(1)基本概念
1.深度学习是用来干啥的,可以理解为自动提取特征。
特征:训练样本的描述
2.高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表现语义或者意图。
我们在第一层卷积层得到的是各物体边缘特征,(接着pooling),第二个卷积层可能就得到边缘的组合或者小猫的部位碎片,...到最后就会得到诸如爪子呀,眼睛之类的高层特征啦。并不需要像之前的全连接的结构,因为大量图片物体识别起来参数会相当多。( 所谓:仿视觉皮层(多层),局部特征组合与抽象。)
(2)CNN之所以能识别图像的直观理解(卷积实现特征提取的原理)
核心是卷积(滤波器的概念)。
如输入的是一个32×32×3的系列像素值,(不懂参见上一篇哈),滤波器相当于人的眼睛,来提取图像的底层特征,比如滤波器大小是5×5×3的,被这个小眼睛看到的地方称作接受场或者局部感受野,所以我们的这个小眼睛需要不断的移动,对应卷积下图。
(如下图所示:左图为全连接,右图为局部连接)

这样进行相应卷积运算(点乘再相加)就得到了一个feature map。如你想的那样我们往往需要多个滤波器,来从不同视角看物体,得到多个feature map。那为什么这样就得到物体的底层特征了呢?比如说边缘特征?
滤波器着实神奇,其实你可以想象过滤器是矩阵。都是数字,然后和输入的局部像素值相乘相加得到最终的结果。如果过滤器中大的参数值刚好摆出某一个形状,而物体中刚好也有这样的形状的话,是不是更加强效果啦?看下图就立马明白:

这是一个可以检测曲线的滤波器。
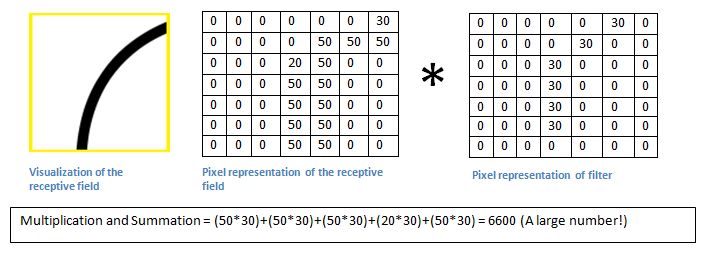
(这里是矩阵的点乘,矩阵的内积,对应数据相乘,结果求和。)
基本上在输入图像中,如果有一个形状是类似于这种滤波器的代表曲线,那么所有的乘积累加在一起会导致较大的值!现在让我们看看当我们移动我们的过滤器时会发生什么。可以看到结果值是0哦,为什么?还不明白么,因为耳朵的边缘和刚刚尾股部曲线太不同了。
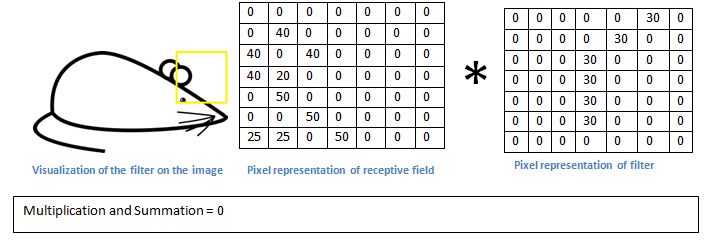
这样的多个滤波器就可以在大量数据的训练下得到大量特征了不是。训练就是为了得到合适的滤波器的值,权值偏置等。自动进行特征学习就是这个道理。卷积其实就是要卷积的区域和卷积核的点乘和,加上偏置之后的激活输出。
(3)卷积神经网络的结构 参考:卷积神经网络概念与原理
1. 神经网络
神经网络的每个单元(单个神经元)如下:
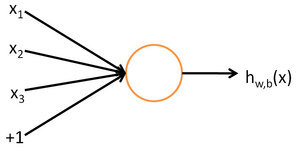
其对应的公式如下: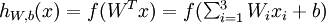
具有一个隐含层的神经网络:
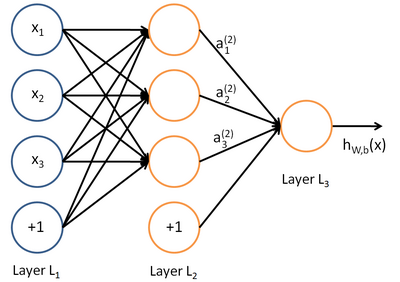
其对应的公式如下:
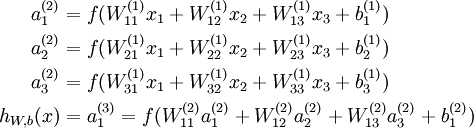
比较类似的,可以拓展到有2,3,4,5,…个隐含层。
神经网络的训练方法也同Logistic类似,不过由于其多层性,还需要利用链式求导法则对隐含层的节点进行求导,即梯度下降+链式求导法则,专业名称为反向传播。关于训练算法,本文暂不涉及。
2. 卷积神经网络
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。卷积神经网络的基本结构如图所示:
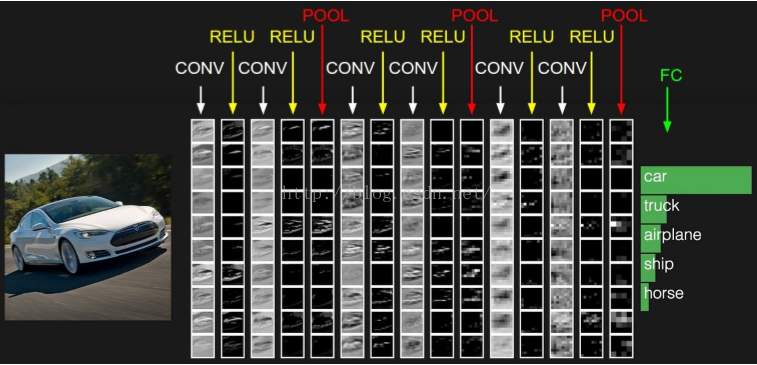
卷积神经网络由三部分构成。第一部分是输入层。第二部分由n个卷积层和池化层的组合组成。第三部分由一个全连结的多层感知机分类器构成。

在上右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的万分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。
3. 权值共享
但其实这样的话参数仍然过多,那么就启动第二级神器,即权值共享。在上面的局部连接中,每个神经元都对应100个参数,一共1000000个神经元,如果这1000000个神经元的100个参数都是相等的,那么参数数目就变为100了。
怎么理解权值共享呢?我们可以这100个参数(也就是卷积操作)看成是提取特征的方式,该方式与位置无关。这其中隐含的原理则是:图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更直观一些,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
如下图所示,展示了一个3×3的卷积核在5×5的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
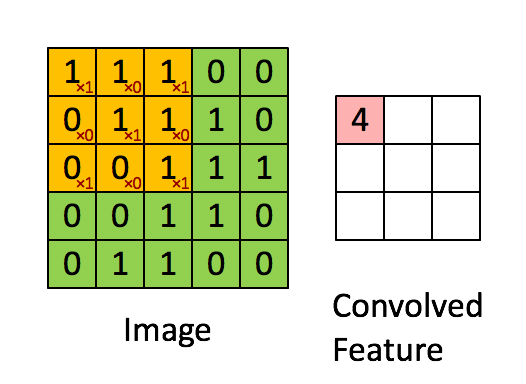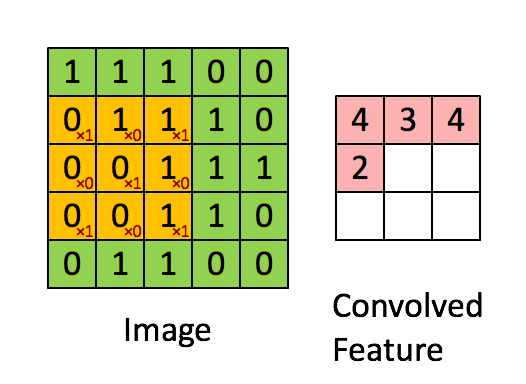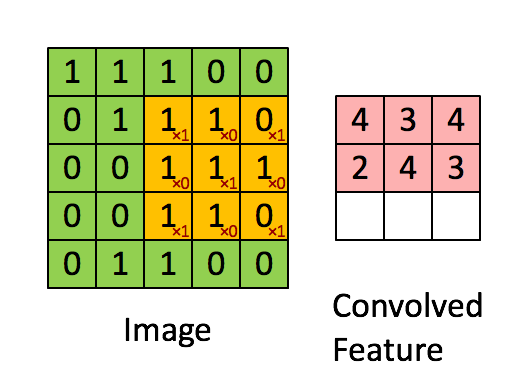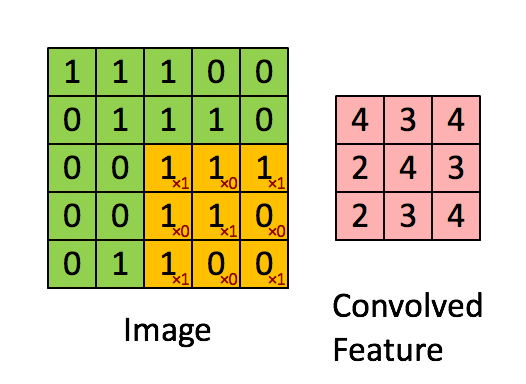
4. 多卷积核
5. 池化层 (池化操作)
1. NLP中CNN的输入可以是什么?
任何矩阵都可以作为CNN的输入,使用word2vec,可以参考 word2vec中的数学原理