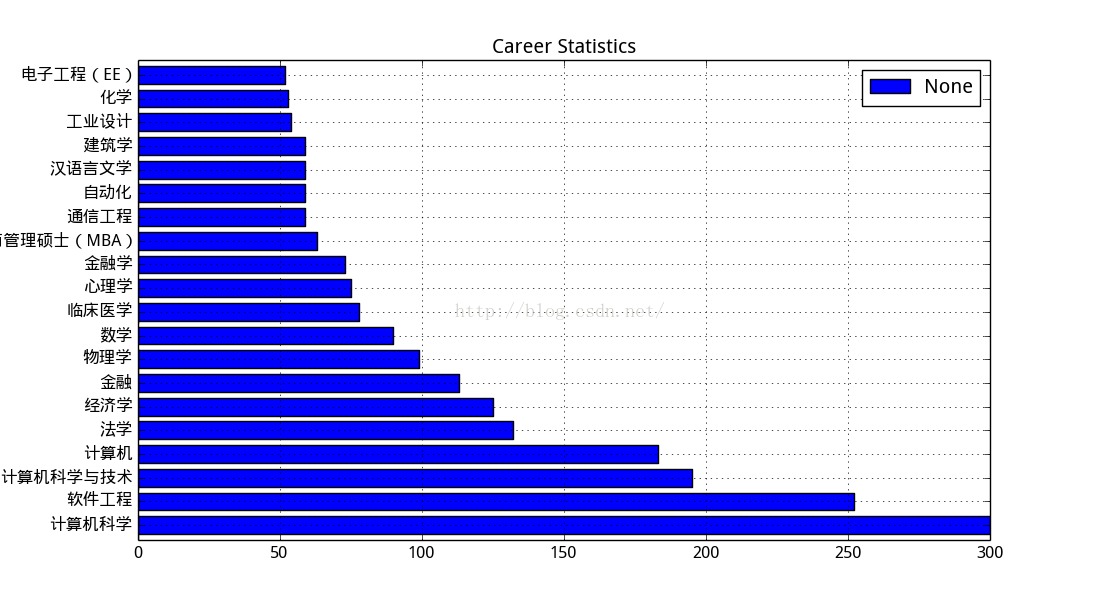
果然知乎上的程序猿最多。。
知乎用户学校分布:
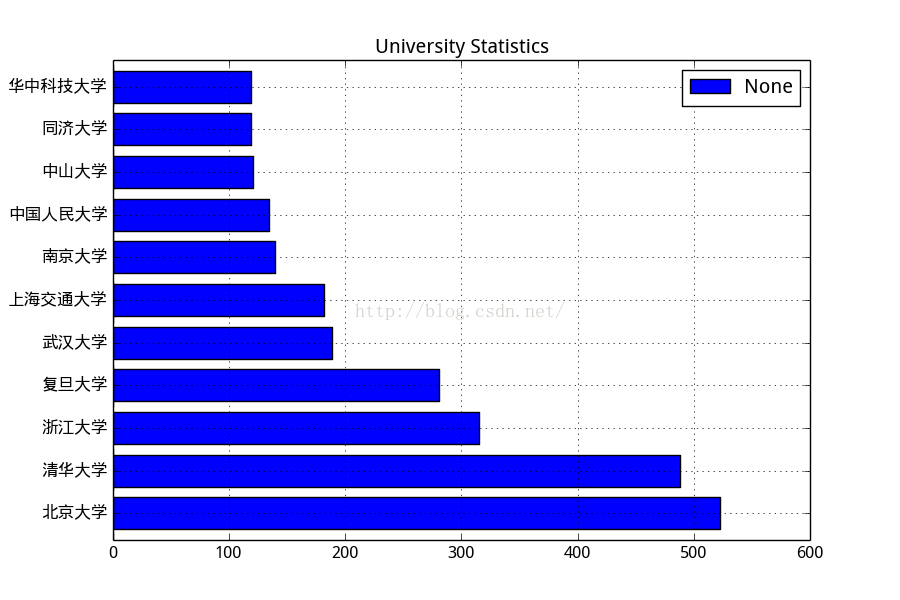
清北和华东五虎高校的学校居多,看来知乎的学生群体质量很高。
知乎用户职业分布:
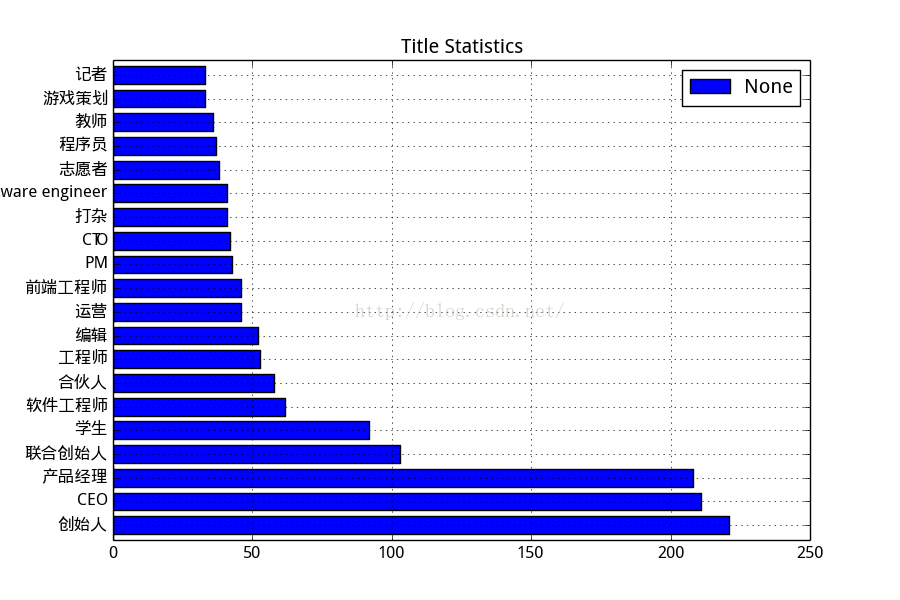
很多大佬啊,这么多创始人和CEO,还有天敌:产品经理....
好了,就展示到这里吧,对这个项目有兴趣的同学,可以到我的Github查看,源码全部在 这里
数据分析部分并不专业,希望更多的人来完善这个项目,我自己也会开启下一步学习,将其改为分布式爬虫,希望给大家带来帮助~