要学习进而掌握大数据开发,无论是Hadoop还是Spark,集群环境部署都是一个很重要的方面。利用Vmware虚拟机软件,可以在一台Windows 7的机器上虚拟出集群部署的环境,方便我们学习,开发及测试。本文记录了笔者在尝试搭建Hadoop虚拟机集群环境时的一些经验和教训,对自己的摸索和实践做个总结,也希望能给其他初学者有所帮助。
本文的Hadoop集群搭建在Vmware Workstation 11之上,共包括SparkMaster,SparkWorker1和SparkWorker2三台虚拟机:
 Vmware的宿主机为64位Windows 7旗舰版,虚拟机集群安装的系统为ubuntukylin-14.04.2-desktop-amd64.iso。宿主机配置为i3,8G内存,虚拟机系统配置为1G内存。本来虚拟机系统建议是配置为2G内存的,那样的话3台虚拟机同时开启,主机的内存太少,虚拟机运行起来就会很卡了。Hadoop的版本是2.7.4,因为后面还想测试Spark集群,目前看到的最新Spark整合Hadoop的包是基于Hadoop2.7版本,所以没有选用最新的Hadoop版本。
Vmware的宿主机为64位Windows 7旗舰版,虚拟机集群安装的系统为ubuntukylin-14.04.2-desktop-amd64.iso。宿主机配置为i3,8G内存,虚拟机系统配置为1G内存。本来虚拟机系统建议是配置为2G内存的,那样的话3台虚拟机同时开启,主机的内存太少,虚拟机运行起来就会很卡了。Hadoop的版本是2.7.4,因为后面还想测试Spark集群,目前看到的最新Spark整合Hadoop的包是基于Hadoop2.7版本,所以没有选用最新的Hadoop版本。
集群搭建成功之后,在集群的master上启动Hadoop之后,可以在Windows主机的浏览器中,输入http://SparkMaster:50070,通过Web界面去浏览Hadoop集群的相关信息(当然,前提是已经提前把SparkMaster的IP配置到了Windows7的hosts文件中了):
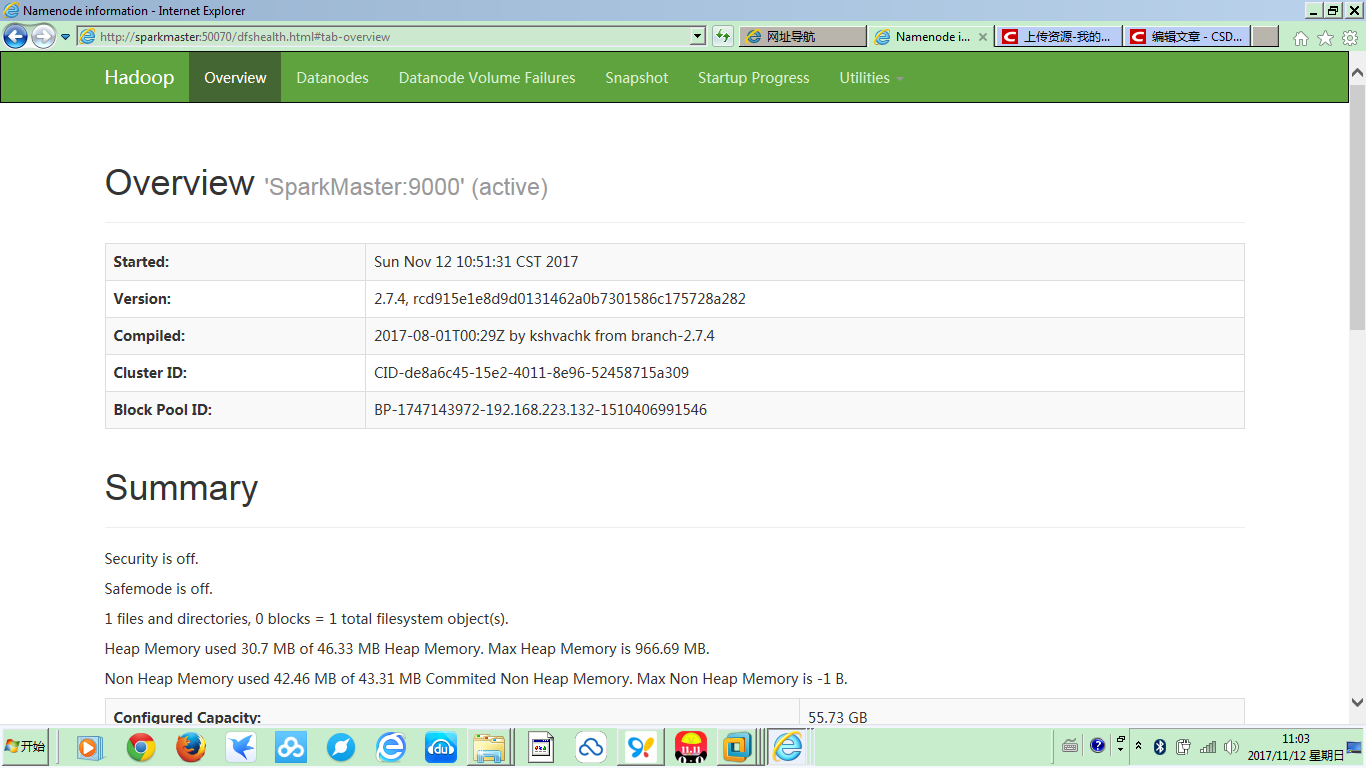
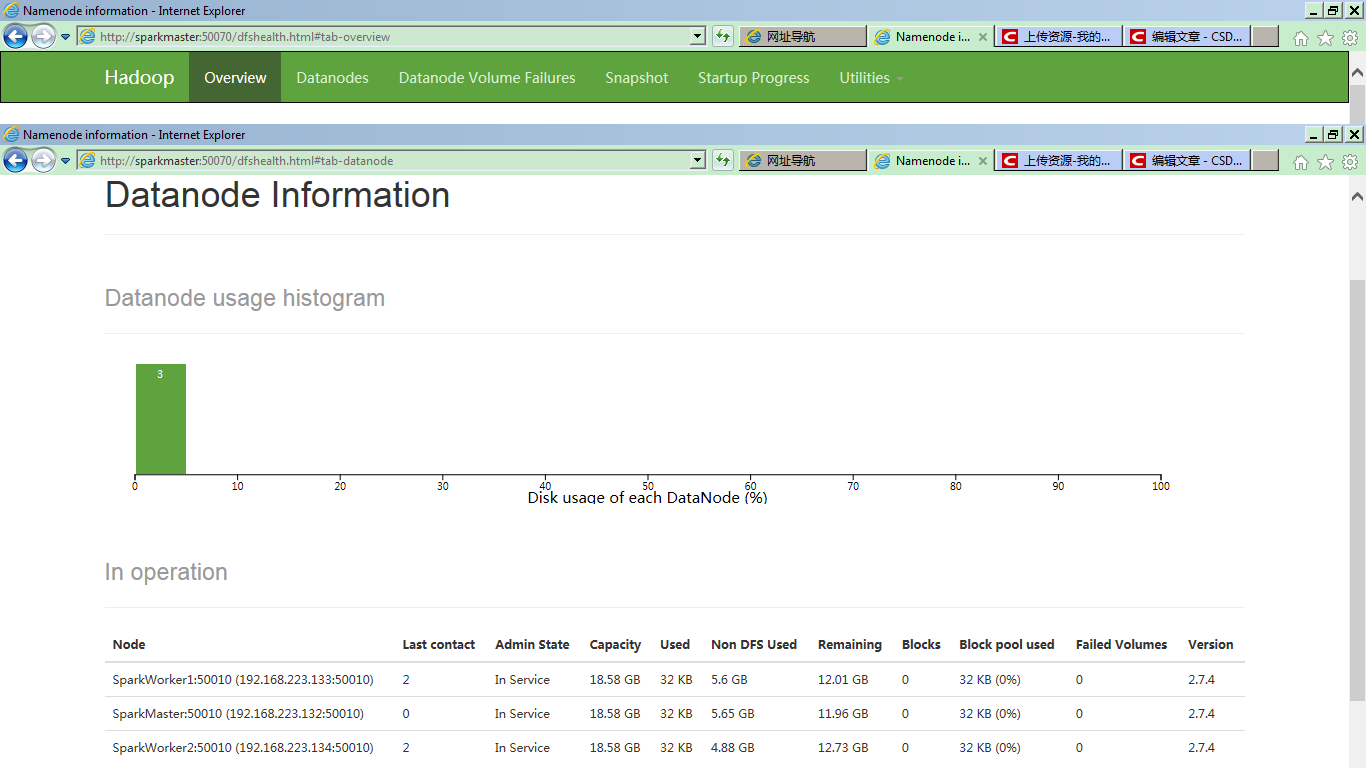
在Overview的下部详细信息中,可以明确看到,集群有三个Live Nodes:
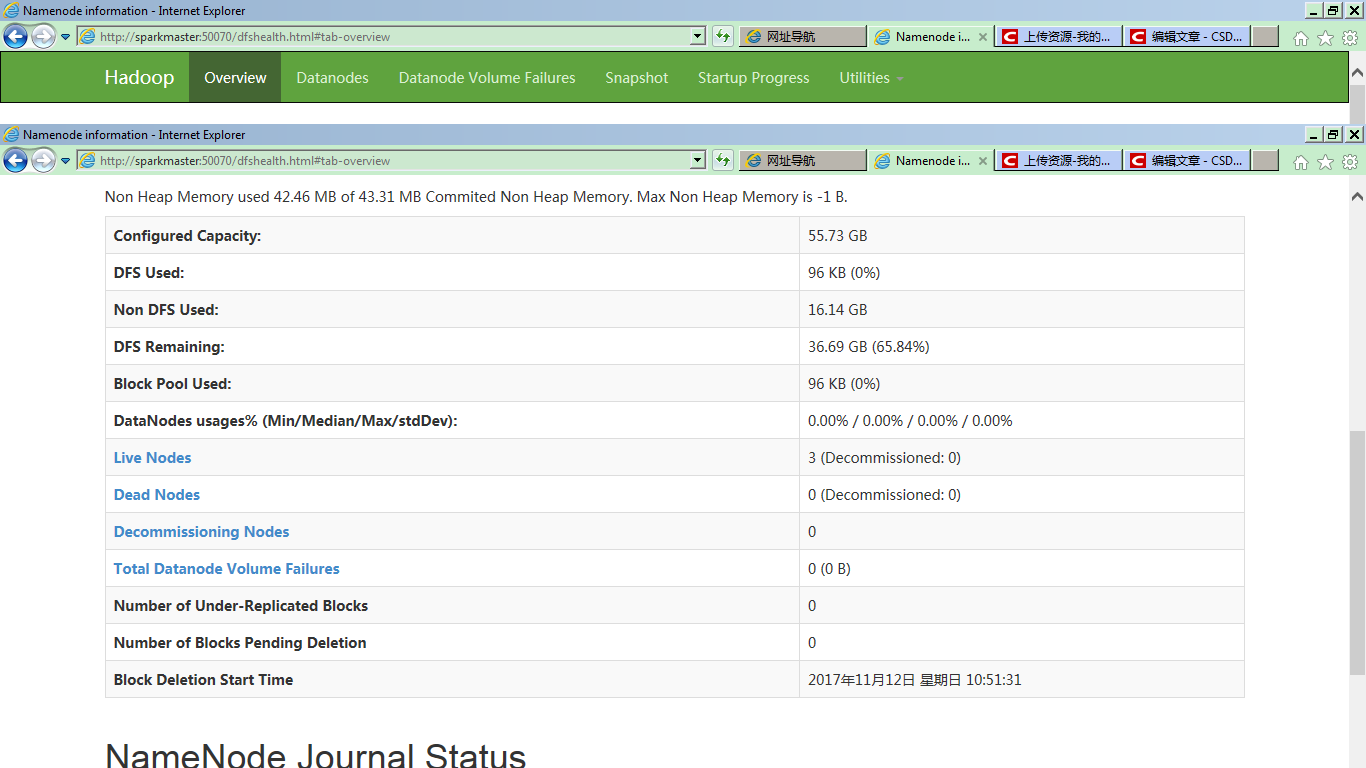
切换到DataNode view,会看到三个DataNode,一个SparkMaster(兼做NameNode和DataNode),一个SparkWorker1,和一个SparkWorker2,两个DataNode:
在Windows 7上安装Vmware Workstation 11,然后搭建基于Ubuntu kylin 14.04的Hadoop2.7.4的集群,主要有以下三个步骤:
第一个步骤,是安装Vmware Workstation 11虚拟机软件,然后安装三个Ubuntu kylin 14.04的系统,分别命名为SparkMaster,SparkWorker1和SparkWorker2。
这一步一般不会有什么问题,上网下软件包,一路回车安装完成就好了。
第二个步骤,是要对集群中的各个Ubuntu机器进行设置,实现相互之间的SSH免密码登录。
首先是要设置成root用户登录。Ubuntu kylin 14.04的系统,root用户缺省是没有打开的。需要手工开启。
在SparkMaster上启动命令终端,sudo -s 进入root用户权限模式,输入 vim /etc/lightdm/lightdm.conf,编辑修改配置文件如下(如果提示vim命令错误,需要先安装vim安装包,apt-get install vim):
[SeatDefaults]
greeter-session=unity-greeter
user-session=ubuntu
greeter-show-manual-login=true #手工输入登录系统的用户名和密码
allow-guest=false #不允许guest登录
保存后,输入sudo passwd root 设置root用户的密码为root(也可以设置为其他密码)。完成后,再次启动Ubuntu,就会提示输入用户名及密码了。这时输入root用户名及其密码,就可以root用户登录系统了。
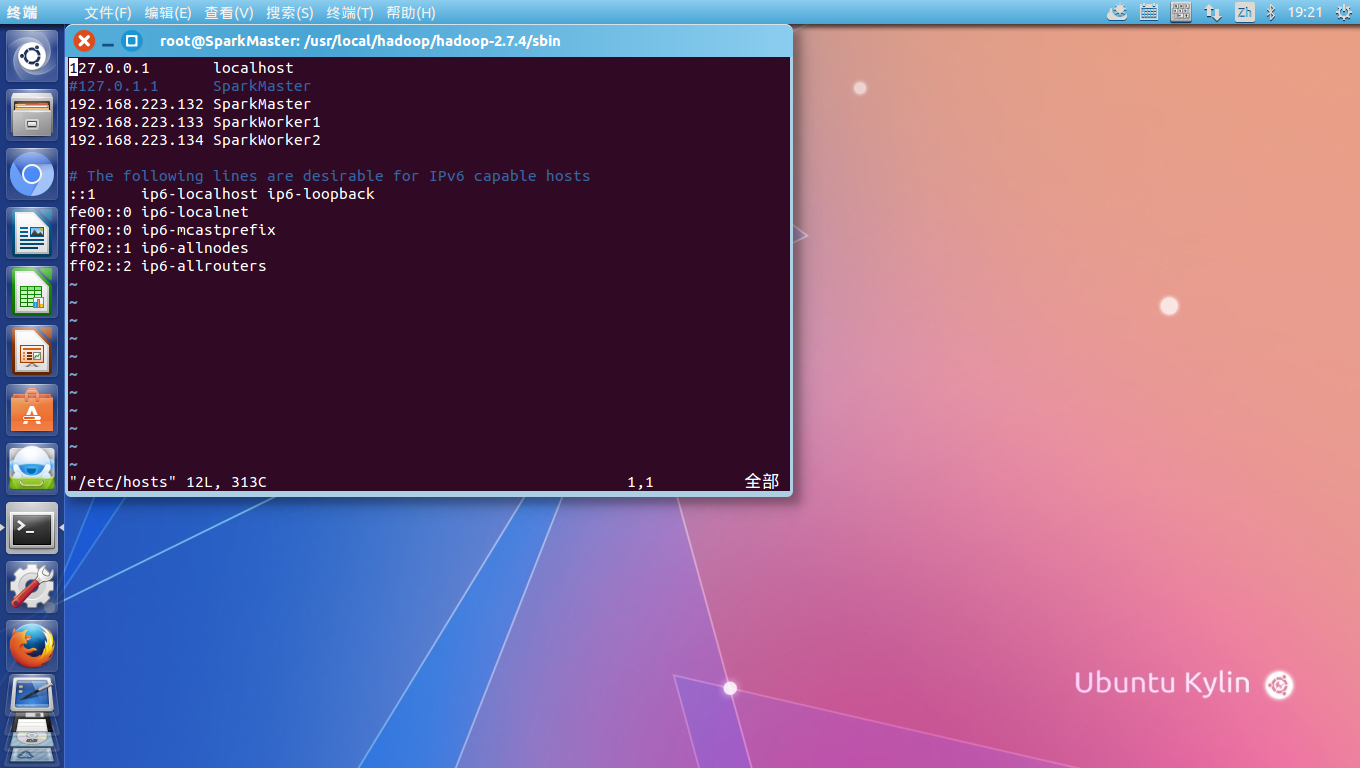
接下来,要修改hosts文件,加入三个集群机器名与IP地址的对应关系,vim /etc/hosts 加入三台Ubuntu的名称和IP的对应关系:
查看虚拟机的IP,可以在终端输入ifconfig。这些对应关系也可以加到Windows 7宿主机的hosts中,这样,hadoop集群的web界面也可以在Win7浏览器直接访问了。
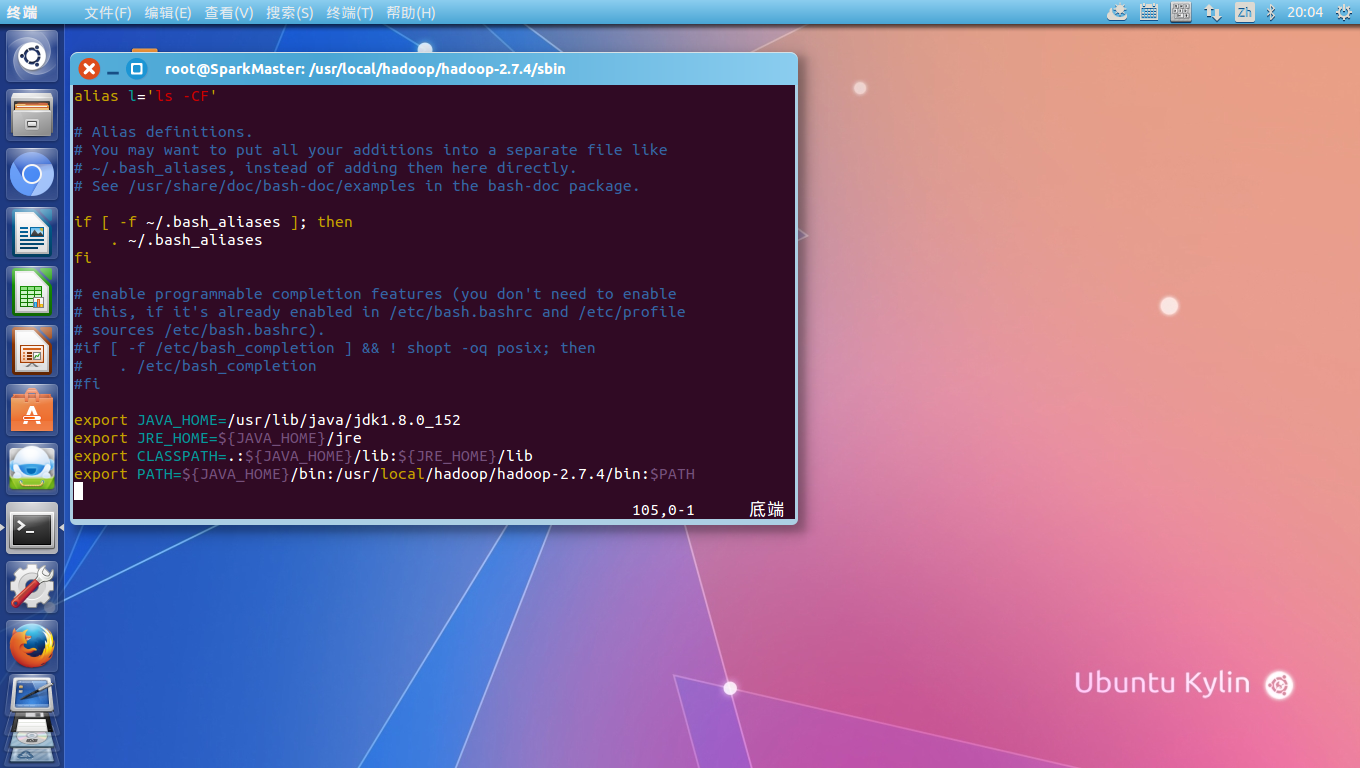
第三步,下载JDK,解压安装到/usr/lib/java下,并相应修改~/.bashrc,加入Java_Home 的设定及ClassPath和path的设定:
然后source ~/.ashrc,输入java -version,应该正确显示java的安装版本,这里是1.8.如果显示命令错误或版本不对,请检查jdk安装路径及.bashrc文件的设定。
第四步,安装SSH软件包。由于Ubuntu 14.04已经预装了SSH Client,所以只需安装SSH Server就可以了。当然,也可以重新安装整个SSH。
apt-get install openssh-server
安装完成后,可能需要重启,然后启动ssh 服务 services start ssh,然后ps -e | grep ssh,查看sshd进程是否正常启动。如果ssh或sshd进程未能正常启动,请检查ssh安装情况或百度ssh进程不能正常启动的原因。
第五步,配置Ubuntu集群机器的SSH免密码登录。这是整个集群配置的最关键的一步。首先,要生成免密码登录用到的rsa key。免密码登录后,账号验证还是需要的,所以就要生成rsa 的密钥对来验证。ssh安装成功后,输入ssh-keygen -t rsa,提示输入密码时,直接回车,完成后会在root/.ssh目录下生成两个文件:私钥id_rsa和公钥id_rsa.pub,利用cat命令,cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 把公钥追加到authorized_keys中,因为authorized_keys用于保存所有允许以当前用户身份登录到ssh客户端用户的公钥内容。
现在输入ssh localhost,第一次会要求输入密码,再次登录时,就可以免密码直接登录了。
在SparkWorker1和SparkWorker2机器上同样以上五步操作,确保三台机器本地都可以SSH免密码登录。
现在三台Ubuntu机器都已配置好了hosts文件,可以用ping 命令在三个机器上测试与另外两个的通信是否正常。如果不能正常ping通,需要检查hosts文件是否配置正确。
要实现集群功能,就要在三台Ubuntu机器之间实现SSH免密码登录,就需要把各自的rsa 公钥传递到其余的机器上。这时,需要对SSH的远程登录进行设置。
先在SparkMaster上进行设置。
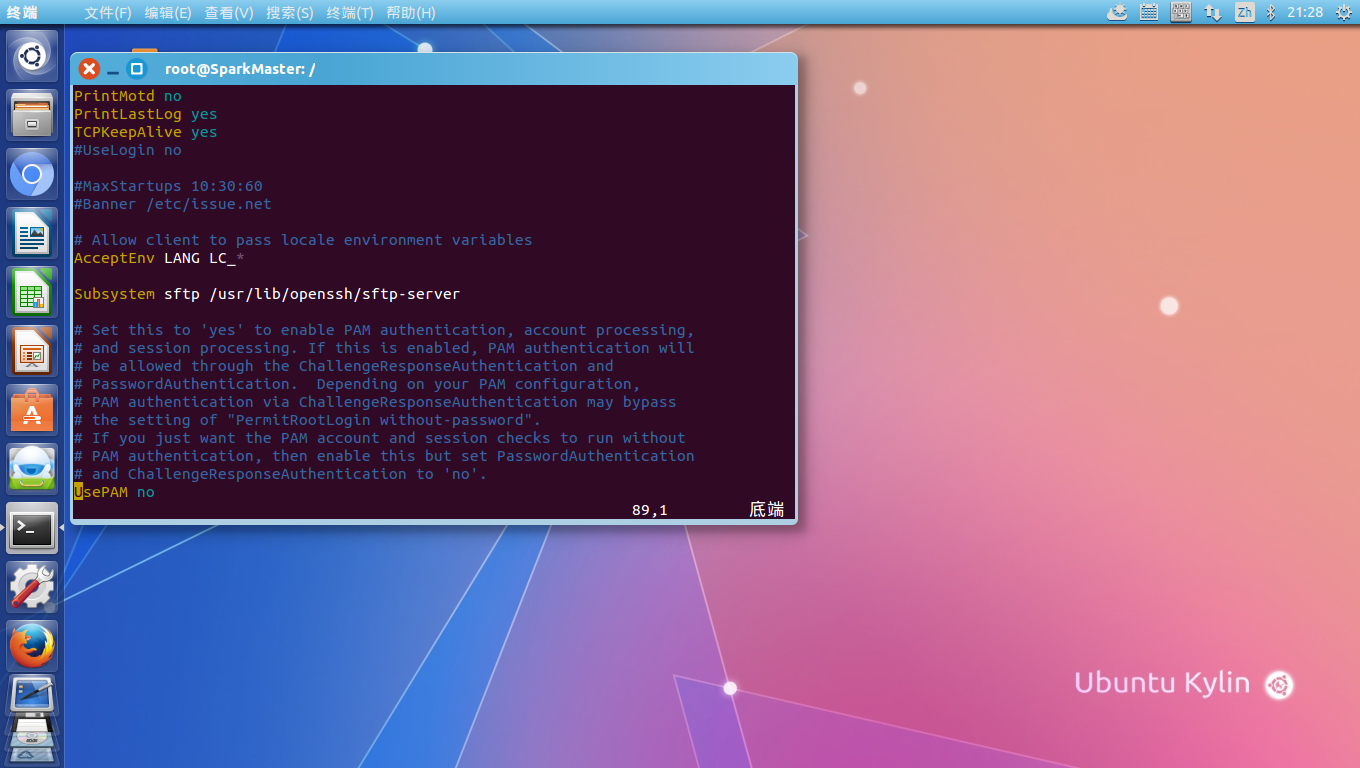
vim /etc/ssh/sshd_config,:
找到PermitRootLogin without-password加一个”#”号,把它注释掉,再增加一句”PermitRootLogin yes
因为在传输rsa 公钥时,远程登录还只能采用密码验证,所以把里面的RSAAuthentication 和 PubkeyAuthentication都设置为no,然后,也是最重要的一点,在这里卡了我好几天才解决,要把配置文件最底部的UsePAM改为no(缺省为yes),否则,远程登录一直会报一个Access denied (publickey,password)的错误:
SparkMaster设置好之后,可以利用scp命令,传输SparkWorker1和SparkWorker2的SSH 登录的公钥到SparkMaster:
在SparkMaster上检查文件是否传输过来:
然后同样利用cat命令,把Worker1和Worker2的公钥加入到SparkMaster的authorized_keys中:
cat id_rsa.pub.worker1 >> authorized_keys
cat id_rsa.pub.worker2 >> authorized_keys
然后设定SparkMaster的sshd_config使用RSAAuthentication:
这时,从SparkWorker1和SparkWorker2到SparkMaster,都可以SSH免密码登录了。
同样可以完成到SparkWorker1和到SparkWorker2的免密码登录,步骤和SparkMaster完全一致,在此不再赘述。
在Vmware上搭建Hadoop集群的第三步骤,就是设定Hadoop集群的参数。首先是在SparkMaster上进行Hadoop的安装部署和参数设置,完成后用scp同步复制到SparkWorker1和SparkWorker2上即可。
下载hadoop-2.7.4.tar.gz 并解压安装到/usr/local/hadoop/hadoop-2.7.4目录,到/usr/local/hadoop/hadoop-2.7.4/etc/hadoop目录下修改配置文件:
首先修改core-site.xml,加入:
<property>
<name>fs.defaultFS</name>
<value>hdfs://SparkMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop-2.7.4/tmp</value>
</property>
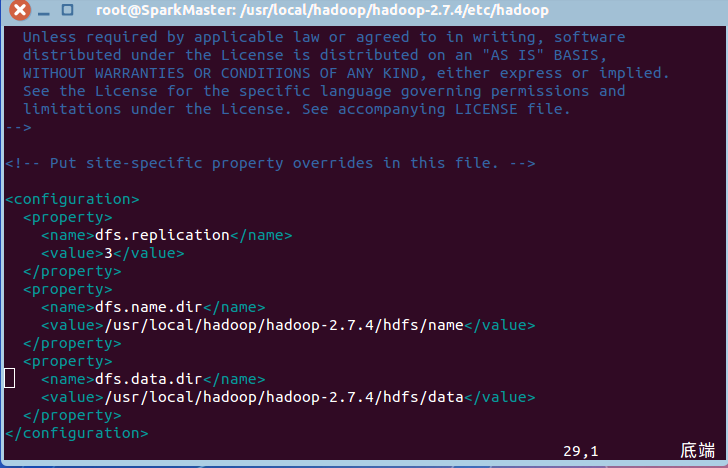
然后修改hdfs_site.xml:
可以看到,和单机版的Hadoop不同的是,这里的replication设置成3,也就是集群中DataNode的个数。
修改mapred-site.xml,使用yarn进行资源管理:
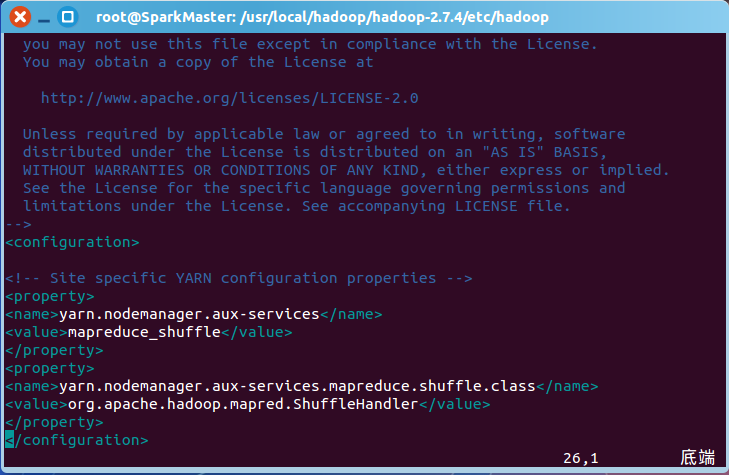
然后修改yarn-site.xml,对yarn进行配置:
、
最后修改hadoop的Masters 和Slaves配置,Masters中设置为SparkMaster,Slaves中设置为SparkMaster,SparkWorker1和SparkWorker2:
、
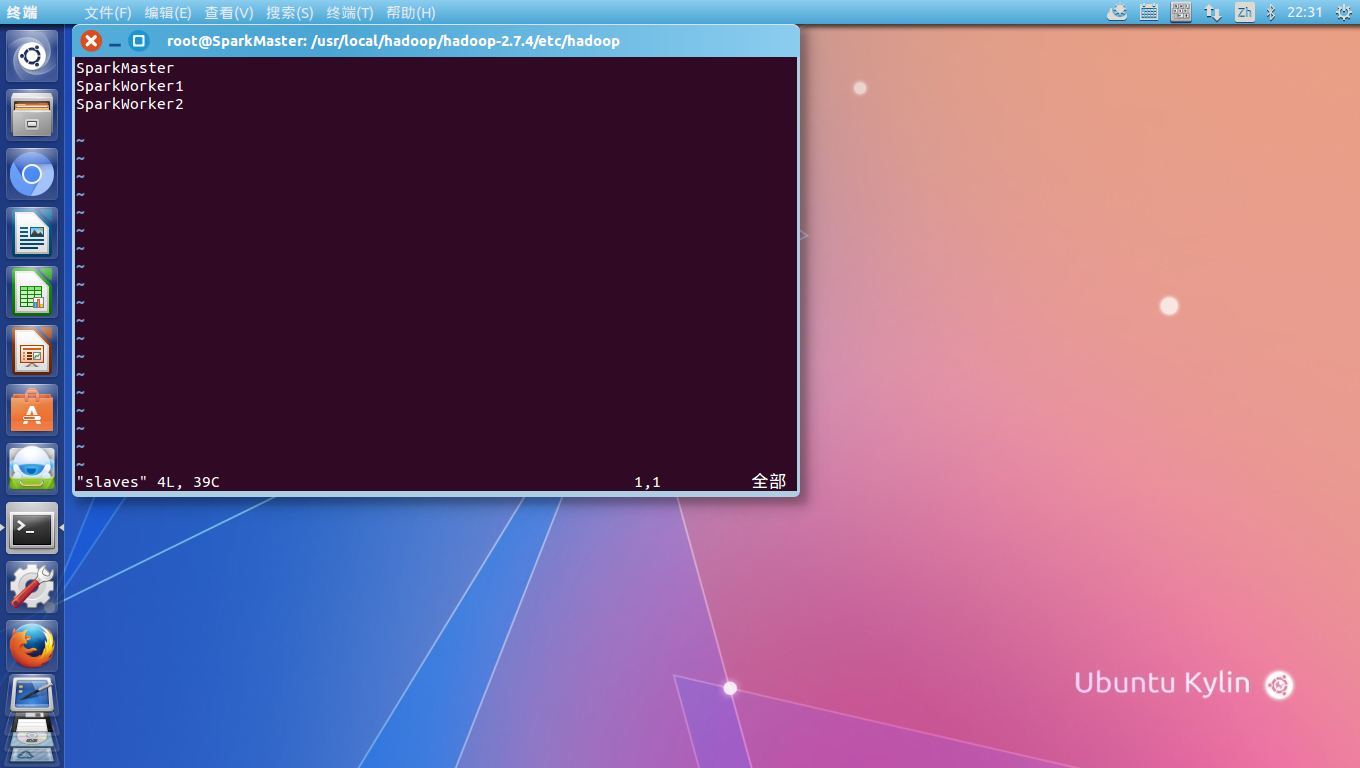
Hadoop设置完成后,使用scp命令,把hadoop整个从SparkMaster复制到SparkWorker1和SparkWorker2:
复制传输完成后,重启三台机器,然后在SparkMaster上,格式化集群的文件系统:
hadoop namenode -format
完成后就可以到/usr/local/hadoop/hadoop-2.7.4/sbin目录下,输入./start-all.sh来启动整个hadoop集群了。
这时,可以在SparkMaster上,用jps命令,查看启动的进程,有一个NameNode,一个DataNode:
而在SparkWorker1或SparkWorker2上,只有一个DataNode:
如果以前在SparkMaster上曾经部署过Hadoop的单机版,或者曾经多次执行过hadoop的namenode format,都有可能会造成集群的DataNode启动不了,这时,需要先执行./stop-all.sh,停止hadoop集群,然后手工删除三台集群机器上hadoop安装目录下的tmp,hdfs和logs目录的所有内容:
最后在SparkMaster上重新执行namenode的format,执行完毕后再次启动hadoop集群,即可成功启动。
以上内容,参考了王家林老师的Spark实战高手之路的系列文档及网上诸多网友的博客,在此一并致谢。