####数据库的读写分离
环境要干净,停掉服务
server1和server2和server3一定要停掉服务,删掉信息
/etc/init.d/mysqld stop
cd /var/lib/mysql
rm -fr *
server1 作为调度器,server2和server3里面做组从复制
###在server2和server3里面做
vim /etc/my.cnf ##在2,3里面都改
server_id=2
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_bin=binlog
binlog_format=ROW
/etc/init.d/mysqld start
grep password /var/log/mysqld.log
mysql_secure_installation
mysql -p
grant replication slave on *.* to repl@'%' identified by 'Wb@123456';
show master status;

在server3里面
vim /etc/my.cnf ##在2,3里面都改
server_id=3
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_bin=binlog
binlog_format=ROW

/etc/init.d/mysqld start
grep password /var/log/mysqld.log
mysql_secure_installation
mysql -p
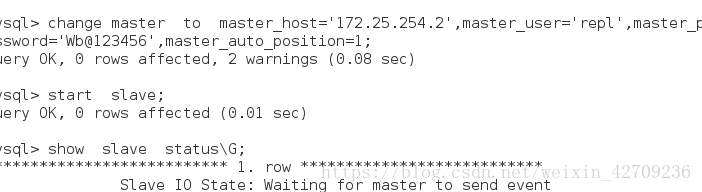
change master to master_host='172.25.254.2',master_user='repl',master_password='Wb@123456',master_auto_position=1;
start slave;
show slave status\G; ##此时应该没有起来,没有起来的话,做下列操作,起来的话不用管
stop slave;
reset master; ###在master和slave里面都要reset master
reset master; reset slave; ##在slave里面做的操作
start slave;
show slave status\G; ###此时应该为yes

##在调度器端
下载一个包
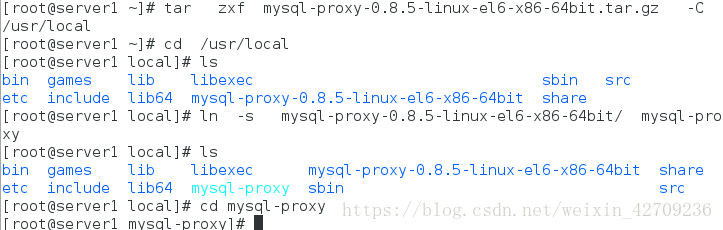
tar zxf mysql-proxy-0.8.5-linux-el6-x86-64bit.tar.gz -C /usr/local/
cd /usr/local
ls
ln -s mysql-proxy-0.8.5-linux-el6-x86-64bit mysql-proxy
cd mysql-proxy
ls
pwd ##此时位置应该在/usr/local/mysql-proxy
mkdir conf
mkdir logs
cd conf
vim mysql-proxy.conf ##这是一个新建立的文件
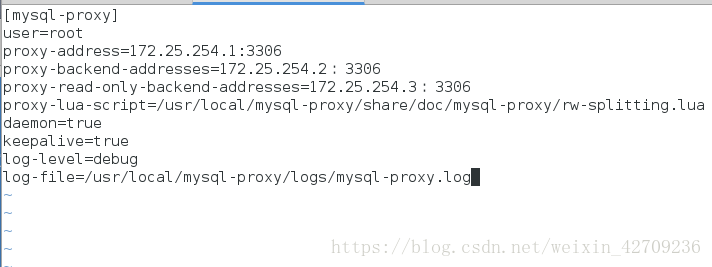
[mysql-proxy]
user=root
proxy-address=172.25.254.1:3306 ###这是调度器的位置
proxy-backend-addresses=172.25.254.2:3306 ##这是master的位置
proxy-read-only-backend-addresses=172.25.254.3:3306 ##这是slave的位置
proxy-lua-script=/usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua
daemon=true
keepalive=true
log-level=debug
log-file=/usr/local/mysql-proxy/logs/mysql-proxy.log
cd /usr/local/mysql-proxy/share/doc/mysql-proxy/
vi rw-splitting.lua
将最小连接数和最大连接数改为1和2
if not proxy.global.config.rwsplit then
proxy.global.config.rwsplit = {
min_idle_connections = 1,
max_idle_connections = 2,
is_debug = false
}
end

ll /usr/local/mysql-proxy/share/doc/mysql-proxy/rw-splitting.lua/
chmod 660 /usr/local/mysql-proxy/conf/mysql-proxy.conf
/usr/local/mysql-proxy/bin/mysql-proxy --defaults-file=/usr/local/mysql-proxy/conf/mysql-proxy.conf
ps ax ##显示有没有进程在跑

netstat -antlupe ##g观看3306端口是否对应mysql-proxy

####在主上master授权
grant insert,update on wubian.* to root@'%' identified by 'Wb@123456';
create database wubian;
use wubian;
create table usertb(username varchar(20) not null,
password varchar(20) not null);
use mysql;
select * from user; ##产看数据库的授权情况

测试:
物理机
mysql -h 172.25.254.1 -u root -p wubian ###如果没有mysql,下载mysql yum install mysql ##登陆的是调度器的位置
##在主从2.3里面看
netstat -antlupe ##主两个3306的进程,从一个进程,因为还没到限制数,还不到读写分离的时候
为了看的更清晰
yum install -y lsof
lsof -i :3306

这是链接一个的情况


这是连接2个的情况


这是链接3个的情况
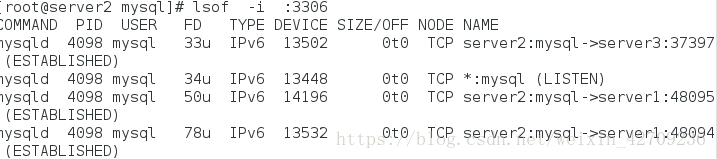
当连接的数量超过你所设定的连接的数值时,读的是slave,写入的是master,开两个物理机连接他,就会多两个线程,用lsof 查看

高可用数据库
要开4台服务器
server1 server3是从,server2是主,4是manager
在server1里面,杀死进程mysql-proxy #把server1调度器改为 从机
ps ax ##查看进程还有没有
cd /var/lib/mysql
rm -fr *
ls
vim /etc/my.cnf
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
master_info_repository=TABLE
relay_log_info_repository=TABLE
log_bin=binlog
binlog_format=ROW
####去server4里面
vim /etc/hosts
###做域名解析
得到一个mysql的高可用包MHA
ls ##有MHA这个包
cd MHA
ls
yum install -y mha4mysql-manager-0.56-0.el6.noarch.rpm perl-* *.rpm
scp mha4mysql-node-0.56-0.el6.noarch.rpm server1: ##把节点给1,2,3传过去
scp mha4mysql-node-0.56-0.el6.noarch.rpm server2:
scp mha4mysql-node-0.56-0.el6.noarch.rpm server3:
在server1,server2,server3里面分别下载
yum install -y mha4mysql-node-0.56-0.el6.noarch.rpm
在server1里面做
/etc/init.d/mysqld start
grep password /var/log/mysqld.log
mysql_secure_installation
mysql -p
change master to master_host='172.25.17.2',master_user='repl',master_password='Wb@123456',master_auto_position=1;
start slave;
show slave status\G;
测试:首先必须在master里面插入东西,然后在从里面看数据有没有同步;如果同步,就是好的,在做下面的操作,不同步则看show slave status\G; show master status; 看线程和i/o线程有没有开
在server4也就是manager里面做
cd
mkdir /etc/masterha
cd /etc/masterha
ls
vim app1.cnf
[server default]
manager_workdir=/etc/masterha
manager_log=/etc/masterha/manager.log
master_binlog_dir=/var/lib/mysql
#master_ip_failover_script= /usr/bin/master_ip_failover
#master_ip_online_change_script= /usr/local/bin/master_ip_online_chang
password=Wb@123456 ##数据库的密码
user=root ##设置监控用户root
ping_interval=1
remote_workdir=/tmp
repl_password=Wb@123456 ##设置复制用户的密阿
repl_user=repl ##授权谁能登陆
#report_script=/usr/local/send_report ##设置发生切换后发送的报警脚本
secondary_check_script= /usr/bin/masterha_secondary_check -s server3 -s server2 ###除了manager,其他的随便写,但是一定要有解析,在本机做解析
#shutdown_script=""
ssh_user=root

[server1]
hostname=172.25.17.1
port=3306
candidate_master=1 ##master坏了,1成为主机,延迟为0秒设置为候选master,如果设置了该参数之后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中的时间最新的slave
check_repl_delay=0
[server2]
hostname=172.25.17.2
port=3306
[server3]
hostname=172.25.17.3
port=3306

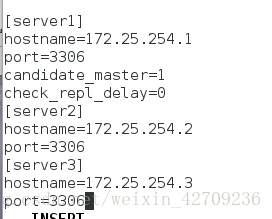
ll /usr/bin/masterha_secondary_check ##看显不显示这个文件
masterha_check_ssh --help ##会显示怎么做
masterha_check_ssh --conf=/etc/masterha/app1.cnf ##会报错
cd
ssh-keygen ##获取一个钥匙
cd .ssh/
ls ##有三个文件
ssh-copy-id 172.25.17.4 ##看能不能发送过去不能的话,就要在server1,server2,server3里面删除 .ssh
在server1和server2和server3里面做
rm -fr .ssh
在server4里面做
cd
scp -r .ssh/ server1: #有4个文件才是对的,主要是时有authorized_keys
scp -r .ssh/ server2:
scp -r .ssh/ server3:
###验证有没有正确
在server1和server2和server3
cd .ssh
ls ##显示有没有文件传过来
在server4里面做
ssh server4 ssh server3 ssh server2 ssh server1 #不用输入密码,直接可以进去,则视为正确,记得一定要退出来
在server1 server3 server2 server1分别做上面的测试,看正不正确
在server4里面做
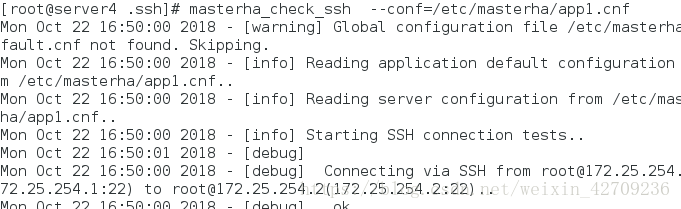
masterha_check_ssh --conf=/etc/masterha/app1.cnf ##应该不会报错
masterha_check_repl --conf=/etc/masterha/app1.cnf ##回报错
去主机里面做
mysql -p
grant all on *.* to root@'%' identified by 'Wb@123456';
grant replication slave on *.* to repl@'%' identified by 'Wb@123456';
在server4里面做
masterha_check_repl --conf=/etc/masterha/app1.cnf ##不会报错在做下面的
nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover &
ls
cd /etc/masterha/
ls ##有三个文件
cat app1.master_status.health

测试:
在主master里面插入数据,在从里边看有没有同步过去

sever1的
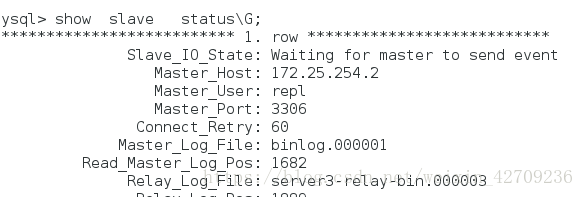
server3的
在master挂掉,看能不能同步过去
ps ax
kill -9 ###进程号

server2的
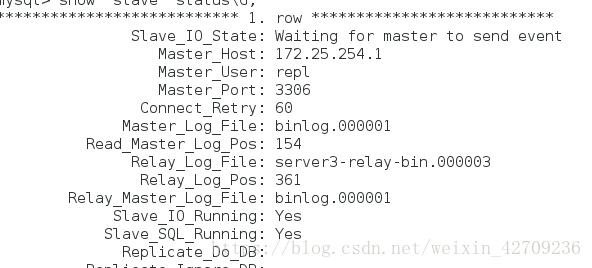
server3的
####如果想再次变化的话,记得一定要重复下面的操作
masterha_check_ssh --conf=/etc/masterha/app1.cnf
masterha_check_repl --conf=/etc/masterha/app1.cnf
nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover & ####重新开启服务,让其读你更改的内容,否则master转换失败
手动完成在线主从节点切换:
root@server1 ~]# masterha_master_switch --conf=/etc/masterha/app1.conf--master_state=alive --new_master_host=172.25.254.2 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=1000

nohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover & ####重新开启服务,让其读你更改的内容,否则master转换失败
故障切换:
root@server1 ~]#masterha_master_switch --conf=/etc/masterha/app1.conf--master_state=dead --dead_master_host=172.25.254.1 --dead_master_port=3306 --new_master_host=172.25.254.2 --new_master_port=3306 --ignore_last_failovernohup masterha_manager --conf=/etc/masterha/app1.cnf --ignore_last_failover & ####重新开启服务,让其读你更改的内容,否则master转换失败