一首先是主从复制的状态,或者半同步:
!!清空环境(之前做的组复制)
关闭数据库,删除/var/lib/mysql/*,重新启动初始化,统一修改密码为Westos+007
host1 : matser (node1)
host2: master-slave(node2)
host3: master-salve(node3)
host4: mha-manager
HOST1配置文件
vim /etc/my.cnf
server-id=1
log-bin=mysql-bin
gtid_mode=ON
enforce_gtid_consistency=ON
/etc/init.d/mysqld restart
host2和host3除了server-id不同其他一样
别忘记重启服务
/etc/init.d/mysql restart接下来主从复制配置
1.Host1数据库操作
##grep "temporary password" /var/log/mysqld.log
##mysql_secure_installation
mysql> alter user root@localhost identified by 'Westos+007';
mysql> flush privileges;
mysql> grant replication slave on *.* to repl@'%' identified by 'Westos+007';
mysql> show master status;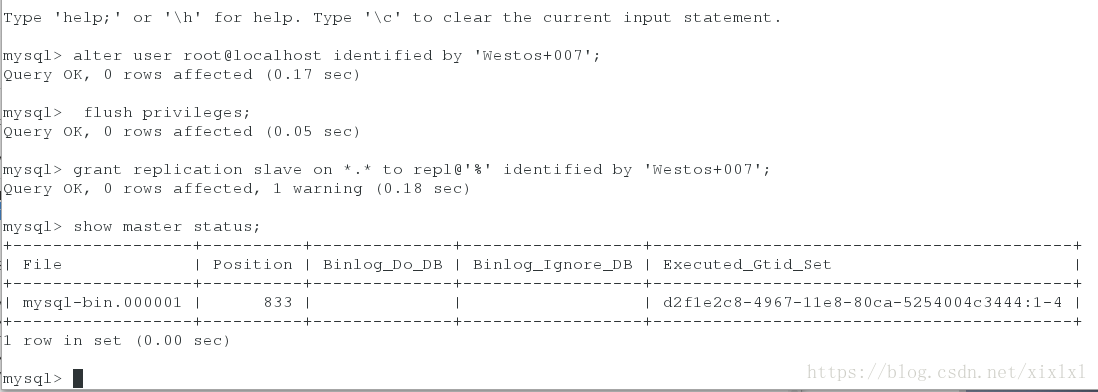
2.Host2数据库操作
##grep "temporary password" /var/log/mysqld.log
mysql -p
mysql> alter user root@localhost identified by 'Westos+007';
mysql> change master to master_host='172.25.254.1',master_user='repl',master_password='Westos+007',master_auto_position=1;
mysql> start slave;
mysql> show slave status\G;注意查看host2的io和sql线程
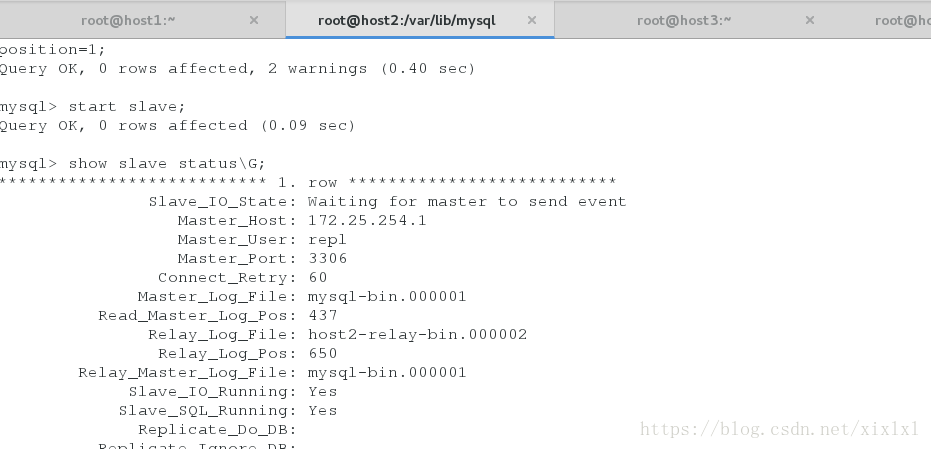
3.Host3数据库操作
##grep "temporary password" /var/log/mysqld.log
mysql> alter user root@localhost identified by 'Westos+007';
mysql> change master to master_host='172.25.254.1',master_user='repl',master_password='Westos+007',master_auto_position=1;
mysql> start slave;
mysql> show slave status\G;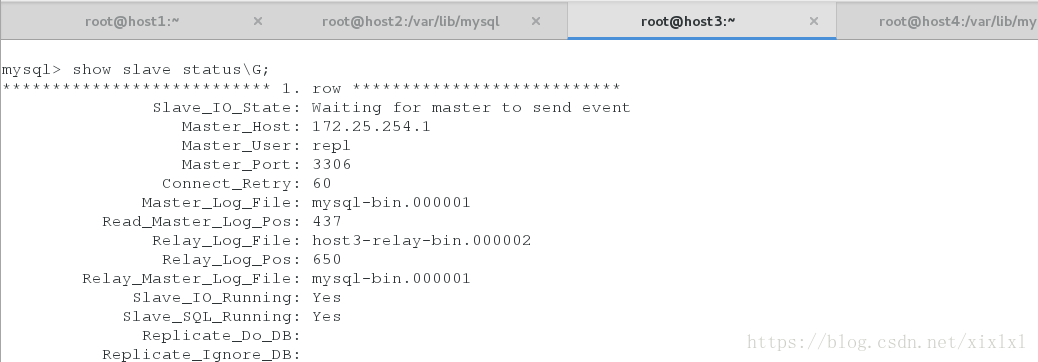
官网是半同步下的高可用,非必要:这采取半同步下的高可用,
Host1
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
mysql> set global rpl_semi_sync_master_enabled=on;
mysql> set global rpl_semi_sync_slave_enabled=on;
mysql> show variables like '%rpl_semi%';写入文件:
vim /etc/my.cnf
server-id=1
log-bin=mysql-bin
gtid_mode=ON
enforce_gtid_consistency=ON
rpl_semi_sync_master_enable=1
rpl_semi_sync_slave_enable=1
host2和host3操作相同
最终效果:再host1中建host1数据库,host2和host3同步了
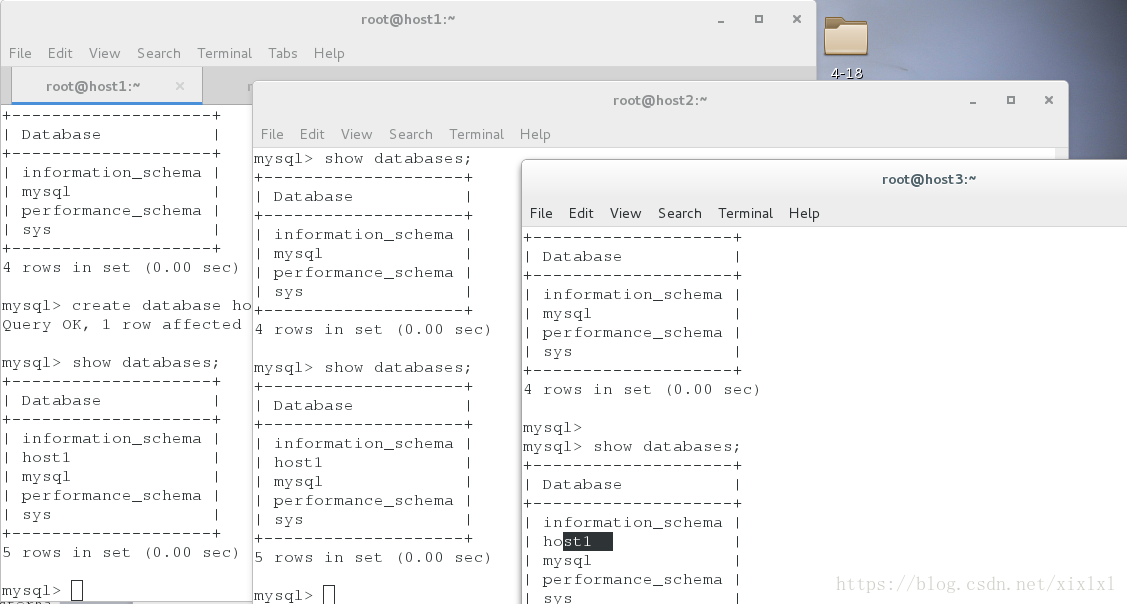
三台mysql主机设置开机自启动
chkconfig mysqld on高可用
1.关于Mha
MHA是一款开源的mysql的高可用程序,它为mysql主从复制架构了,master down掉之后,从slave中产生新的master的功能,MHA在监控到master数据节点服务器故障时,会提升其中拥有最新的数据的slave成为新的master。MHA主句节点和MHA管理节点,MHA Manager通常单独部署在一台服务器上,MHA Node通常在每台mysql服务器上;(1)把某一个slave节点提升为master节点;(2)在提升之前,会把所有其他slave节点记录的所有数据合并到要提升为主节点(master)的那个(slave)从节点上。
2.Mha组件
(1)Manager节点
masterha_check_ssh: MHA依赖ssh环境检测工具
masterha_check_repl: mysql复制环境检测工具
masterha_manager: MHA服务主程序
masterha_check_status:MHA运行状态探测工具
masterha_check_monitor: mysql master节点可用性检测工具
masterha_check_switch:master节点切换工具
masterha_conf_host:添加或删除配置节点
masterha_stop:关闭MHA服务
(2)Node节点
save_binary_logs: 保存和复制master的二进制日志
apply_diff_relay_logs:识别差异的中继日志事件并应用与其他slave
filter_mysqlbinlog:去除不必要的rollback事件
purge_relay_logs:清除中继日志(不会阻塞sql线程)
实验环境,关闭iptables,开机不启动,selinux=disabled
一.node节点配置Host1,host2,host3
安装mha4mysql-node-0.56-0.el6.noarch.rpm
[root@host1 ~]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@host2 ~]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@host3 ~]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -yRpm安装解决依赖安装perl-CPAN.x86_64,perl-DBD-MySQL.x86_64,perl-devel.x86_64
二.管理节点Host4管理节点:
安装 mha4mysql-node-0.56-0.el6.noarch.rpm -y
yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y安装mha4mysql-manager-0.56-0.el6.noarch.rpm 之前要解决依赖
yum install
perl-Log-Dispatch-2.27-1.el6.noarch.rpm
perl-Mail-Sender-0.8.16-3.el6.noarch.rpm
perl-Mail-Sendmail-0.79-12.el6.noarch.rpm
perl-MIME-Lite-3.027-2.el6.noarch.rpm
perl-MIME-Types-1.28-2.el6.noarch.rpm
perl-Parallel-ForkManager-0.7.9-1.el6.noarch.rpm
perl-Config-Tiny-2.12-7.1.el6.noarch.rpm
perl-Email-Date-Format-1.002-5.el6.noarch.rpm
依赖解决后
yum install mha4mysql-manager-0.56-0.el6.noarch.rpm 如果用rpm安装还要安装 perl-Time-HiRes.x86_64这个依赖包
三.配置管理节点目录
1.配置MHA manger(host4)目录
mkdir /etc/mhamanger/ -p2.编辑配置文件
Vim /etc/mhamanger/app.conf
1 [server default]
2 manager_workdir=/etc/mhamanger/ ##mha主配值目录
3 manager_log=/etc/mhamanger/mha.log ##日志
4 master_binlog_dir= /var/lib/mysql ##二进制日志存放位置
5 remote_workdir=/tmp
6 master_ip_failover_script= /etc/mhamanger/master_ip_failover
7 #shutdown_script= /etc/mhamanger/power_manager
8 #report_script= /etc/masterha/send_report
9 master_ip_online_change_script= /script/masterha/master_ip_online_change
10
11 password=Westos+007 ##监控数据库密码
12 user=root ##监控数据库用户
13 ping_interval=1
14
15 repl_password=Westos+007 ##数据库授权密码
16 repl_user=repl ##数据库授权用户
17
18 ssh_user=root #ssh用户
19
20 [server1] ##1为master
21 hostname=172.25.254.1
22 port=3306
23 #candidate_master=1
24 #check_repl_delay=0
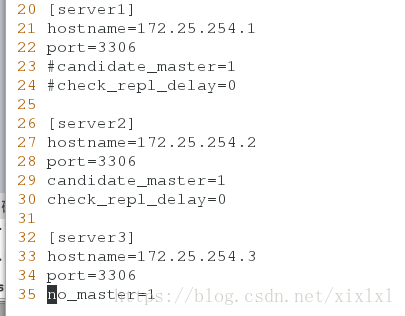
25
26 [server2]
27 hostname=172.25.254.2
28 port=3306
29 candidate_master=1 ##1主挂了自己为主
30 check_repl_delay=0
31
32 [server3]
33 hostname=172.25.254.3
34 port=3306
35 no_master=1 ##自己永不能为主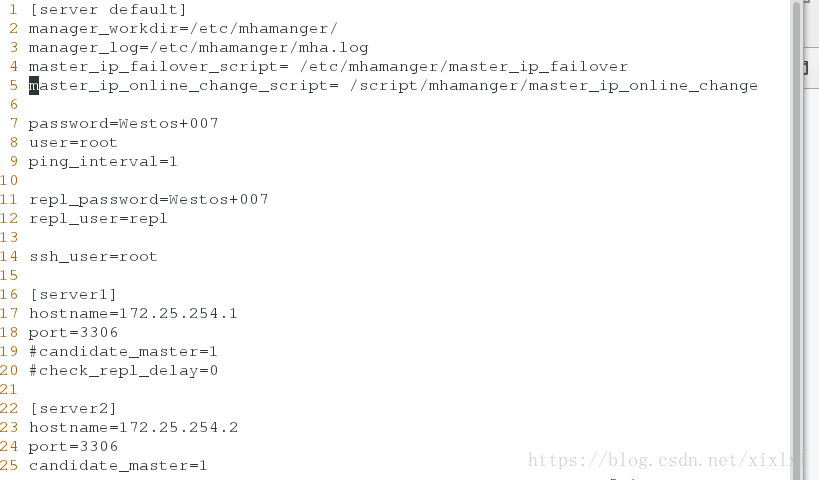
4ssh互相通信
Host4操作
ssh-keygen
cd /root/.ssh
ssh-copy-id host4
scp -rp /root/.ssh/ host1:~
scp -rp /root/.ssh/ host2:~
scp -rp /root/.ssh/ host3:~
检验:出现All SSH connection tests passed successfully.表示成功
masterha_check_ssh --conf=/etc/mhamanger/app.conf 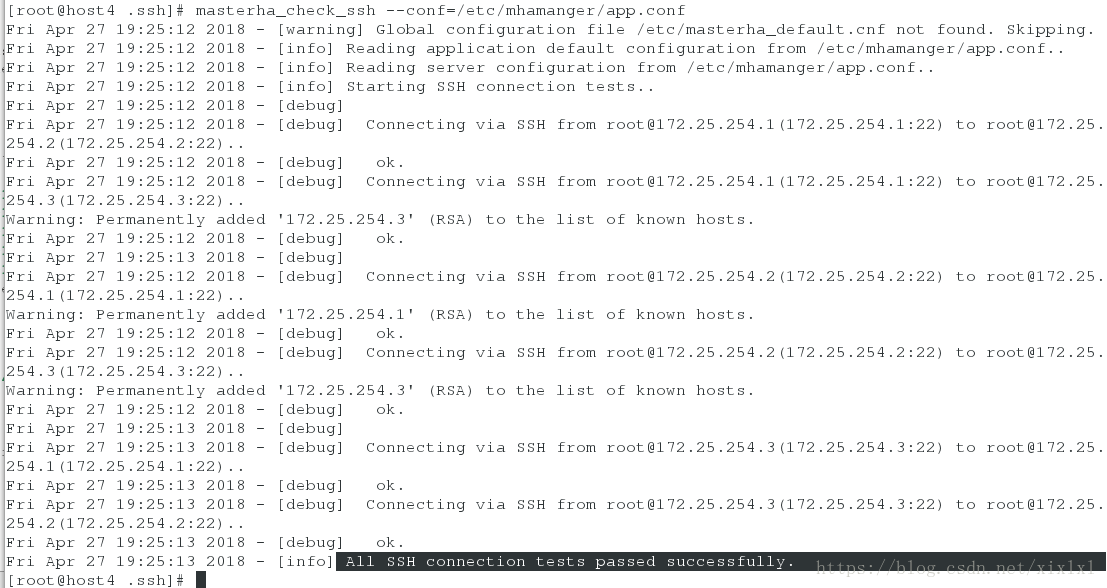
5数据库授权
1.host1数据库操作
grant replication slave on *.* to repl@'%' identified by 'Westos+007';
Host4检查MySQL Replication Health is OK. 表示好了
masterha_check_repl --conf=/etc/mhamanger/app.conf 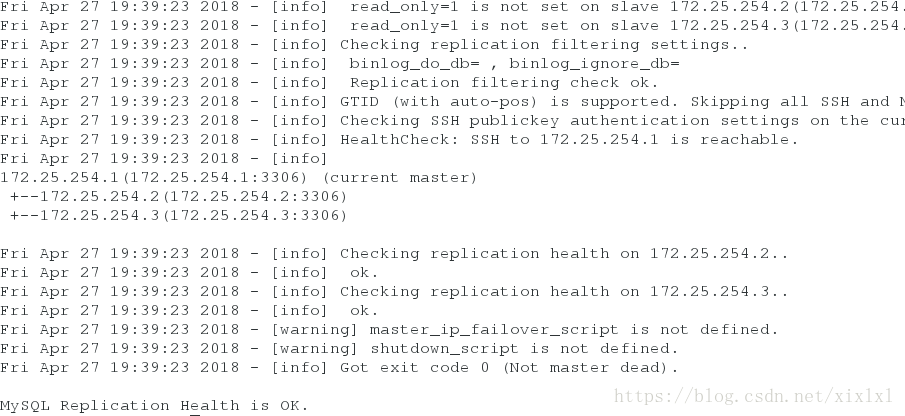
开启mha服务
nohup masterha_manager
--conf=/etc/mhamanger/application/app.conf >/etc/mhamanger/mha.log 2>&1 & ##开启mha服务
masterha_check_status --conf=/etc/mhamanger/app.conf 查看mha状态 
6.再master(host1)上设置vip ,和脚本里的相同
ip addr add 172.25.254.111/24 dev eth0
ip addr
7从加目录中把三个脚本移动到/etc/mhamanger/下
[root@host4 ~]# cp master_ip_failover master_ip_online_change send_report /etc/mhamanger/
cd /etc/mhamanger/
chmod +x master_ip_failover master_ip_online_change send_report 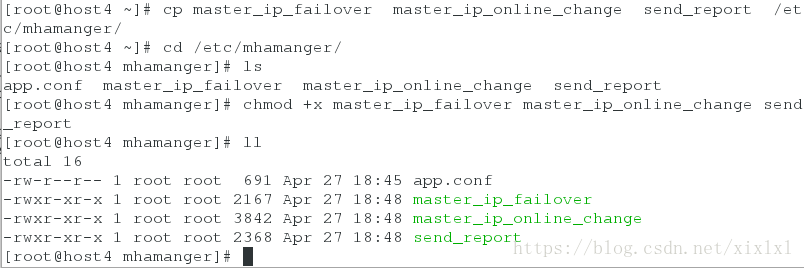
Vim /etc/mhamanger/master_ip_failover
11 my $vip = '172.25.254.111/24';
12 my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
13 my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";
vim /etc/mhamanger/master_ip_online_change
7 my $vip = '172.25.254.111/24'; # Virtual IP
8 my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
9 my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";客户端通过vip可以登陆数据库

实验:down掉master(host1)
killall mysqld_safe mysqld ##注意得先关闭mysqld_safe进程
Host2为主了,vip自动转移到了host2(新的master)上客户端访问vip依旧可以访问数据库,
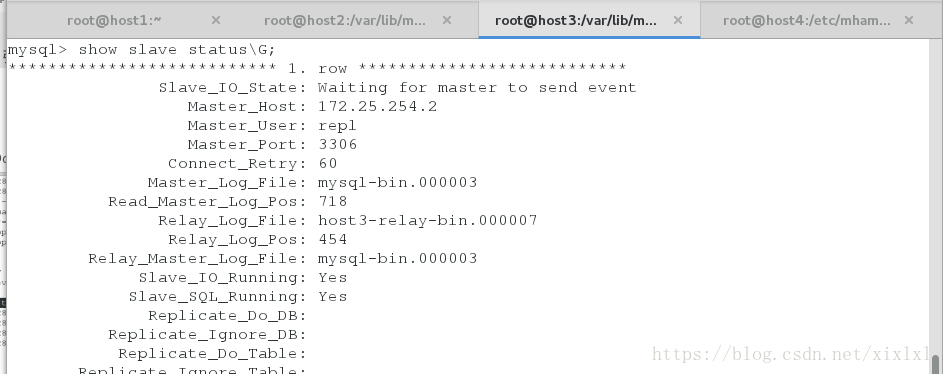
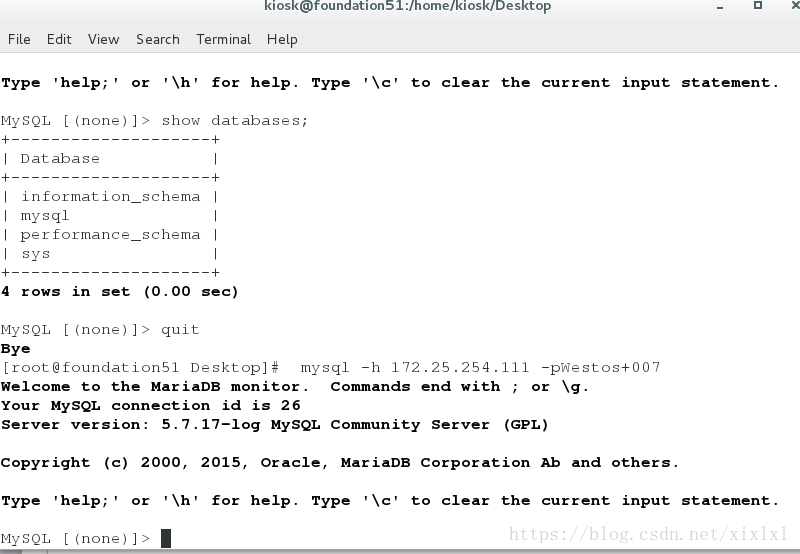
vip查看
这个时候,MHA是无法启动的:修复host1节点,编辑msql配置文件,加入下边两行,重启后,进入数据库指定master节点
vim /etc/my.cnf
read-only = 1 ##hostmysql只读
relay-log-purge = 0 ##不清除realy-log指定master节点:其中master_log_file和master_log_pos到master中查看。
change master to master_host='172.25.254.2',master_user='repl',master_password='Westos+007',master_log_file='mysql-bin.000003',master_log_pos=718;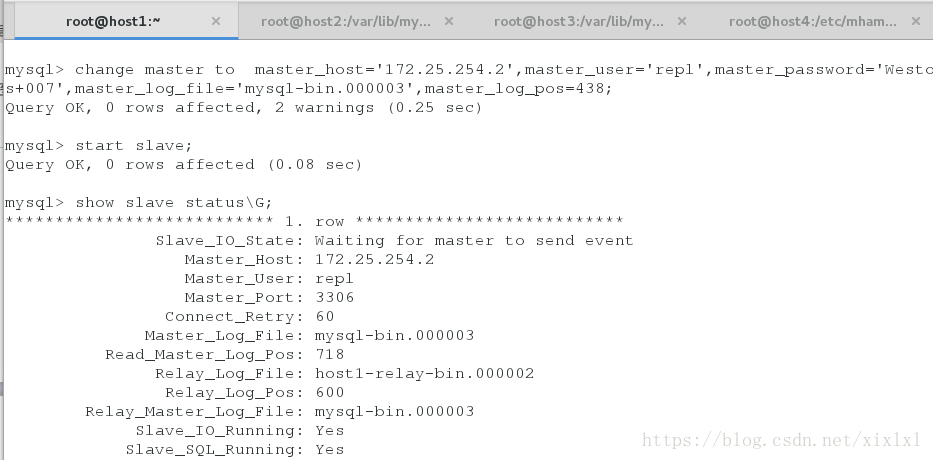
查看日志信息
cat /etc/mhamanger/mha.log 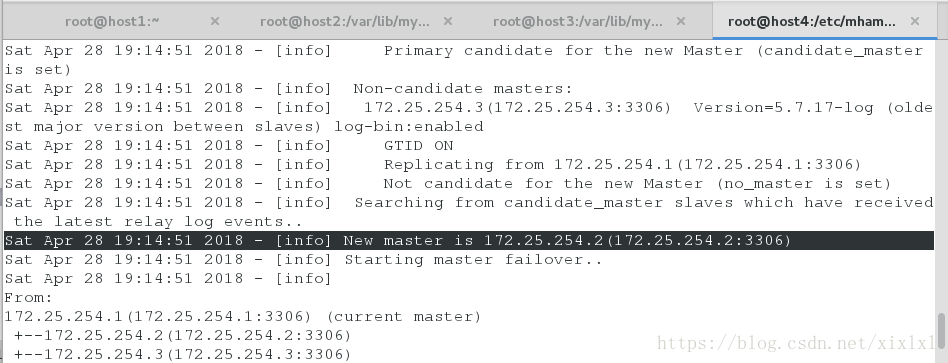
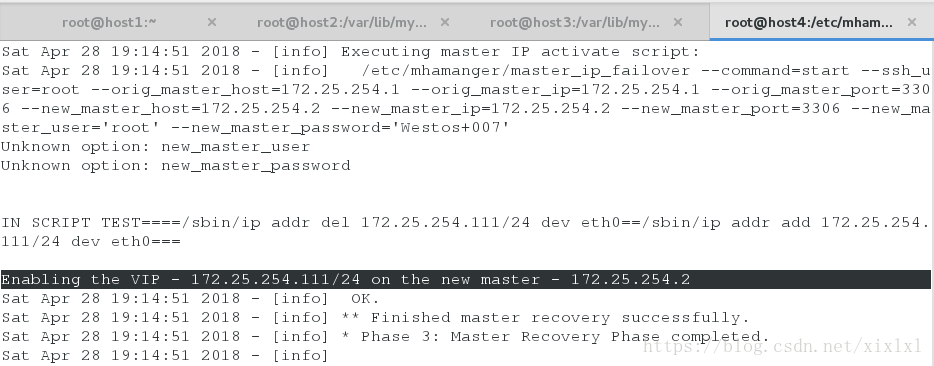
热切换就是再master没有down掉的情况下更改master,冷切换相反;
热切换参考命令:
masterha_master_switch --conf=/配置文件绝对路径 --master_state=alive --new_master_host=[ip] --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=1000冷切换:
Mha管理节点:
masterha_master_switch --conf=/配置文件绝对路径 --master_state=dead --dead_master_host=[down掉地maste的ip] --dead_master_port=3306 --new_master_host=[要切换的master的ip] --new_master_port=3306 --ignore_last_failover发送报告:
发送报告的前提是虚拟机可以通网:
1.宿主机设置火墙规则
iptables -t nat -I POSTROUTING -s 172.25.254.0/24 -j MASQUERADE
iptables -t nat -nL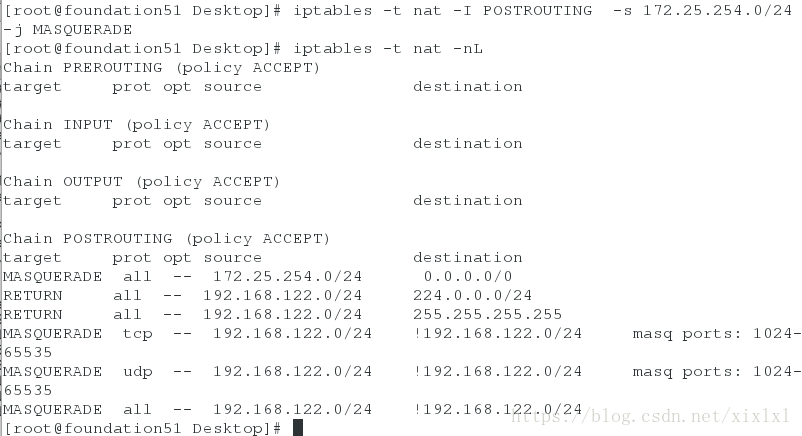
2.Mha管理节点设置路由和解析
route add default gw 172.25.254.51
echo nameserver 114.114.114.114 >> /etc/resolv.conf
ping www.baidu.com 测试下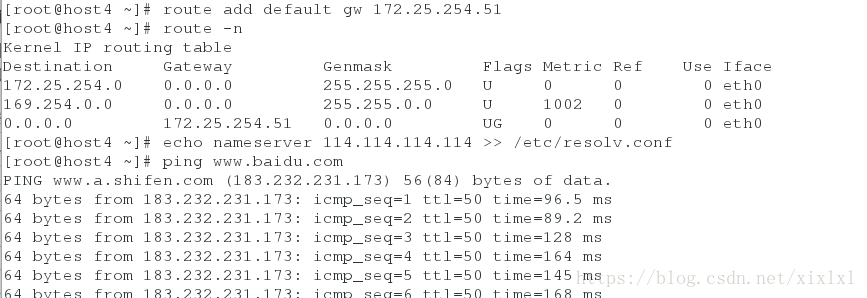
3.Mha管理节点:
修改已经准备好的perl脚本
vim /etc/mhamanger/send_report :添加邮箱信息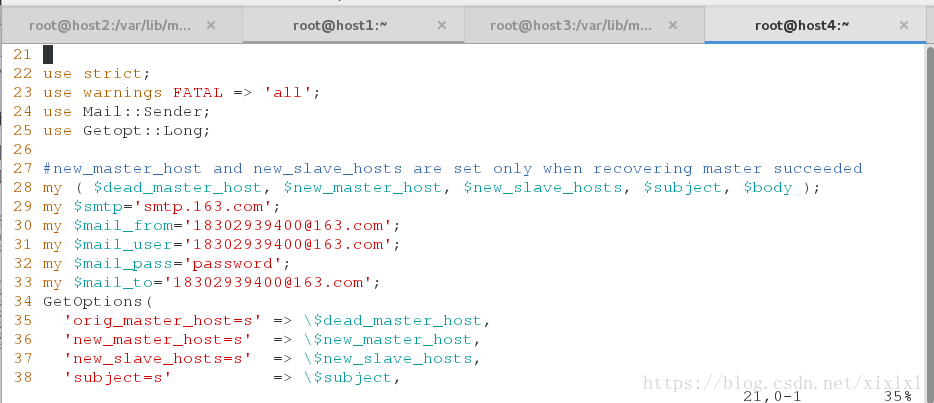
vim /etc/mhamanger/app.conf
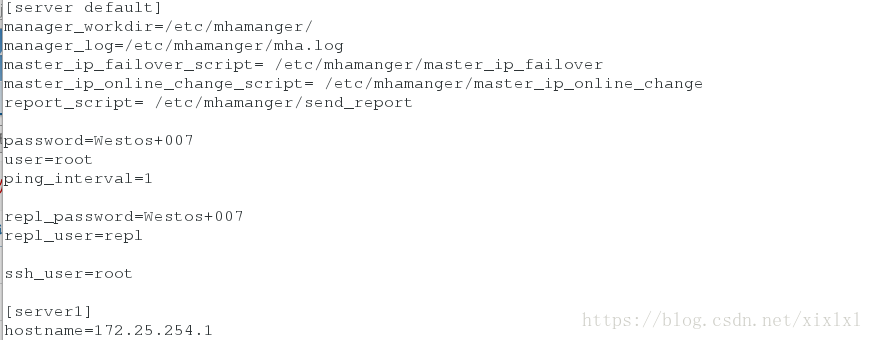
4.安装邮件服务
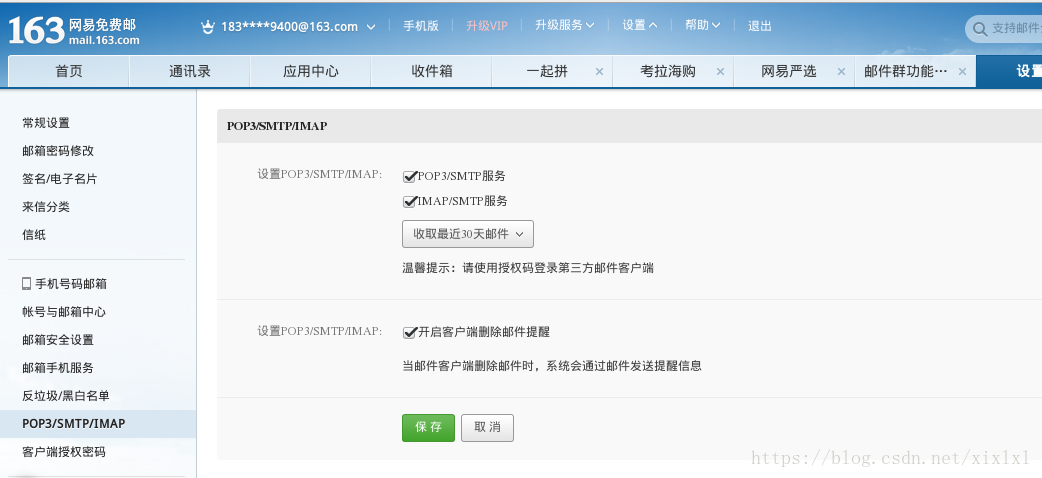
yum install mailx 5.邮箱设置
6.Masterdown掉mysql
killall -9 mysqld_safe mysqld
查看日志
cat /etc/mhamanger/mha.log :正在发送邮件
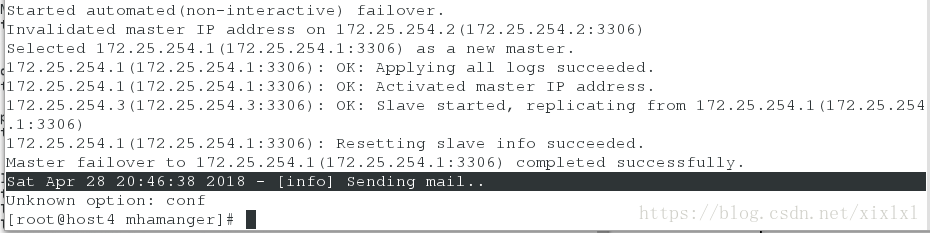
这里有点小问题,未能收到邮件