转自:http://blog.csdn.net/jianyuerensheng/article/details/50819155
一、对JPA的理解
JPA的总体思想和现有hibernate、TopLink,JDO等ORM框架大体一致。总的来说,JPA包括以下3方面的技术:
1. ORM映射元数据,JPA支持XML和JDK 5.0注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中;
2. JPA的API,用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来。
3. 查询语言,这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
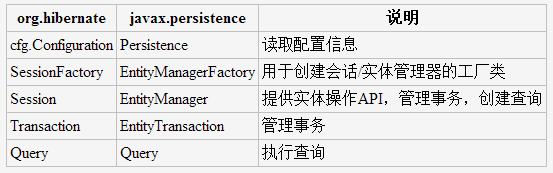
二、JPA的主要API都定义在javax.persistence包中。与Hibernate对照如下:
————————————————–
三、实体生命周期
描述了实体对象从创建到受控、从删除到游离的状态变换。对实体的操作主要就是改变实体的状态。 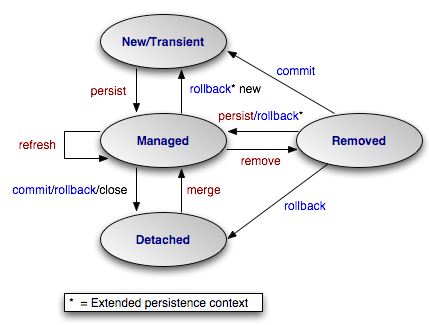
1.New,新创建的实体对象,没有主键(identity)值
2.Managed,对象处于Persistence Context(持久化上下文)中,被EntityManager管理
3.Detached,对象已经游离到Persistence Context之外,进入Application Domain
4.Removed, 实体对象被删除
EntityManager提供一系列的方法管理实体对象的生命周期,包括:
1.persist, 将新创建的或已删除的实体转变为Managed状态,数据存入数据库。
2.remove,删除受控实体
3.merge,将游离实体转变为Managed状态,数据存入数据库。
如果使用了事务管理,则事务的commit/rollback也会改变实体的状态。
四、实体关系映射(ORM)
- 基本映射

2. ID生成策略
ID对应数据库表的主键,是保证唯一性的重要属性。JPA提供了以下几种ID生成策略
(1) GeneratorType.AUTO ,由JPA自动生成
(2) GenerationType.IDENTITY,使用数据库的自增长字段,需要数据库的支持(如SQL Server、MySQL、DB2、Derby等)
(3) GenerationType.SEQUENCE,使用数据库的序列号,需要数据库的支持(如Oracle)
(4) GenerationType.TABLE,使用指定的数据库表记录ID的增长 需要定义一个TableGenerator,在@GeneratedValue中引用。例如:
@TableGenerator( name=”myGenerator”, table=”GENERATORTABLE”, pkColumnName = “ENTITYNAME”, pkColumnValue=”MyEntity”, valueColumnName = “PKVALUE”, allocationSize=1 )
@GeneratedValue(strategy = GenerationType.TABLE,generator=”myGenerator”)
- 关联关系
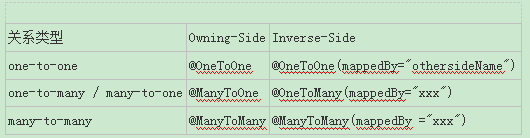
JPA定义了one-to-one、one-to-many、many-to-one、many-to-many 4种关系。
对于数据库来说,通常在一个表中记录对另一个表的外键关联;对应到实体对象,持有关联数据的一方称为owning-side,另一方称为inverse-side。
为了编程的方便,我们经常会希望在inverse-side也能引用到owning-side的对象,此时就构建了双向关联关系。 在双向关联中,需要在inverse-side定义mappedBy属性,以指明在owning-side是哪一个属性持有的关联数据。
对关联关系映射的要点如下:
其中 many-to-many关系的owning-side可以使用@JoinTable声明自定义关联表,比如Book和Author之间的关联表:
@JoinTable(name = “BOOKAUTHOR”, joinColumns = { @JoinColumn(name = “BOOKID”, referencedColumnName = “id”) }, inverseJoinColumns = { @JoinColumn(name = “AUTHORID”, referencedColumnName = “id”) })
关联关系还可以定制延迟加载和级联操作的行为(owning-side和inverse-side可以分别设置):
通过设置fetch=FetchType.LAZY 或 fetch=FetchType.EAGER来决定关联对象是延迟加载或立即加载。
通过设置cascade={options}可以设置级联操作的行为,其中options可以是以下组合:
CascadeType.MERGE 级联更新
CascadeType.PERSIST 级联保存
CascadeType.REFRESH 级联刷新
CascadeType.REMOVE 级联删除
CascadeType.ALL 级联上述4种操作 - 继承关系
JPA通过在父类增加@Inheritance(strategy=InheritanceType.xxx)来声明继承关系。A支持3种继承策略:
(1) 单表继承(InheritanceType.SINGLETABLE),所有继承树上的类共用一张表,在父类指定(@DiscriminatorColumn)声明并在每个类指定@DiscriminatorValue来区分类型。
(2) 类表继承(InheritanceType.JOINED),父子类共同的部分公用一张表,其余部分保存到各自的表,通过join进行关联。
(3) 具体表继承(InheritanceType.TABLEPERCLASS),每个具体类映射到自己的表。
其中1和2能够支持多态,但是1需要允许字段为NULL,2需要多个JOIN关系;3最适合关系数据库,对多态支持不好。具体应用时根据需要取舍。
- 顶
转自:http://blog.csdn.net/jianyuerensheng/article/details/50819155
一、对JPA的理解
JPA的总体思想和现有hibernate、TopLink,JDO等ORM框架大体一致。总的来说,JPA包括以下3方面的技术:
1. ORM映射元数据,JPA支持XML和JDK 5.0注解两种元数据的形式,元数据描述对象和表之间的映射关系,框架据此将实体对象持久化到数据库表中;
2. JPA的API,用来操作实体对象,执行CRUD操作,框架在后台替我们完成所有的事情,开发者从繁琐的JDBC和SQL代码中解脱出来。
3. 查询语言,这是持久化操作中很重要的一个方面,通过面向对象而非面向数据库的查询语言查询数据,避免程序的SQL语句紧密耦合。
二、JPA的主要API都定义在javax.persistence包中。与Hibernate对照如下:
————————————————–
三、实体生命周期
描述了实体对象从创建到受控、从删除到游离的状态变换。对实体的操作主要就是改变实体的状态。
1.New,新创建的实体对象,没有主键(identity)值
2.Managed,对象处于Persistence Context(持久化上下文)中,被EntityManager管理
3.Detached,对象已经游离到Persistence Context之外,进入Application Domain
4.Removed, 实体对象被删除
EntityManager提供一系列的方法管理实体对象的生命周期,包括:
1.persist, 将新创建的或已删除的实体转变为Managed状态,数据存入数据库。
2.remove,删除受控实体
3.merge,将游离实体转变为Managed状态,数据存入数据库。
如果使用了事务管理,则事务的commit/rollback也会改变实体的状态。
四、实体关系映射(ORM)
- 基本映射
2. ID生成策略
ID对应数据库表的主键,是保证唯一性的重要属性。JPA提供了以下几种ID生成策略
(1) GeneratorType.AUTO ,由JPA自动生成
(2) GenerationType.IDENTITY,使用数据库的自增长字段,需要数据库的支持(如SQL Server、MySQL、DB2、Derby等)
(3) GenerationType.SEQUENCE,使用数据库的序列号,需要数据库的支持(如Oracle)
(4) GenerationType.TABLE,使用指定的数据库表记录ID的增长 需要定义一个TableGenerator,在@GeneratedValue中引用。例如:
@TableGenerator( name=”myGenerator”, table=”GENERATORTABLE”, pkColumnName = “ENTITYNAME”, pkColumnValue=”MyEntity”, valueColumnName = “PKVALUE”, allocationSize=1 )
@GeneratedValue(strategy = GenerationType.TABLE,generator=”myGenerator”)
- 关联关系
JPA定义了one-to-one、one-to-many、many-to-one、many-to-many 4种关系。
对于数据库来说,通常在一个表中记录对另一个表的外键关联;对应到实体对象,持有关联数据的一方称为owning-side,另一方称为inverse-side。
为了编程的方便,我们经常会希望在inverse-side也能引用到owning-side的对象,此时就构建了双向关联关系。 在双向关联中,需要在inverse-side定义mappedBy属性,以指明在owning-side是哪一个属性持有的关联数据。
对关联关系映射的要点如下:
其中 many-to-many关系的owning-side可以使用@JoinTable声明自定义关联表,比如Book和Author之间的关联表:
@JoinTable(name = “BOOKAUTHOR”, joinColumns = { @JoinColumn(name = “BOOKID”, referencedColumnName = “id”) }, inverseJoinColumns = { @JoinColumn(name = “AUTHORID”, referencedColumnName = “id”) })
关联关系还可以定制延迟加载和级联操作的行为(owning-side和inverse-side可以分别设置):
通过设置fetch=FetchType.LAZY 或 fetch=FetchType.EAGER来决定关联对象是延迟加载或立即加载。
通过设置cascade={options}可以设置级联操作的行为,其中options可以是以下组合:
CascadeType.MERGE 级联更新
CascadeType.PERSIST 级联保存
CascadeType.REFRESH 级联刷新
CascadeType.REMOVE 级联删除
CascadeType.ALL 级联上述4种操作 - 继承关系
JPA通过在父类增加@Inheritance(strategy=InheritanceType.xxx)来声明继承关系。A支持3种继承策略:
(1) 单表继承(InheritanceType.SINGLETABLE),所有继承树上的类共用一张表,在父类指定(@DiscriminatorColumn)声明并在每个类指定@DiscriminatorValue来区分类型。
(2) 类表继承(InheritanceType.JOINED),父子类共同的部分公用一张表,其余部分保存到各自的表,通过join进行关联。
(3) 具体表继承(InheritanceType.TABLEPERCLASS),每个具体类映射到自己的表。
其中1和2能够支持多态,但是1需要允许字段为NULL,2需要多个JOIN关系;3最适合关系数据库,对多态支持不好。具体应用时根据需要取舍。