3.1 卷积神经网络(CNN)原理
学习目标
- 目标
- 了解卷积神经网络的构成
- 记忆卷积的原理以及计算过程
- 了解池化的作用以及计算过程
- 应用
- 无
为什么需要卷积神经网络
在计算机视觉领域,通常要做的就是指用机器程序替代人眼对目标图像进行识别等。那么神经网络也好还是卷积神经网络其实都是上个世纪就有的算法,只是近些年来电脑的计算能力已非当年的那种计算水平,同时现在的训练数据很多,于是神经网络的相关算法又重新流行起来,因此卷积神经网络也一样流行。
- 1974年,Paul Werbos提出了误差反向传导来训练人工神经网络,使得训练多层神经网络成为可能。
- 1979年,Kunihiko Fukushima(福岛邦彦),提出了Neocognitron, 卷积、池化的概念基本形成。
- 1986年,Geoffrey Hinton与人合著了一篇论文:Learning representations by back-propagation errors。
- 1989年,Yann LeCun提出了一种用反向传导进行更新的卷积神经网络,称为LeNet。
- 1998年,Yann LeCun改进了原来的卷积网络,LeNet-5。
原因之一:图像特征数量对神经网络效果压力
假设下图是一图片大小为28 * 28 的黑白图片时候,每一个像素点只有一个值(单通道)。那么总的数值个数为 784个特征。

那现在这张图片是彩色的,那么彩色图片由RGB三通道组成,也就意味着总的数值有28 28 3 = 2352个值。

从上面我们得到一张图片的输入是2352个特征值,即神经网路当中与若干个神经元连接,假设第一个隐层是10个神经元,那么也就是23520个权重参数。
如果图片再大一些呢,假设图片为1000 1000 3,那么总共有3百万数值,同样接入10个神经元,那么就是3千万个权重参数。这样的参数大小,神经网络参数更新需要大量的计算不说,也很难达到更好的效果,大家就不倾向于使用多层神经网络了。
所以就有了卷积神经网络的流行,那么卷积神经网络为什么大家会选择它。那么先来介绍感受野以及边缘检测的概念。
注:另有卷积网络感受野的概念,也是为什么使用卷积的原因
3.1.1 卷积神经网络的组成
- 定义
- 卷积神经网络由一个或多个卷积层、池化层以及全连接层等组成。与其他深度学习结构相比,卷积神经网络在图像等方面能够给出更好的结果。这一模型也可以使用反向传播算法进行训练。相比较其他浅层或深度神经网络,卷积神经网络需要考量的参数更少,使之成为一种颇具吸引力的深度学习结构。
我们来看一下卷积网络的整体结构什么样子。

其中包含了几个主要结构
- 卷积层(Convolutions)
- 池化层(Subsampling)
- 全连接层(Full connection)
- 激活函数
3.1.2 卷积层
- 目的
- 卷积运算的目的是提取输入的不同特征,某些卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
- 参数:
- size:卷积核/过滤器大小,选择有1 1, 3 3, 5 * 5(为什么是奇数个)
- padding:零填充,Valid 与Same
- stride:步长,通常默认为1
- 计算公式

3.1.2.1 卷积运算过程
对于之前介绍的卷积运算过程,我们用一张动图来表示更好理解些。一下计算中,假设图片长宽相等,设为N
- 一个步长,3 X 3 卷积核运算
假设是一张5 X 5 的单通道图片,通过使用3 X 3 大小的卷积核运算得到一个 3 X 3大小的运算结果(图片像素数值仅供参考)


3.1.3 padding-零填充
零填充:在图片像素的最外层加上若干层0值,若一层,记做p =1。
- 为什么增加的是0?
因为0在权重乘积和运算中对最终结果不造成影响,也就避免了图片增加了额外的干扰信息。

这张图中,还是移动一个像素,并且外面增加了一层0。那么最终计算结果我们可以这样用公式来计算:
5 + 2 * p - 3 + 1 = 55+2∗p−3+1=5
P为1,那么最终特征结果为5。实际上我们可以填充更多的像素,假设为2层,则
5 + 2 * 2 - 3 + 1 = 75+2∗2−3+1=7,这样得到的观察特征大小比之前图片大小还大。所以我们对于零填充会有一些选择,该填充多少?
3.1.3.1 Valid and Same卷积
有两种两种形式,所以为了避免上述情况,大家选择都是Same这种填充卷积计算方式

3.1.3.2 奇数维度的过滤器
通过上面的式子,如果F不是奇数而是偶数个,那么最终计算结果不是一个整数,造成0.5,1.5.....这种情况,这样填充不均匀,所以也就是为什么卷积核默认都去使用奇数维度大小
-
1 1,3 3, 5 5,7 7
-
另一个解释角度
- 奇数维度的过滤器有中心,便于指出过滤器的位置
当然这个都是一些假设的原因,最终原因还是在F对于计算结果的影响。所以通常选择奇数维度的过滤器,是大家约定成俗的结果,可能也是基于大量实验奇数能得出更好的结果。
3.1.4 stride-步长
以上例子中我们看到的都是每次移动一个像素步长的结果,如果将这个步长修改为2,3,那结果如何?


3.1.5 多通道卷积
当输入有多个通道(channel)时(例如图片可以有 RGB 三个通道),卷积核需要拥有相同的channel数,每个卷积核 channel 与输入层的对应 channel 进行卷积,将每个 channel 的卷积结果按位相加得到最终的 Feature Map。

3.1.5.1 多卷积核(多个Filter)
当有多个卷积核时,可以学习到多种不同的特征,对应产生包含多个 channel 的 Feature Map, 例如上图有两个 filter,所以 output 有两个 channel。这里的多少个卷积核也可理解为多少个神经元。

相当于我们把多个功能的卷积核的计算结果放在一起,能够检测到图片中不同的特征(边缘检测)
3.1.6 卷积总结
我们来通过一个例子看一下结算结果,以及参数的计算
- 假设我们有10 个Filter,每个Filter3 X 3 X 3(计算RGB图片),并且只有一层卷积,那么参数有多少?
计算:每个Filter参数个数为:3 3 3 + 1 bias = 28个权重参数,总共28 * 10 = 280个参数,即使图片任意大小,我们这层的参数也就这么多。
- 假设一张200 200 3的图片,进行刚才的FIlter,步长为1,最终为了保证最后输出的大小为200 * 200,需要设置多大的零填充

3.1.7 池化层(Pooling)
池化层主要对卷积层学习到的特征图进行亚采样(subsampling)处理,主要由两种
- 最大池化:Max Pooling,取窗口内的最大值作为输出
- 平均池化:Avg Pooling,取窗口内的所有值的均值作为输出
意义在于:
- 降低了后续网络层的输入维度,缩减模型大小,提高计算速度
- 提高了Feature Map 的鲁棒性,防止过拟合

对于一个输入的图片,我们使用一个区域大小为2 2,步长为2的参数进行求最大值操作。同样池化也有一组参数,f, sf,s,得到2 2的大小。当然如果我们调整这个超参数,比如说3 * 3,那么结果就不一样了,通常选择默认都是f = 2 * 2, s = 2f=2∗2,s=2
池化超参数特点:不需要进行学习,不像卷积通过梯度下降进行更新。
如果是平均池化则:

3.1.8 全连接层
卷积层+激活层+池化层可以看成是CNN的特征学习/特征提取层,而学习到的特征(Feature Map)最终应用于模型任务(分类、回归):
- 先对所有 Feature Map 进行扁平化(flatten, 即 reshape 成 1 x N 向量)
- 再接一个或多个全连接层,进行模型学习

3.1.9 总结
- 掌握卷积神经网路的组成
- 掌握卷积的计算过程
- 卷积过滤器个数
- 卷积过滤器大小
- 卷积过滤器步数
- 卷积过滤器零填充
- 掌握池化的计算过程原理
========================================================
2.2案例:CIFAR100类别分类
学习目标
- 目标
- 掌握keras卷积网络相关API
- 掌握卷机网络的构建
- 应用
- 应用keras构建CNN神经网络进行CIFAR100类别分类
2.2.1 CIFAR100数据集介绍
这个数据集就像CIFAR-10,除了它有100个类,每个类包含600个图像。,每类各有500个训练图像和100个测试图像。CIFAR-100中的100个类被分成20个超类。每个图像都带有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类) 以下是CIFAR-100中的类别列表:

等等...

2.2.2 API 使用
- 用于构建CNN模型的API
- Conv2D:实现卷积,kernel_size,strides,padding,dataformat,'NHWC'和'NCHW'
- MaxPool2D:池化操作
keras.layers.Conv2D(32, kernel_size=5, strides=1,
padding='same', data_format='channels_last', activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=2, strides=2, padding='same'),
2.2.3 步骤分析以及代码实现(缩减版LeNet5)
- 读取数据集:
- 从datasets中获取相应的数据集,直接有训练集和测试集
- 需要进行形状处理以及归一化
class CNNMnist(object):
def __init__(self):
(self.train, self.train_label), (self.test, self.test_label) = \
keras.datasets.cifar100.load_data()
self.train = self.train.reshape(-1, 32, 32, 3) / 255.0
self.test = self.test.reshape(-1, 32, 32, 3) / 255.0
-
进行模型编写
- 两层卷积层+两个神经网络层
- 网络设计:
-
第一层
- 卷积:32个filter、大小5*5、strides=1、padding="SAME"
- 激活:Relu
- 池化:大小2x2、strides2
- 第一层
- 卷积:64个filter、大小5*5、strides=1、padding="SAME"
- 激活:Relu
- 池化:大小2x2、strides2
- 全连接层
经过每一层图片数据大小的变化需要确定,CIFAR100输入的每批次若干图片数据大小为[None, 32 * 32],如果要进过卷积计算,需要变成[None, 32, 32, 3]
- 第一层
- 卷积:[None, 32, 32, 3]———>[None, 32, 32, 32]
- 权重数量:[5, 5, 1 ,32]
- 偏置数量:[32]
- 激活:[None, 32, 32, 32]———>[None, 32, 32, 32]
- 池化:[None, 32, 32, 32]———>[None, 16, 16, 32]
- 卷积:[None, 32, 32, 3]———>[None, 32, 32, 32]
- 第二层
- 卷积:[None, 16, 16, 32]———>[None, 16, 16, 64]
- 权重数量:[5, 5, 32 ,64]
- 偏置数量:[64]
- 激活:[None, 16, 16, 64]———>[None, 16, 16, 64]
- 池化:[None, 16, 16, 64]———>[None, 8, 8, 64]
- 卷积:[None, 16, 16, 32]———>[None, 16, 16, 64]
- 全连接层
- [None, 8, 8, 64]——>[None, 8 8 64]
- [None, 8 8 64] x [8 8 64, 1024] = [None, 1024]
- [None,1024] x [1024, 100]——>[None, 100]
- 权重数量:[8 8 64, 1024] + [1024, 100],由分类别数而定
- 偏置数量:[1024] + [100],由分类别数而定
model = keras.Sequential([
keras.layers.Conv2D(32, kernel_size=5, strides=1,
padding='same', data_format='channels_last', activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=2, strides=2, padding='same'),
keras.layers.Conv2D(64, kernel_size=5, strides=1,
padding='same', data_format='channels_last', activation=tf.nn.relu),
keras.layers.MaxPool2D(pool_size=2, strides=2, padding='same'),
keras.layers.Flatten(),
keras.layers.Dense(1024, activation=tf.nn.relu),
keras.layers.Dense(100, activation=tf.nn.softmax),
])
- 其它完整代码
def compile(self):
CNNMnist.model.compile(optimizer=keras.optimizers.Adam(),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
return None
def fit(self):
CNNMnist.model.fit(self.train, self.train_label, epochs=1, batch_size=32)
return None
def evaluate(self):
test_loss, test_acc = CNNMnist.model.evaluate(self.test, self.test_label)
print(test_loss, test_acc)
return None
if __name__ == '__main__':
cnn = CNNMnist()
cnn.compile()
cnn.fit()
cnn.predict()
print(CNNMnist.model.summary())===============================
2.2 梯度下降算法改进
学习目标
- 目标
- 了解深度学习遇到的一些问题
- 知道批梯度下降与MiniBatch梯度下降的区别
- 知道指数加权平均的意义
- 知道动量梯度、RMSProp、Adam算法的公式意义
- 知道学习率衰减方式
- 知道参数初始化策略的意义
- 了解偏差与方差的意义
- 知道L2正则化与L1正则化的数学意义
- 知道Droupout正则化的方法
- 知道常用的一些神经网络超参数
- 知道BN层的意义以及数学原理
- 应用
- 无
深度学习难以在大数据领域发挥最大效果的一个原因是,在巨大的数据集基础上进行训练速度很慢。而优化算法能够帮助我们快速训练模型,提高计算效率。接下来我么就去看有哪些方法能够解决我们刚才遇到的问题或者类似的问题
2.2.1 优化遇到的问题
- 梯度消失
- 局部最优
2.2.1.1 梯度消失
在梯度函数上出现的以指数级递增或者递减的情况分别称为梯度爆炸或者梯度消失。

在计算梯度时,根据不同情况梯度函数也会以指数级递增或递减,导致训练导数难度上升,梯度下降算法的步长会变得非常小,需要训练的时间将会非常长。
2.2.1.2 局部最优

鞍点(saddle)是函数上的导数为零,但不是轴上局部极值的点。通常梯度为零的点是上图所示的鞍点,而非局部最小值。减少损失的难度也来自误差曲面中的鞍点,而不是局部最低点。

- 在训练较大的神经网络、存在大量参数,并且成本函数被定义在较高的维度空间时,困在极差的局部最优基本不会发生
- 鞍点附近的平稳段会使得学习非常缓慢,而这也是需要后面的动量梯度下降法、RMSProp 以及 Adam 优化算法能够加速学习的原因,它们能帮助尽早走出平稳段。
解决办法有多种形式,通常会结合一些形式一起进行
-
初始化参数策略(第一部分第四节提到)
-
Mini梯度下降法
- 梯度下降算法的优化
- 学习率衰减
2.2.2 参数初始化策略(复习)
由于在z={w}_1{x}_1+{w}_2{x}_2 + ... + {w}_n{x}_n + bz=w1x1+w2x2+...+wnxn+b公式中,当输入的数量n较大时,如果每个w_iwi的值都小一些,这样它们的和得到的zz也会非常大,所以会造成我们之前在第一部分最后一节当中介绍的。所以都会初始化比较小的值。
2.2.3 批梯度下降算法(Batch Gradient Descent)
- 定义:批梯度下降法(btach),即同时处理整个训练集。
其在更新参数时使用所有的样本来进行更新。对整个训练集进行梯度下降法的时候,我们必须处理整个训练数据集,然后才能进行一步梯度下降,即每一步梯度下降法需要对整个训练集进行一次处理,如果训练数据集很大的时候,处理速度就会比较慢。
所以换一种方式,每次处理训练数据的一部分进行梯度下降法,则我们的算法速度会执行的更快。
2.2.3.1 Mini-Batch Gradient Descent
- 定义:Mini-Batch 梯度下降法(小批量梯度下降法)每次同时处理固定大小的数据集。
不同
- 种类:
- mini-batch 的大小为 1,即是随机梯度下降法(stochastic gradient descent)
使用 Mini-Batch 梯度下降法,对整个训练集的一次遍历(epoch)只做 mini-batch个样本的梯度下降,一直循环整个训练集。
2.2.3.2 批梯度下降与Mini-Batch梯度下降的区别
batch梯度下降法和Mini-batch 梯度下降法代价函数的变化趋势如下:

那么对于梯度下降优化带来的影响
2.2.3.3 梯度下降优化影响
- batch 梯度下降法:
- 对所有 m 个训练样本执行一次梯度下降,每一次迭代时间较长,训练过程慢;
- 相对噪声低一些,成本函数总是向减小的方向下降。
- 随机梯度下降法(Mini-Batch=1):
- 对每一个训练样本执行一次梯度下降,训练速度快,但丢失了向量化带来的计算加速;
- 有很多噪声,需要适当减小学习率,成本函数总体趋势向全局最小值靠近,但永远不会收敛,而是一直在最小值附近波动。

因此,选择一个合适的大小进行 Mini-batch 梯度下降,可以实现快速学习,也应用了向量化带来的好处,且成本函数的下降处于前两者之间。
2.2.3.4 大小选择
- 如果训练样本的大小比较小,如m\le2000m≤2000时,选择 batch 梯度下降法;
- 如果训练样本的大小比较大,选择 Mini-Batch 梯度下降法。为了和计算机的信息存储方式相适应,代码在 mini-batch 大小为 2 的幂次时运行要快一些。典型的大小为2^6, 2^7,2^8,2^926,27,28,29,mini-batch 的大小要符合 CPU/GPU 内存计算机制。
需要根据经验快速尝试,找到能够最有效地减少成本函数的值。
那么第二种方式是通过优化梯度下降过程,会比梯度下降算法的速度更快些
2.2.4 指数加权平均
指数加权平均(Exponentially Weight Average)是一种常用的序列数据处理方式,通常用在序列场景如金融序列分析、温度变化序列分析。
假设给定一个序列,例如北京一年每天的气温值,图中蓝色的点代表真实数据。

那么这样的气温值变化可以理解成优化的过程波动较大,异常较多。那么怎么平缓一些呢,这时候就要用到加权平均值了,如指数加权平均值。首先看一些效果。


下图中,当取权重值 β=0.98 时,可以得到图中更为平滑的绿色曲线。而当取权重值\betaβ=0.5 时,得到图中噪点更多的黄色曲线。\betaβ越大相当于求取平均利用的天数越多,曲线自然就会越平滑而且越滞后。这些系数被称作偏差修正(Bias Correction)


上述点数据,我们是否可以理解成梯度下降的过程,每一迭代优化计算出来的梯度值,
2.2.5 动量梯度下降法
动量梯度下降(Gradient Descent with Momentum)是计算梯度的指数加权平均数,并利用该值来更新参数值。动量梯度下降法的整个过程为:


使用动量梯度下降时,通过累加过去的梯度值来减少抵达最小值路径上的波动,加速了收敛,因此在横轴方向下降得更快,从而得到图中红色或者紫色的曲线。当前后梯度方向一致时,动量梯度下降能够加速学习;而前后梯度方向不一致时,动量梯度下降能够抑制震荡。
我们可以这样形象的理解,
- 鞍点附近:小球在向下运动过程中,导致越来越快,由于\betaβ的存在使得不会一直加速运行。
- 鞍点附近:由于增加了一个动量,在C、D方向上能够有一个动量冲过。
2.2.6 RMSProp 算法
RMSProp(Root Mean Square Prop)算法是在对梯度进行指数加权平均的基础上,引入平方和平方根。

2.2.7 Adam算法
Adam 优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起。
假设用每一个 mini-batch 计算 dW、db,第tt次迭代时:

2.2.8 TensorFlow Adam算法API
- tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999,epsilon=1e-08,name='Adam')
Adam 优化算法有很多的超参数:
- 学习率\alphaα:需要尝试一系列的值,来寻找比较合适的
- β1:常用的缺省值为 0.9
- β2:Adam 算法的作者建议为 0.999
- ϵ:Adam 算法的作者建议为epsilon的默认值1e-8
注:β1、β2、ϵ 通常不需要调试
2.2.9 学习率衰减
如果设置一个固定的学习率 α
- 在最小值点附近,由于不同的 batch 中存在一定的噪声,因此不会精确收敛,而是始终在最小值周围一个较大的范围内波动。
- 如果随着时间慢慢减少学习率 α 的大小,在初期 α 较大时,下降的步长较大,能以较快的速度进行梯度下降;而后期逐步减小 α 的值,即减小步长,有助于算法的收敛,更容易接近最优解。


2.2.10 其它非算法优化的方式-标准化输入
对网络输入的特征进行标准化,能够缓解梯度消失或者梯度爆炸


那么这种有什么好处?主要是对于损失函数带来的好处.
- 标准化前的损失函数

这样的话,对于梯度下降无论从哪个位置开始迭代,都能以相对较少的迭代次数找到全局最优解。可以加速网络的学习。
理解这个原理,其实还是最初的这样的公式:z={w}_1{x}_1+{w}_2{x}_2 + ... + {w}_n{x}_n + bz=w1x1+w2x2+...+wnxn+b
如果激活函数的输入X近似设置成均值为 0,标准方差为 1,神经元输出 z 的方差就正则化到1了。虽然没有解决梯度消失和爆炸的问题,但其在一定程度上确实减缓了梯度消失和爆炸的速度。
2.2.11 神经网络调优
我们经常会涉及到参数的调优,也称之为超参数调优。目前我们从第二部分中讲过的超参数有
- 算法层面:
- 学习率\alphaα
- \beta1,\beta2, \epsilonβ1,β2,ϵ: Adam 优化算法的超参数,常设为 0.9、0.999、10^{-8}10−8
- \lambdaλ:正则化网络参数,
- 网络层面:
- hidden units:各隐藏层神经元个数
- layers:神经网络层数
2.2.11.1 调参技巧
对于调参,通常采用跟机器学习中介绍的网格搜索一致,让所有参数的可能组合在一起,得到N组结果。然后去测试每一组的效果去选择。
假设我们现在有两个参数
\alphaα: 0.1,0.01,0.001,\betaβ:0.8,0.88,0.9
这样会有9种组合,[0.1, 0.8], [0.1, 0.88], [0.1, 0.9]…….
- 合理的参数设置
- 学习率\alphaα:0.0001、0.001、0.01、0.1,跨度稍微大一些。
- 算法参数\betaβ, 0.999、0.9995、0.998等,尽可能的选择接近于1的值
注:而指数移动平均值参数:β 从 0.9 (相当于近10天的影响)增加到 0.9005 对结果(1/(1-β))几乎没有影响,而 β 从 0.999 到 0.9995 对结果的影响会较大,因为是指数级增加。通过介绍过的式子理解S_{100} = 0.1Y_{100} + 0.1 * 0.9Y_{99} + 0.1 * {(0.9)}^2Y_{98} + ...S100=0.1Y100+0.1∗0.9Y99+0.1∗(0.9)2Y98+...
2.2.11.2 运行
通常我们有这么多参数组合,每一个组合运行训练都需要很长时间,但是如果资源允许的话,可以同时并行的训练多个参数模型,并观察效果。如果资源不允许的话,还是得一个模型一个模型的运行,并时刻观察损失的变化
所以对于这么多的超参数,调优是一件复杂的事情,怎么让这么多的超参数范围,工作效果还能达到更好,训练变得更容易呢?
2.2.12 批标准化(Batch Normalization)
Batch Normalization论文地址:https://arxiv.org/abs/1502.03167
其中最开头介绍是这样的:

训练深度神经网络很复杂,因为在训练期间每层输入的分布发生变化,因为前一层的参数发生了变化。这通过要求较低的学
习率和仔细的参数初始化来减慢训练速度,并且使得训练具有饱和非线性的模型变得非常困难。我们将这种现象称为** 内部协
变量偏移** ,并通过 **标准化层** 输入来解决问题。我们的方法的优势在于使标准化成为模型体系结构的一部分,并为每
个培训小批量执行标准化。批量标准化允许我们使用更高的学习率并且不太关心初始化。它还可以充当调节器,在某些情况
下可以消除对Dropout的需求。应用于最先进的图像分类模型,批量标准化实现了相同的精度,培训步骤减少了14倍,并
且显着地超过了原始模型。使用批量标准化网络的集合,我们改进了ImageNet分类的最佳发布结果:达到4.9%的前5个
验证错误(和4.8%的测试错误),超出了人类评估者的准确性。
2.2.12.2 过程图
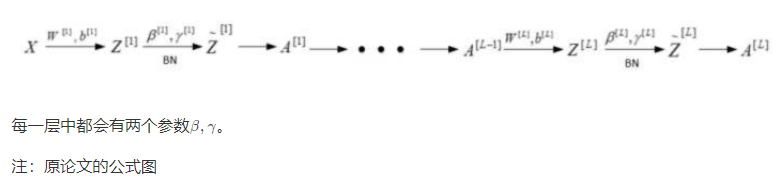

2.4.2.2 为什么批标准化能够是优化过程变得简单
我们之前在原文中标记了一个问题叫做叫做"internal covariate shift"。这个词翻译叫做协变量偏移,但是并不是很好理解。那么有一个解释叫做 在网络当中数据的分布会随着不同数据集改变 。这是网络中存在的问题。那我们一起来看一下数据本身分布是在这里会有什么问题。

也就是说如果我们在训练集中的数据分布如左图,那么网络当中学习到的分布状况也就是左图。那对于给定一个测试集中的数据,分布不一样。这个网络可能就不能准确去区分。这种情况下,一般要对模型进行重新训练。
Batch Normalization的作用就是减小Internal Covariate Shift 所带来的影响,让模型变得更加健壮,鲁棒性(Robustness)更强。即使输入的值改变了,由于 Batch Normalization 的作用,使得均值和方差保持固定(由每一层\gammaγ和\betaβ决定),限制了在前层的参数更新对数值分布的影响程度,因此后层的学习变得更容易一些。Batch Normalization 减少了各层 W 和 b 之间的耦合性,让各层更加独立,实现自我训练学习的效果
2.3.13.3 BN总结
Batch Normalization 也起到微弱的正则化效果,但是不要将 Batch Normalization 作为正则化的手段,而是当作加速学习的方式。Batch Normalization主要解决的还是反向传播过程中的梯度问题(梯度消失和爆炸)。
2.2.14 总结
- 掌握基本的超参数以及调参技巧
-
掌握BN的原理以及作用
-
掌握参数初始化策略的优点
-
掌握Mini-batch的特点以及优势
- 掌握梯度下降算法优化的目的以及效果
- 掌握指数移动平均值的好处
- 掌握动量梯度下降法的优点以及RMSProp、Adam的特点
- 掌握学习率衰减方式
- 掌握标准化输入带来的网络学习速度的提升
===========================================
2.4 BN与神经网络调优
学习目标
- 目标
- 知道常用的一些神经网络超参数
- 知道BN层的意义以及数学原理
- 应用
- 无
2.4.1 神经网络调优

2.4.1.1 调参技巧
对于调参,通常采用跟机器学习中介绍的网格搜索一致,让所有参数的可能组合在一起,得到N组结果。然后去测试每一组的效果去选择。

2.4.1.2 运行
通常我们有这么多参数组合,每一个组合运行训练都需要很长时间,但是如果资源允许的话,可以同时并行的训练多个参数模型,并观察效果。如果资源不允许的话,还是得一个模型一个模型的运行,并时刻观察损失的变化
所以对于这么多的超参数,调优是一件复杂的事情,怎么让这么多的超参数范围,工作效果还能达到更好,训练变得更容易呢?
2.4.2 批标准化(Batch Normalization)
Batch Normalization论文地址:https://arxiv.org/abs/1502.03167
其中最开头介绍是这样的:

训练深度神经网络很复杂,因为在训练期间每层输入的分布发生变化,因为前一层的参数发生了变化。这通过要求较低的学
习率和仔细的参数初始化来减慢训练速度,并且使得训练具有饱和非线性的模型变得非常困难。我们将这种现象称为** 内部协
变量偏移** ,并通过 **标准化层** 输入来解决问题。我们的方法的优势在于使标准化成为模型体系结构的一部分,并为每
个培训小批量执行标准化。批量标准化允许我们使用更高的学习率并且不太关心初始化。它还可以充当调节器,在某些情况
下可以消除对Dropout的需求。应用于最先进的图像分类模型,批量标准化实现了相同的精度,培训步骤减少了14倍,并
且显着地超过了原始模型。使用批量标准化网络的集合,我们改进了ImageNet分类的最佳发布结果:达到4.9%的前5个
验证错误(和4.8%的测试错误),超出了人类评估者的准确性。
首先我们还是回到之前,我们对输入特征 X 使用了标准化处理。标准化化后的优化得到了加速。
对于深层网络呢?我们接下来看一下这个公式,这是向量的表示。表示每Mini-batch有m个样本。
- m个样本的向量表示





2.4.2.2 为什么批标准化能够是优化过程变得简单
我们之前在原文中标记了一个问题叫做叫做"internal covariate shift"。这个词翻译叫做协变量偏移,但是并不是很好理解。那么有一个解释叫做 在网络当中数据的分布会随着不同数据集改变 。这是网络中存在的问题。那我们一起来看一下数据本身分布是在这里会有什么问题。

也就是说如果我们在训练集中的数据分布如左图,那么网络当中学习到的分布状况也就是左图。那对于给定一个测试集中的数据,分布不一样。这个网络可能就不能准确去区分。这种情况下,一般要对模型进行重新训练。
Batch Normalization的作用就是减小Internal Covariate Shift 所带来的影响,让模型变得更加健壮,鲁棒性(Robustness)更强。即使输入的值改变了,由于 Batch Normalization 的作用,使得均值和方差保持固定(由每一层\gammaγ和\betaβ决定),限制了在前层的参数更新对数值分布的影响程度,因此后层的学习变得更容易一些。Batch Normalization 减少了各层 W 和 b 之间的耦合性,让各层更加独立,实现自我训练学习的效果
2.4.2.3 BN总结
Batch Normalization 也起到微弱的正则化效果,但是不要将 Batch Normalization 作为正则化的手段,而是当作加速学习的方式。Batch Normalization主要解决的还是反向传播过程中的梯度问题(梯度消失和爆炸)。
2.4.3 总结
- 掌握基本的超参数以及调参技巧
- 掌握BN的原理以及作用
=================================================
2.4 经典分类网络结构
学习目标
- 目标
- 知道LeNet-5网络结构
- 了解经典的分类网络结构
- 知道一些常见的卷机网络结构的优化
- 知道NIN中1x1卷积原理以及作用
- 知道Inception的作用
- 了解卷积神经网络学习过程内容
- 应用
- 无
下面我们主要以一些常见的网络结构去解析,并介绍大部分的网络的特点。这里看一下卷积的发展历史图。

2.4.1 LeNet-5解析
首先我们从一个稍微早一些的卷积网络结构LeNet-5(这里稍微改了下名字),开始的目的是用来识别数字的。从前往后介绍完整的结构组成,并计算相关输入和输出。
2.4.1.1 网络结构

- 激活层默认不画网络图当中,这个网络结构当时使用的是sigmoid和Tanh函数,还没有出现Relu函数
- 将卷积、激活、池化视作一层,即使池化没有参数
2.4.1.2 参数形状总结
| shape | size | parameters | |
|---|---|---|---|
| Input | (32,32,3) | 3072 | 0 |
| Conv1(f=5,s=1) | (28,28,6) | 4704 | 450+6 |
| Pool1 | (14,14,6) | 1176 | 0 |
| Conv2(f=5,s=1) | (10,10,16) | 1600 | 2400+16 |
| Pool2 | (5,5,16) | 400 | 0 |
| FC3 | (120,1) | 120 | 48000+120 |
| FC4 | (84,1) | 84 | 10080+84 |
| Ouput:softmax | (10,1) | 10 | 840+10 |
- 中间的特征大小变化不宜过快
事实上,在过去很多年,许多机构或者学者都发布了各种各样的网络,其实去了解设计网络最好的办法就是去研究现有的网络结构或者论文。大多数网络设计出来是为了Image Net的比赛(解决ImageNet中的1000类图像分类或定位问题),后来大家在各个业务上进行使用。
2.4.2 AlexNet
2012年,Alex Krizhevsky、Ilya Sutskever在多伦多大学Geoff Hinton的实验室设计出了一个深层的卷积神经网络AlexNet,夺得了2012年ImageNet LSVRC的冠军,且准确率远超第二名(top5错误率为15.3%,第二名为26.2%),引起了很大的轰动。AlexNet可以说是具有历史意义的一个网络结构。

- 总参数量:60M=6000万,5层卷积+3层全连接
- 使用了非线性激活函数:ReLU
- 防止过拟合的方法:Dropout
- 批标准化层的使用
2.4.3 卷积网络结构的优化
2.4.3.1 常见结构特点
整个过程:AlexNet—NIN—(VGG—GoogLeNet)—ResNet
- NIN:引入1 * 1卷积
- VGG,斩获2014年分类第二(第一是GoogLeNet),定位任务第一。
- 参数量巨大,140M = 1.4亿
- 19layers
- VGG 版本
- VGG16
- VGG19

GoogleNet,2014年比赛冠军的model,这个model证明了一件事:用更多的卷积,更深的层次可以得到更好的结构。(当然,它并没有证明浅的层次不能达到这样的效果)
- 500万的参数量
- 22layers
- 引入了Inception模块
- Inception V1
- Inception V2
- Inception V3
- Inception V4

- 下面我们将针对卷积网络架构常用的一些结构进行详细分析,来探究这些结构带来的好处
2.4.4 Inception 结构
首先我们要说一下在Network in Network中引入的1 x 1卷积结构的相关作用
2.4.4.1MLP卷积(1 x 1卷积)

- 目的:提出了一种新的深度网络结构,称为“网络中的网络”(NIN),增强接受域内局部贴片的模型判别能力。
- 做法
- 对于传统线性卷积核:采用线性滤波器,然后采用非线性激活。
- 提出MLP卷积取代传统线性卷积核
- 作用或优点:
- 1、多个1x1的卷积核级联加上配合激活函数,将feature map由多通道的线性组合变为非线性组合(信息整合),提高特征抽象能力(Multilayer Perceptron,缩写MLP,就是一个多层神经网络)
- 2、1x1的卷积核操作还可以实现卷积核通道数的降维和升维,实现参数的减小化
2.4.4.2 1 x 1卷积介绍

从图中,看到1 x 1卷积的过程,那么这里先假设只有3个1x1Filter,那么最终结果还是56x56x3。但是每一个FIlter的三个参数的作用
- 看作是对三个通道进行了线性组合。
我们甚至可以把这几个FIlter可以看成就是一个简单的神经元结构,每个神经元参数数量与前面的通道数量相等。
- 通常在卷积之后会加入非线性激活函数,在这里之后加入激活函数,就可以理解成一个简单的MLP网络了。
2.4.4.3 通道数变化
那么对于1x1网络对通道数的变化,其实并不是最重要的特点,因为毕竟3 x 3,5 x 5都可以带来通道数的变化,
而1x1卷积的参数并不多,我们拿下面的例子来看。

- 保持通道数不变
- 提升通道数
- 减少通道数
2.4.4.4 Inception层
这个结构其实还有名字叫盗梦空间结构。
- 目的:
- 代替人手工去确定到底使用1x1,3x3,5x5还是是否需要max_pooling层,由网络自动去寻找适合的结构。并且节省计算。

- 特点
- 是每一个卷积/池化最终结果的长、宽大小一致
- 特殊的池化层,需要增加padding,步长为1来使得输出大小一致,并且选择32的通道数
- 最终结果28 x 28 x 256
- 使用更少的参数,达到跟AlexNet或者VGG同样类似的输出结果
2.4.4.5 Inception改进
改进目的:减少计算,如5 x 5卷积那的运算量

- 上面的参数:5 x 5 x 32 x 192 =153600
- 下面的参数:192 x 16 + 5 x 5 x 16 x 32 = 3072 + 12800 = 15872
所以上面的结构会需要大量的计算,我们把这种改进的结构称之为网络的"瓶颈",网络缩小后扩大。
那么这样改变会影响网络的性能和效果吗?
GoogleNet就是如此,获得了非常好的效果。所以合理的设计网络当中的Inception结构能够减少计算,实现更好的效果。
2.4.4.6 GoogleNet结构(了解)
其中包含了多个Inception结构。

完整结构:






2.3.5 卷积神经网络学习特征可视化
我们肯定会有疑问真个深度的卷积网络到底在学习什么?可以将网络学习过程中产生的特征图可视化出来,并且对比原图来看看每一层都干了什么。
- 可视化案例使用的网络

- 可视化结果




- layer1,layer2学习到的特征基本是颜色、边缘等低层特征
- layer3学习到的特征,一些纹理特征,如网格纹理
- layer4学习到的特征会稍微复杂些,比如狗的头部形状
- layer5学习到的是完整一些的,比如关键性的区分特征
2.4.6 案例:使用pre_trained模型进行VGG预测
Google 在提供VGG行预测的时候效果会更好一些,所以选择VGG来进行测试
2.4.6.1 VGG模型使用
在tensorflow.keras.applications中已经存在很多现有模型,
from tensorflow._api.v1.keras.applications import densenet
from tensorflow._api.v1.keras.applications import inception_resnet_v2
from tensorflow._api.v1.keras.applications import inception_v3
from tensorflow._api.v1.keras.applications import mobilenet
from tensorflow._api.v1.keras.applications import mobilenet_v2
from tensorflow._api.v1.keras.applications import nasnet
from tensorflow._api.v1.keras.applications import resnet50
from tensorflow._api.v1.keras.applications import vgg16
from tensorflow._api.v1.keras.applications import vgg19
from tensorflow._api.v1.keras.applications import xception
from tensorflow.python.keras.applications import DenseNet121
from tensorflow.python.keras.applications import DenseNet169
from tensorflow.python.keras.applications import DenseNet201
from tensorflow.python.keras.applications import InceptionResNetV2
from tensorflow.python.keras.applications import InceptionV3
from tensorflow.python.keras.applications import MobileNet
from tensorflow.python.keras.applications import MobileNetV2
from tensorflow.python.keras.applications import NASNetLarge
from tensorflow.python.keras.applications import NASNetMobile
from tensorflow.python.keras.applications import ResNet50
from tensorflow.python.keras.applications import VGG16
from tensorflow.python.keras.applications import VGG19
from tensorflow.python.keras.applications import Xception
我们来使用其中一个VGG16的模型进行预测,这个模型源码文件中提供了相关的预处理图片的接口以及预测结果概率的处理API
from tensorflow.python.keras.applications import VGG16
from tensorflow.python.keras.applications.vgg16 import decode_predictions
from tensorflow.python.keras.applications.vgg16 import preprocess_input
- preprocess_input:处理输入图片
- decode_predictions:对预测结果进行处理
2.4.6.2 步骤以及代码
- 模型获取以及已训练好的参数加载
- 注意:参数总计超过500M,因此当你首次使用下面的命令时,Keras需要从网上先下载这些参数,这可能需要耗用一些时间。
model = VGG16()
print(model.summary())
模型打印为:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 224, 224, 3) 0
_________________________________________________________________
block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
- 图片的输入以及格式转换
我们将会用到两个API,但是使用这个API需要PIL工具,3.7兆左右大小
# 在虚拟环境中下载
pip install PIL
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.preprocessing.image import img_to_array
进行本地图片的加载,
# 加载一个图片到VGG指定输入大小
image = load_img('./tiger.png', target_size=(224, 224))
# 进行数据转换到numpy数组形式,以便于VGG能够进行使用
image = img_to_array(image)
# 形状修改
image = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
- 使用模型对数据进行处理和预测
# 输入数据进行预测,进行图片的归一化处理
image = preprocess_input(image)
y_predict = model.predict(image)
# 进行结果解码
label = decode_predictions(y_predict)
# 进行lable获取
res = label[0][0]
# 预测的结果输出
print('预测的类别为:%s 概率为:(%.2f%%)' % (res[1], res[2]*100))
输出结果为
Downloading data from https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json
8192/35363 [=====>........................] - ETA: 0s
24576/35363 [===================>..........] - ETA: 0s
40960/35363 [==================================] - 0s 6us/step
预测的类别为:tiger 概率为:(80.30%)
2.4.7 总结
- 掌握LeNet-5 结构计算
- 了解卷积常见网络结构
- 掌握1x1卷积结构作用
- 掌握Inception结构作用
- 掌握keras的VGG模型的使用
========================================
2.5 CNN网络实战技巧
学习目标
- 目标
- 了解迁移学习以及技巧
- 应用
- 无
我们来看一个个问题如果我们要做一个具体场景的计算机视觉任务,那么从头开始训练一个网络是合适的选择吗?怎么样才能避免浪费过多的计算时间?
2.5.1 迁移学习(Transfer Learning)
2.5.1.1 介绍
- 定义
- 迁移学习就是利用数据、任务或模型之间的相似性,将在旧的领域学习过或训练好的模型,应用于新的领域这样的一个过程。
- 两个任务的输入属于同一性质:要么同是图像、要么同是语音或其他
迁移学习到底在什么情况下使用呢?有两个方面需要我们考虑的
- 1、当我们有海量的数据资源时,可以不需要迁移学习,机器学习系统很容易从海量数据中学习到一个鲁棒性很强的模型。但通常情况下,我们需要研究的领域可获得的数据极为有限,在少量的训练样本上精度极高,但是泛化效果极差。
- 2、训练成本,很少去从头开始训练一整个深度卷积网络,从头开始训练一个卷积网络通常需要较长时间且依赖于强大的 GPU 计算资源。
2.5.1.2 方法
- 最常见的称呼叫做fine tuning,即微调
- 已训练好的模型,称之为Pre-trained model
通常我们需要加载以训练好的模型,这些可以是一些机构或者公司在ImageNet等类似比赛上进行训练过的模型。TensorFlow同样也提供了相关模型地址:https://github.com/tensorflow/models/tree/master/research/slim
下图是其中包含的一些模型:

2.5.1.3 过程
这里我们举一个例子,假设有两个任务A和B,任务 A 拥有海量的数据资源且已训练好,但并不是我们的目标任务,任务 B 是我们的目标任务。下面的网络模型假设是已训练好的1000个类别模型

而B任务假设是某个具体场景如250个类别的食物识别,那么该怎么去做
- 1、建立自己的网络,在A的基础上,修改最后输出结构,并加载A的模型参数
- 2、根据数据大小调整
- 如果B任务数据量小,那么我们可以选择将A模型的所有的层进行freeze(可以通过Tensorflow的trainable=False参数实现),而剩下的输出层部分可以选择调整参数训练
- 如果B任务的数据量大,那么我们可以将A中一半或者大部分的层进行freeze,而剩下部分的layer可以进行新任务数据基础上的微调
3.1 迁移学习案例
学习目标
- 目标
- 说明数据增强的作用
- 应用
- 应用Keras基于VGG对五种图片类别识别的迁移学习
3.1.1 案例:基于VGG对五种图片类别识别的迁移学习
3.1.1.2 数据集以及迁移需求
数据集是某场景下5个类别图片的识别
我们利用现有的VGG模型去进行微调
3.1.1.3 思路和步骤
- 读取本地的图片数据以及类别
- keras.preprocessing.image import ImageDataGenerator提供了读取转换功能
- 模型的结构修改(添加我们自定的分类层)
- freeze掉原始VGG模型
- 编译以及训练和保存模型方式
- 输入数据进行预测
3.1.1.4 训练的时候读取本地图片以及类别
-
使用一个ImageDataGenerator图片生成器,定义图片处理以及数据增强相关
-
train_generator = ImageDataGenerator( rescale=1.0 / 255, # 标准化 rotation_range=20, # 旋转 width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
-
这个API提供数据处理相关功能,以及数据增强功能
-
train_generator.flow_from_directory(directory=path,# 读取目录 target_size=(h,w),# 目标形状 batch_size=size,# 批数量大小 class_mode='binary', # 目标值格式 shuffle=True)
-
这个API固定了读取的目录格式,参考:
-
data/ train/ dogs/ dog001.jpg dog002.jpg ... cats/ cat001.jpg cat002.jpg ... validation/ dogs/ dog001.jpg dog002.jpg ... cats/ cat001.jpg cat002.jpg ...
-
-
代码:
首先导入包
import tensorflow as tf
from tensorflow import keras
from tensorflow.python.keras.preprocessing.image import ImageDataGenerator
我们定义一个迁移学习的类,然后进行相关属性设置和读取代码
class TransferModel(object):
def __init__(self):
self.model_size = (224, 224)
self.train_dir = "./data/train/"
self.test_dir = "./data/test/"
self.batch_size = 32
self.train_generator = ImageDataGenerator(rescale=1.0 / 255)
self.test_generator = ImageDataGenerator(rescale=1.0 / 255)
def read_img_to_generator(self):
"""
读取本地固定格式数据
:return:
"""
train_gen = self.train_generator.flow_from_directory(directory=self.train_dir,
target_size=self.model_size,
batch_size=self.batch_size,
class_mode='binary',
shuffle=True)
test_gen = self.test_generator.flow_from_directory(directory=self.test_dir,
target_size=self.model_size,
batch_size=self.batch_size,
class_mode='binary',
shuffle=True)
return train_gen, test_gen
3.1.1.5 VGG模型的修改添加全连接层-GlobalAveragePooling2D
对于VGG最后的1000输出结果,我们选择不动,在这基础之上我们添加若干层全连接层。
- 一个GlobalAveragePooling2D + 两个全连接层
- 在图像分类任务中,模型经过最后CNN层后的尺寸为[bath_size, img_width, img_height, channels],通常的做法是:接一个flatten layer,将尺寸变为[batch_size, w h channels],再至少接一个FC layer,这样做的最大问题是:模型参数多,且容易过拟合。利用pooling layer来替代最后的FC layer
解释如下:
from keras.layers import Dense, Input, Conv2D
from keras.layers import MaxPooling2D, GlobalAveragePooling2D
x = Input(shape=[8, 8, 2048])
# 假定最后一层CNN的层输出为(None, 8, 8, 2048)
x = GlobalAveragePooling2D(name='avg_pool')(x) # shape=(?, 2048)
# 取每一个特征图的平均值作为输出,用以替代全连接层
x = Dense(1000, activation='softmax', name='predictions')(x) # shape=(?, 1000)
# 100为类别
- 5类图片识别模型修改
我们需要拿到基础VGG模型,并且VGG提供所有层参数训练好的模型和没有全连接层参数的模型notop模型
- notop模型:
- 是否包含最后的3个全连接层(whether to include the 3 fully-connected layers at the top of the network)。用来做fine-tuning专用,专门开源了这类模型。
‘weights='imagenet'’,意思是VGG在在ResNet结构预训练的权重
# 在__init__中添加
self.base_model = VGG16(weights='imagenet', include_top=False)
base_model会有相关属性,模型的输入结构:inputs,模型的输出结构,我们修改需要得到已有VGG的输入和自定义模型的输出构建成一个新的模型。
def refine_vgg_model(self):
"""
添加尾部全连接层
:return:
"""
x = self.base_model.outputs[0]
x = keras.layers.GlobalAveragePooling2D()(x)
x = keras.layers.Dense(1024, activation=tf.nn.relu)(x)
y_predict = keras.layers.Dense(5, activation=tf.nn.softmax)(x)
model = keras.Model(inputs=self.base_model.inputs, outputs=y_predict)
return model
3.1.1.6 freeze VGG模型结构
目的:让VGG结构当中的权重参数不参与训练
- 通过使用每一层的layer.trainable=False
def freeze_vgg_model(self):
"""
freeze掉VGG的结构
:return:
"""
for layer in self.base_model.layers:
layer.trainable = False
3.1.1.7 编译和训练
- 编译
同样还是进行编译, 在迁移学习中算法:学习率初始化较小的值,0.001,0.0001,因为已经在已训练好的模型基础之上更新,所以不需要太大学习率去学习
def compile(self, model):
model.compile(optimizer=keras.optimizers.Adam(),
loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
- 训练
训练的时候通常有两种格式需要保存,H5和ckpt格式,所以选择保存两者
- ckpt保存:使用checkpint工具,ModelCheckpoint指定相关参数
- save_weights
def fit(self, model, train_gen, test_gen):
"""
:param model:
:param train_gen:
:param test_gen:
:return:
"""
check = ModelCheckpoint('./ckpt/transferModel',
monitor='val_loss', # 需要监视的值
save_best_only=False,
save_weights_only=False,
mode='auto',
period=1)
model.fit_generator(train_gen, epochs=1, validation_data=test_gen, callbacks=[check])
model.save_weights("./Transfer.h5")
- main函数
if __name__ == '__main__':
tm = TransferModel()
train_gen, test_gen = tm.read_img_to_generator()
model = tm.refine_vgg_model()
# tm.freeze_vgg_model()
# tm.compile(model)
# tm.fit(model, train_gen, test_gen)
tm.predict(model)
3.1.1.8 进行预测
预测的步骤就是读取图片以及处理到模型中预测,加载我们训练的模型
def predict(self, model):
model.load_weights("./Transfer.h5")
# 2、对图片进行加载和类型修改
image = load_img("./data/test/dinosaurs/402.jpg", target_size=(224, 224))
print(image)
# 转换成numpy array数组
image = img_to_array(image)
print("图片的形状:", image.shape)
# 形状从3维度修改成4维
img = image.reshape((1, image.shape[0], image.shape[1], image.shape[2]))
print("改变形状结果:", img.shape)
# 3、处理图像内容,归一化处理等,进行预测
img = preprocess_input(img)
print(img.shape)
y_predict = model.predict(img)
index = np.argmax(y_predict, axis=1)
print(self.label_dict[str(index[0])])
建立图片类别的字典
self.label_dict = {
'0': 'bus',
'1': 'dinosaurs',
'2': 'elephants',
'3': 'flowers',
'4': 'horse'
}
关于:ModelCheckpoint
keras.callbacks.ModelCheckpoint(filepath, monitor='val_loss', verbose=0, save_best_only=False, save_weights_only=False, mode='auto', period=1)
在每个训练期之后保存模型。filepath 可以包括命名格式选项,可以由 epoch 的值和 logs 的键(由 on_epoch_end 参数传递)来填充。
例如:
参数
- filepath: 字符串,保存模型的路径, 如果
filepath是weights.{epoch:02d}-{val_loss:.2f}.hdf5, 那么模型被保存的的文件名就会有训练轮数和验证损失。 - monitor: 被监测的数据,损失函数或者准确率
- verbose: 详细信息模式,0 或者 1 ,输出结果打印
- save_best_only: 如果
save_best_only=True, 被监测数据的最佳模型就不会被覆盖,只保留最好的 - mode: {auto, min, max} 的其中之一。 如果
save_best_only=True,那么是否覆盖保存文件的决定就取决于被监测数据的最大或者最小值。 对于val_acc,模式就会是max,而对于val_loss,模式就需要是min,等等。 在auto模式中,方向会自动从被监测的数据的名字中判断出来。 - save_weights_only: 如果 True,那么只有模型的权重会被保存 (
model.save_weights(filepath)), 否则的话,整个模型会被保存 (model.save(filepath))。 - period: 每个检查点之间的间隔(训练轮数)。
check = ModelCheckpoint('./ckpt/transfer_{epoch:02d}-{val_acc:.2f}.h5',
monitor='val_acc',
save_best_only=True,
save_weights_only=True,
mode='auto',
period=1)
效果
Epoch 1/2
1/13 [=>............................] - ETA: 3:20 - loss: 1.6811 - acc: 0.1562
2/13 [===>..........................] - ETA: 3:01 - loss: 1.5769 - acc: 0.2500
3/13 [=====>........................] - ETA: 2:44 - loss: 1.4728 - acc: 0.3958
4/13 [========>.....................] - ETA: 2:27 - loss: 1.3843 - acc: 0.4531
5/13 [==========>...................] - ETA: 2:14 - loss: 1.3045 - acc: 0.4938
6/13 [============>.................] - ETA: 1:58 - loss: 1.2557 - acc: 0.5156
7/13 [===============>..............] - ETA: 1:33 - loss: 1.1790 - acc: 0.5759
8/13 [=================>............] - ETA: 1:18 - loss: 1.1153 - acc: 0.6211
9/13 [===================>..........] - ETA: 1:02 - loss: 1.0567 - acc: 0.6562
10/13 [======================>.......] - ETA: 46s - loss: 1.0043 - acc: 0.6875
11/13 [========================>.....] - ETA: 31s - loss: 0.9580 - acc: 0.7159
12/13 [==========================>...] - ETA: 15s - loss: 0.9146 - acc: 0.7344
13/13 [==============================] - 249s 19s/step - loss: 0.8743 - acc: 0.7519 - val_loss: 0.3906 - val_acc: 0.9000
Epoch 2/2
1/13 [=>............................] - ETA: 2:56 - loss: 0.3862 - acc: 1.0000
2/13 [===>..........................] - ETA: 2:44 - loss: 0.3019 - acc: 1.0000
3/13 [=====>........................] - ETA: 2:35 - loss: 0.2613 - acc: 1.0000
4/13 [========>.....................] - ETA: 2:01 - loss: 0.2419 - acc: 0.9844
5/13 [==========>...................] - ETA: 1:49 - loss: 0.2644 - acc: 0.9688
6/13 [============>.................] - ETA: 1:36 - loss: 0.2494 - acc: 0.9688
7/13 [===============>..............] - ETA: 1:24 - loss: 0.2362 - acc: 0.9732
8/13 [=================>............] - ETA: 1:10 - loss: 0.2234 - acc: 0.9766
9/13 [===================>..........] - ETA: 58s - loss: 0.2154 - acc: 0.9757
10/13 [======================>.......] - ETA: 44s - loss: 0.2062 - acc: 0.9781
11/13 [========================>.....] - ETA: 29s - loss: 0.2007 - acc: 0.9801
12/13 [==========================>...] - ETA: 14s - loss: 0.1990 - acc: 0.9792
13/13 [==============================] - 243s 19s/step - loss: 0.1923 - acc: 0.9809 - val_loss: 0.1929 - val_acc: 0.9300
关于:ImageDataGenerator
图片的数据集太少,进行随机变化增加数据集数量
API详细参数为
- keras.preprocessing.image.ImageDataGenerator()
- zca_whitening=False,: zca白化的作用是针对图片进行PCA降维操作,减少图片的冗余信息
- rotation_range=30:默认0, 旋转角度,在这个角度范围随机生成一个值
- width_shift_range=0.2:默认0,水平平移
- height_shift_range=0.2,默认0, 垂直平移
- shear_range=0.2,# 平移变换
- horizontal_flip=True:水平翻转
官方给定开启上面参数默认角度值以及0.2的值,比较合适,这里的参数没有固定的大小
3.1.2 数据增强的作用
3.1.2.1 预处理需求
- 目的:
- 在图像的深度学习中,对输入数据进行数据增强(Data Augmentation),为了丰富图像训练集,更好的提取图像特征,泛化模型(防止模型过拟合)。
- 还有一个最根本的目的就是要把图片变成符合大小要求
- RCNN输入图片没有要求,但是网络当中卷积之前需要227 x 227大统一大小
- YOLO算法:输入图片大小变换为448 x 448
- SSD算法:输入图片大小变换为300 x 300
3.1.2.2 数据增强
指通过剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小。

即使卷积神经网络被放在不同方向上,卷积神经网络对平移、视角、尺寸或照度(或以上组合)保持不变性,都会认为是一个物体。
3.1.2.3 为什么这样做?

假设数据集中的两个类。左边的代表品牌A(福特),右边的代表品牌B(雪佛兰)。
假设完成了训练,并且输入下面的图像(品牌A),但是你的神经网络输出认为它是品牌B的汽车!
为什么会发生这种现象? 因为算法可能会寻找区分一个类和另一个类的最明显特征。在这个例子中 ,这个特征就是所有品牌A的汽车朝向左边,所有品牌B的汽车朝向右边。神经网络的好坏取决于输入的数据。
怎么解决这个问题?
我们需要减少数据集中不相关特征的数量。对上面的汽车类型分类器来说,你只需要将现有的数据集中的照片水平翻转,使汽车朝向另一侧。现在,用新的数据集训练神经网络,通过过增强数据集,可以防止神经网络学习到不相关的模式,提升效果。(在没有采集更多的图片前提下)
3.1.2.4 数据增强类别
那么我们应该在机器学习过程中的什么位置进行数据增强?在向模型输入数据之前增强数据集。
- 离线增强。预先进行所有必要的变换,从根本上增加数据集的规模(例如,通过翻转所有图像,保存后数据集数量会增加2倍)。
- 在线增强,或称为动态增强。可通过对即将输入模型的小批量数据的执行相应的变化,这样同一张图片每次训练被随机执行一些变化操作,相当于不同的数据集了。
那么我们的代码中也是进行这种在线增强。
3.1.2.5 数据增强技术
下面一些方法基础但功能强大的增强技术,目前被广泛应用。
- 翻转:tf.image.random_flip_left_right
- 你可以水平或垂直翻转图像。一些架构并不支持垂直翻转图像。但,垂直翻转等价于将图片旋转180再水平翻转。下面就是图像翻转的例子。

从左侧开始分别是:原始图像,水平翻转图像,垂直翻转图像
- 旋转:rotate

从左到右,图像相对于前一个图像顺时针旋转90度
- 剪裁:random_crop
- 随机从原始图像中采样一部分,然后将这部分图像调整为原始图像大小。这个方法更流行的叫法是随机裁剪。

从左侧开始分别为:原始图像,从左上角裁剪出一个正方形部分,然后从右下角裁剪出一个正方形部分。剪裁的部分被调整为原始图像大小。
- 平移、缩放等等方法
数据增强的效果是非常好的,比如下面的例子,绿色和粉色表示没有数据增强之前的损失和准确率效果,红色和蓝色表示数据增强之后的损失和准确率结果,可以看到学习效果也改善较快。

那么TensorFlow 官方源码都是基于 vgg与inception论文的图像增强介绍,全部通过tf.image相关API来预处理图像。并且提供了各种封装过tf.image之后的API。那么TensorFlow 官网也给我们提供了一些模型的预处理(数据增强)过程。
网址:https://github.com/tensorflow/models/tree/master/research/slim/preprocessing