一. 找到最好的工具
“工欲善其事,必先利其器”,如果你想找一个深度学习框架来解决深度学习问题,TensorFlow 就是你的不二之选,究其原因,也不必过多解释,看过其优雅的代码架构和工程化实现之后,相信这个问题不会有人再提,这绝非 Caffe an so on 所能比拟的。
回到题头 - 目标检测,相信你一定看过这篇 Paper: Speed/accuracy trade-offs for modern convolutional object detectors, Huang J, CVPR2017
所谓 Trade-Off 是指精度和效率之间的 Trade-Off,TensorFlow 给出了该方法的具体实现:
代码下载:【Github】
二. 跑通代码
先来看页面介绍,来看 Show 出的检测效果对比(IncResnet V2 对小目标的检测效果非常不错):

三. 论文阅读
程序跑起来之后,还是有必要来读一遍论文,了解技术原理,对于代码的运用和参数调整都有很大作用。
这是一篇综述性质的论文,主要比较了 Faster R-CNN,RFCN,SSD 三种检测框架,原理示意如下:

针对每个框架,结合不同的 特征提取网络来进行整合实验,里面主要比较的网络有:VGG,Inception v3,Resnet-101,Inception Resnet 等。
Model
Top-1 accuracy
Num. Params.
VGG-16
71.0
14,714,688
MobileNet
71.1
3,191,072
Inception V2
73.9
10,173,112
ResNet-101
76.4
42,605,504
Inception V3
78.0
21,802,784
Inception Resnet V2
80.4
54,336,736
具体每个网络就不展开了,这个都比较熟悉,通过比较,我们最关心的两点,一是准确度,二是效率,直接贴出来原文的图来说明:
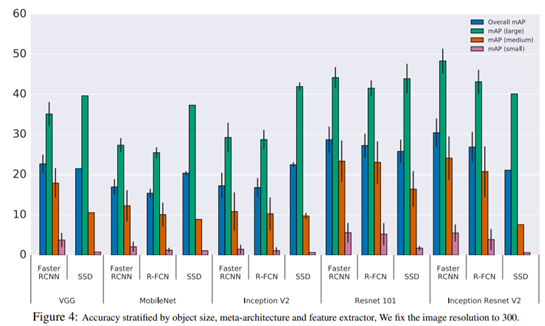
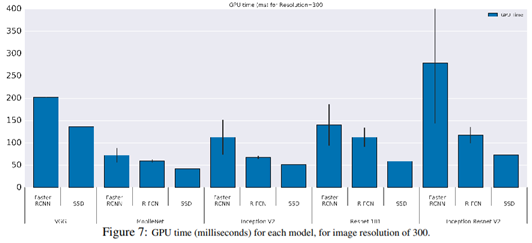
可以看到,精度最高的Faster R-CNN效率是最低的,网络复杂度最高的 Inception Resnet 带来的精度提升比较明显,同样的,用 GPU Time 衡量的计算量与 Float运算、内存容量各方面的衡量指标是类似的,这里就不再全部列出来了。
可以通过两种方式有效提高算法效率: 一是降低图像分辨率,二是减少 Proposal 数量(仅支持Faster R-CNN 和 RFCN )。
需要强调一点的是 Region Proposal 的数量,对于效率的影响会比较明显,因为Proposal数量 决定了计算量(几乎是成比例的),因此提高 Proposal的准确度,减少数量是最好的方式(最有效的提高效率)。