1.Mysql 主从复制使用场景
mysql主从复制有利于数据库结构的健壮性,提升访问速度和易于维护管理。
- 1.1.主从服务器互为备份
- 主从服务器架构的设计,可以大大的加强数据库架构的健壮性。例如:当主服务器出现问题的时候,我们可以人工或者自动的切换到从服务器继续提供服务。
- 这个类似于之前nfs存储数据通过inotify+rsync同步到备份的nfs非常的类似,只不过MySQL的同步方案,是其自带的工具。
- 1.2.主从服务器读写分离分担网站的压力:
- 主从服务器的架构可通过程序(php,java)或者代理软件(mysql-proxy,amoeba)对用户的请求实现读写分离,即通过在从服务器上仅仅处理select查询的请求,降低用户的查询时间以及读写同时在主服务器上带来的压力,对于更新的数据(update insert delete)仍然交给主服务器处理,确保主服务器和从服务器保持实时的同步,如果网站是以非更新为主的业务,如blog,www的首页展示等业务,查询的请求比较多,这是从服务器的读写分离负载均衡策略就很有效了,这就是读写分离数据结构。
2.Mysql 主从复制配置参数
2.1 主上配置参数
binlog_do_db=库名列名 //只允许同步的库
binlog_ignore_db=库名类表 //只不允许同步的库
多个库可以写成多行
1 log-bin=mysql-bin
1、控制master的是否开启binlog记录功能;
2、二进制文件最好放在单独的目录下,这不但方便优化、更方便维护。
3、重新命名二进制日志很简单,只需要修改[mysqld]里的log_bin选项,
如下例子:要重新调整logbin的路径为“/home/mysql/binlog”
[mysqld]
log_bin=/home/mysql/binlog/binlog.log
ll /home/mysql/binlog
-rw-rw---- 1 mysql mysql 98 Mar 7 17:24 binlog.000001
-rw-rw---- 1 mysql mysql 33 Mar 7 17:24 binlog.index
需要注意:指定目录时候一定要以*.log结尾,即不能仅仅指定到文件夹的级别,否则在重启mysql时会报错。
2. server-id=1
每个server服务的标识,在master/slave环境中,此变量一定要不一样
3. expire_logs_days=15
通过此来实现master自动删除binlog
4. innodb_flush_log_at_trx_commit=1
此参数表示在事务提交时,处理重做日志的方式;此变量有三个可选值0,1,2:
0:当事务提交时,并不将事务的重做日志写入日志文件,而是等待每秒刷新一次
1:当事务提交时,将重做日志缓存的内容同步写到磁盘日志文件,为了保证数据一致性,在replication环境中使用此值。
2:当事务提交时,将重做日志缓存的内容异步写到磁盘日志文件(写到文件系统缓存中)
建议必须设置innodb_flush_log_at_trx_commit=1
5.sync_binlog=1
1、此参数表示每写缓冲多少次就同步到磁盘;
2、sync_binlog=1表示同步写缓冲和磁盘二进制日志文件,不使用文件系统缓存
在使用innodb事务引擎时,在复制环境中,为了保证最大的可用性,都设置为“1”,但会对影响io的性能。
3、即使设置为“1”,也会有问题发生:
假如当二进制日志写入磁盘,但事务还没有commit,这个时候宕机,
当服务再次起来的恢复的时候,无法回滚以及记录到二进制日志的未提交的内容;
这个时候就会造成master和slave数据不一致
解决方案:
需要参数innodb_support_xa=1来保证。建议必须设置
6 .innodb_support_xa=1
此参数与XA事务有关,它保证了二进制日志和innodb数据文件的同步,保证复制环境中数据一致性。建议必须设置
7.binlog-do-db=skate_db
只记录指定数据库的更新到二进制日志中
8. binlog-do-table=skate_tab
只记录指定表的更新到二进制日志中
9. binlog-ignore-db=skate_db
忽略指定数据库的更新到二进制日志中
10.log_slave_updates=1
此参数控制slave数据库是否把从master接受到的log并在本slave执行的内容记录到slave的二进制日志中
在级联复制环境中(包括双master环境),这个参数是必须的
11.binlog_format=statement|row|mixed
控制以什么格式记录二进制日志的内容,默认是mixed
12. max_binlog_size
master的每个二进制日志文件的大小,默认1G
13.binlog_cache_size
1、所有未提交的事务都会被记录到一个缓存或临时文件中,待提交时,统一同步到二进制日志中,
2、此变量是基于session的,每个会话开启一个binlog_cache_size大小的缓存。
3、通过变量“Binlog_cache_disk_use”和“Binlog_cache_use”来设置binlog_cache_size的大小。
说明:
Binlog_cache_disk_use: 使用临时文件写二进制日志的次数
Binlog_cache_use: 使用缓冲记写二进制的次数
14.auto_increment_increment=2 //增长的步长
auto_increment_offset=1 //起始位置
在双master环境下可以防止键值冲突2.2 从上配置参数
replicate_do_db=库名列表 //只同步的库
replicate_ignore_db=库名列表 //只不同步的库
多个库可以写成多行
1.server-id=2
和master的含义一样,服务标识
2.log-bin=mysql-bin
和master的含义一样,开启二进制
3.relay-log=relay-bin
中继日志文件的路径名称
4. relay-log-index=relay-bin
中继日志索引文件的路径名称
5. log_slave_updates=1
和master的含义一样,如上
6.read_only=1
1、使数据库只读,此参数在slave的复制环境和具有super权限的用户不起作用,
2、对于复制环境设置read_only=1非常有用,它可以保证slave只接受master的更新,而不接受client的更新。
3、客户端设置:
mysq> set global read_only=1
7. skip_slave_start
使slave在mysql启动时不启动复制进程,mysql起来之后使用 start slave启动,建议必须
8.replicate-do-db
只复制指定db
9.replicate-do-table
只复制指定表
10. replicate-ingore-table
忽略指定表
11. replicate_wild_do_table=skatedb.%
模糊匹配复制指定db
12. auto_increment_increment=2
auto_increment_offset=1
和master含义一样,参考如上
13. log_slow_slave_statements
在slave上开启慢查询日志,在query的时间大于long_query_time时,记录在慢查询日志里
14. max_relay_log_size
slave上的relay log的大小,默认是1G
15.relay_log_info_file
中继日志状态信息文件的路径名称
16. relay_log_purge
当relay log不被需要时就删除,默认是on
SET GLOBAL relay_log_purge=1
17.replicate-rewrite-db=from_name->to_name
数据库的重定向,可以把分库汇总到主库便于统计分析
3.binlog的三种模式
binlog模式分三种(row,statement,mixed)
3.1.Row
日志中会记录成每一行数据被修改的形式,然后在slave端再对相同的数据进行修改,只记录要修改的数据,只有value,不会有sql多表关联的情况。
优点:在row模式下,bin-log中可以不记录执行的sql语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了,所以row的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程和function,以及trigger的调用和出发无法被正确复制问题。
缺点:在row模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容。
row模式是针对每一行的数据,而于关联表无关,它把关联中的相应数据记录在log中。这样一来会产生大量的数据。
3.2.statement
每一条会修改数据的sql都会记录到master的binlog中,slave在复制的时候sql进程会解析成和原来master端执行多相同的sql再执行。
优点:在statement模式下首先就是解决了row模式的缺点,不需要记录每一行数据的变化减少了binlog日志量,节省了I/O以及存储资源,提高性能。因为他只需要记录在master上所执行的语句的细节以及执行语句的上下文信息。
缺点:在statement模式下,由于他是记录的执行语句,所以,为了让这些语句在slave端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在slave端被执行的时候能够得到和在master端执行时候相同的结果。另外就是,由于mysql现在发展比较快,很多的新功能不断的加入,使mysql的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug也就越容易出现。在statement中,目前已经发现不少情况会造成Mysql的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep()函数在有些版本中就不能被正确复制,在存储过程中使用了last_insert_id()函数,可能会使slave和master上得到不一致的id等等。由于row是基于每一行来记录的变化,所以不会出现,类似的问题。
statement是以sql记录形式记录的。这样的话一个sql就只记录一条,减少了大量的数据存储。
3.3 Mixed
从官方文档中看到,之前的 MySQL 一直都只有基于 statement 的复制模式,直到 5.1.5 版本的 MySQL 才开始支持 row 复制。从 5.0 开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL Replication 又带来了更大的新挑战。另外,看到官方文档说,从 5.1.8 版本开始,MySQL 提供了除 Statement 和 Row 之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在 Mixed 模式下,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。新版本中的 statment 还是和以前一样,仅仅记录执行的语句。而新版本的 MySQL 中对 row 模式也被做了优化,并不是所有的修改都会以 row 模式来记录,比如遇到表结构变更的时候就会以 statement 模式来记录,如果 SQL 语句确实就是 update 或者 delete 等修改数据的语句,那么还是会记录所有行的变更。
4.Mycat
4.1 Mycat原理
Mycat的原理并不复杂,复杂的是代码,如果代码也不复杂,那么早就成为一个传说了。
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分
片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再
返回给用户。
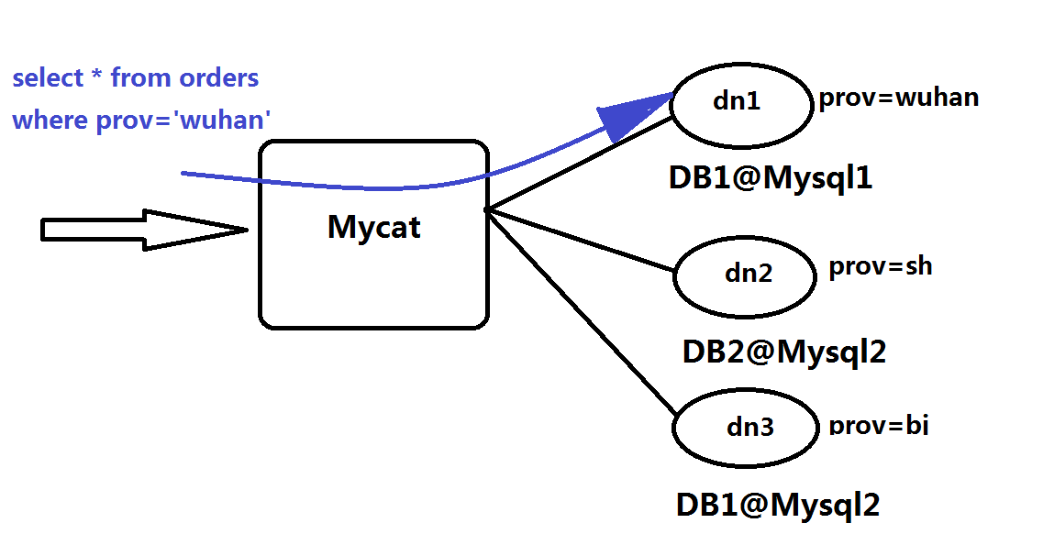
上述图片里,Orders表被分为三个分片datanode(简称dn),这三个分片是分布在两台MySQL Server上(DataHost),即
datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举
分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字
符串枚举方式。
当Mycat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字
段的值,并匹配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果
数据,并输出到客户端。以select * from Orders where prov=?语句为例,查到prov=wuhan,按照分片函数,wuhan返回
dn1,于是SQL就发给了MySQL1,去取DB1上的查询结果,并返回给用户。
如果上述SQL改为select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL就会发给MySQL1与MySQL2去
执行,然后结果集合并后输出给用户。但通常业务中我们的SQL会有Order By 以及Limit翻页语法,此时就涉及到结果集在
Mycat端的二次处理,这部分的代码也比较复杂,而最复杂的则属两个表的Jion问题,为此,Mycat提出了创新性的ER分片、全
局表、HBT(Human Brain Tech)人工智能的Catlet、以及结合Storm/Spark引擎等十八般武艺的解决办法,从而成为目前业界
最强大的方案,这就是开源的力量!
4.2应用场景
Mycat发展到现在,适用的场景已经很丰富,而且不断有新用户给出新的创新性的方案,以下是几个典型的应用场景:
单纯的读写分离,此时配置最为简单,支持读写分离,主从切换分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化
报表系统,借助于Mycat的分表能力,处理大规模报表的统计替代Hbase,分析大数据作为海量数据实时查询的一种简单有效方案,比如100亿条频繁查询的记录需要在3秒内查询出来结果,除了基于主键的查询,还可能存在范围查询或其他属性查询,此时Mycat可能是最简单有效的选择
Mycat长期路线图
强化分布式数据库中间件的方面的功能,使之具备丰富的插件、强大的数据库智能优化功能、全面的系统监控能力、以及方
便的数据运维工具,实现在线数据扩容、迁移等高级功能
进一步挺进大数据计算领域,深度结合Spark Stream和Storm等分布式实时流引擎,能够完成快速的巨表关联、排序、分组
聚合等 OLAP方向的能力,并集成一些热门常用的实时分析算法,让工程师以及DBA们更容易用Mycat实现一些高级数据分
析处理功能。
不断强化Mycat开源社区的技术水平,吸引更多的IT技术专家,使得Mycat社区成为中国的Apache,并将Mycat推到Apache
基金会,成为国内顶尖开源项目,最终能够让一部分志愿者成为专职的Mycat开发者,荣耀跟实力一起提升。
依托Mycat社区,聚集100个CXO级别的精英,众筹建设亲亲山庄,Mycat社区+亲亲山庄=中国最大IT O2O社区
5. Mysql架构
5.1MySQL双主(主主)架构方案思路是:
1.两台mysql都可读写,互为主备,默认只使用一台(masterA)负责数据的写入,另一台(masterB)备用;
2.masterA是masterB的主库,masterB又是masterA的主库,它们互为主从;
3.两台主库之间做高可用,可以采用keepalived等方案(使用VIP对外提供服务);
4.所有提供服务的从服务器与masterB进行主从同步(双主多从);
5.建议采用高可用策略的时候,masterA或masterB均不因宕机恢复后而抢占VIP(非抢占模式);
这样做可以在一定程度上保证主库的高可用,在一台主库down掉之后,可以在极短的时间内切换到另一台主库上(尽可能减少主库宕机对业务造成的影响),减少了主从同步给线上主库带来的压力;
但是也有几个不足的地方:
1.masterB可能会一直处于空闲状态(可以用它当从库,负责部分查询);
2.主库后面提供服务的从库要等masterB先同步完了数据后才能去masterB上去同步数据,这样可能会造成一定程度的同步延时;
5.2 MySQL高可用架构之MHA
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
我们自己使用其实也可以使用1主1从,但是master主机宕机后无法切换,以及无法补全binlog。master的mysqld进程crash后,还是可以切换成功,以及补全binlog的。

(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
5.3 Mysql 一主多从
在有些应用场景中,可能读写压力差别比较大,读压力特别的大,一个Master可能需要上10台甚至更多的Slave才能够支撑注读的压力。这时候,Master就会比较吃力了,因为仅仅连上来的SlaveIO线程就比较多了,这样写的压力稍微大一点的时候,Master端因为复制就会消耗较多的资源,很容易造成复制的延时。
遇到这种情况如何解决呢?这时候我们就可以利用MySQL可以在Slave端记录复制所产生变更的BinaryLog信息的功能,也就是打开—log-slave-update选项。然后,通过二级(或者是更多级别)复制来减少Master端因为复制所带来的压力。也就是说,我们首先通过少数几台MySQL从Master来进行复制,这几台机器我们姑且称之为第一级Slave集群,然后其他的Slave再从第一级Slave集群来进行复制。从第一级Slave进行复制的Slave,我称之为第二级Slave集群。如果有需要,我们可以继续往下增加更多层次的复制。这样,我们很容易就控制了每一台MySQL上面所附属Slave的数量。这种架构我称之为Master-Slaves-Slaves架构
这种多层级联复制的架构,很容易就解决了Master端因为附属Slave太多而成为瓶颈的风险。下图展示了多层级联复制的Replication架构。
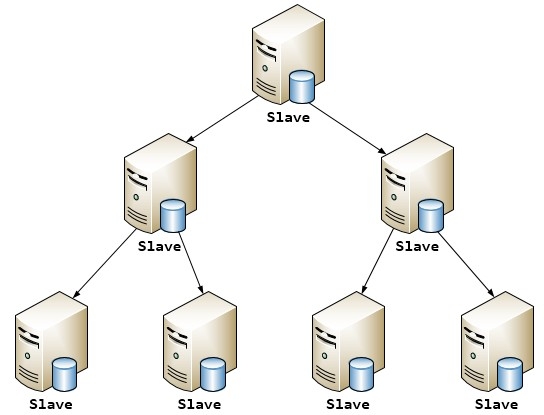
上述瓶颈问题。毕竟Slave并没有减少写的量,所有Slave实际上仍然还是应用了所有的数据变更操作,没有减少任何写IO。相反,Slave越多,整个集群的写IO总量也就会越多,我们没有非常明显的感觉,仅仅只是因为分散到了多台机器上面,所以不是很容易表现出来。
此外,增加复制的级联层次,同一个变更传到最底层的Slave所需要经过的MySQL也会更多,同样可能造成延时较长的风险。而如果我们通过分拆集群的方式来解决的话,可能就会要好很多了,当然,分拆集群也需要更复杂的技术和更复杂的应用系统架构。
6.不停库不锁表在线主从配置
可以参考这个文章