1. 卷积神经网络概念
卷积神经网络(CNN)是一种前馈神经网络,它由若干卷积层和池化层组成,尤其在图像处理方面CNN的表现十分出色。
1962年,Hubel和Wiesel通过对猫脑视觉皮层的研究,首次提出了一种新的概念“感受野”,感受野是卷积神经网络每一层输出的特征图(feature map)上的像素点在输入图片上映射的区域大小。再通俗点的解释是,特征图上的一个点对应输入图上的区域。
1989年,LeCun结合反向传播算法与权值共享的卷积神经层发明了卷积神经网络,并首次将卷积神经网络成功应用到美国邮局的手写字符识别系统中。1998年,LeCun 提出了卷积神经网络的经典网络模型LeNet-5,并再次提高手写字符识别的正确率。
CNN的基本结构由输入层、卷积层、池化层、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。
2. 卷积神经网络的特点
卷积神经网络由多层感知机(MLP)演变而来,由于其具有局部连接、权值共享、降采样的结构特点,使得卷积神经网络在图像处理领域表现出色。卷积神经网络相比于其他神经网络的特殊性主要在于权值共享与局部连接两个方面。
2.1 局部连接
在传统的神经网络结构中,神经元之间的连接是全连接的,即 n-1 层的神经元与 n 层的所有神经元全部连接。但是在卷积神经网络中,n-1 层与 n 层的部分神经元连接。

图1:全连接(左图)与局部连接(右图)的对比示意图
“局部连接”的意思实际就是,可以使用卷积核来获得一个局部(如 3 × 3 3 \times 3 3×3区域)的特征:
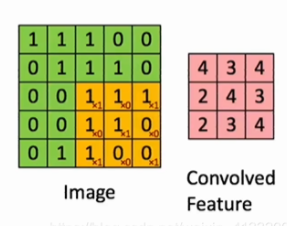
2.2 权值共享
在卷积神经网络中,卷积层中的卷积核类似于一个滑动窗口,在整个输入图像中以特定的步长来回滑动,经过卷积运算之后,从而得到输入图像的特征图,这个特征图就是卷积层提取出来的局部特征,而这个卷积核是共享参数的。在整个网络的训练过程中,包含权值的卷积核也会随之更新,直到训练完成。
其实权值共享就是整张图片在使用同一个卷积核内的参数。比如一个 3 × 3 × 1 3 \times 3 \times 1 3×3×1的卷积核,这个卷积核内9个的参数被整张图片共享,而不会因为图像内位置的不同而改变卷积核内的权系数。
权值共享的优点:
- 大大减少了卷积核中的参数数量(因为只需要一个相同的卷积核来回移动),降低了网络的复杂度。
- 传统的神经网络和机器学习方法需要对图像进行复杂的预处理提取特征,将得到特征再输入到神经网络中。而加入卷积操作就可以利用图片空间上的局部相关性,自动的提取特征。
一般情况,卷积层会有多个卷积核,对应多个通道。这是因为权值共享意味着每一个卷积核只能提取到一种特征,为了增加CNN的表达能力,需要设置多个卷积核。
2.3 降采样 (池化)
降采样是卷积神经网络的另一重要概念,通常也称之为池化(Pooling)。最常见的方式有最大值池化(max pooling)、最小值池化(min pooling)、平均值池化(average pooling)。池化的好处是降低了图像的分辨率,整个网络也不容易过拟合。

3. 卷积神经网络的结构
一个卷积神经网络模型一般由若干个卷积层、池化层和全连接层组成。
- 卷积层的作用是提取图像的特征;
- 池化层的作用是对特征进行抽样,可以使用较少训练参数,同时还可以减轻网络模型的过拟合程度。
- 网络的最后一般为1~2层全连接层,全连接层负责把提取的特征图连接起来
- 最后通过分类器得到最终的分类结果。
4. NLP中的卷积神经网络
4.1 一个简单的例子
对于一个句子"tentative deal reached to keep government open", 我们把每个词都用4维的dense vector来表示,并随机初始化一个大小为3的卷积核。

将这个卷积核从上到下移动,这样每次就能够提取到3-gram的局部特征:

但是这种卷积方法有一个坏处,那就是卷积之后的feature map变小了!原来的句子长度为7,卷积之后长度只有5.这会带来一些麻烦,所以我们可以对原来的句子进行0-padding,就像这样:
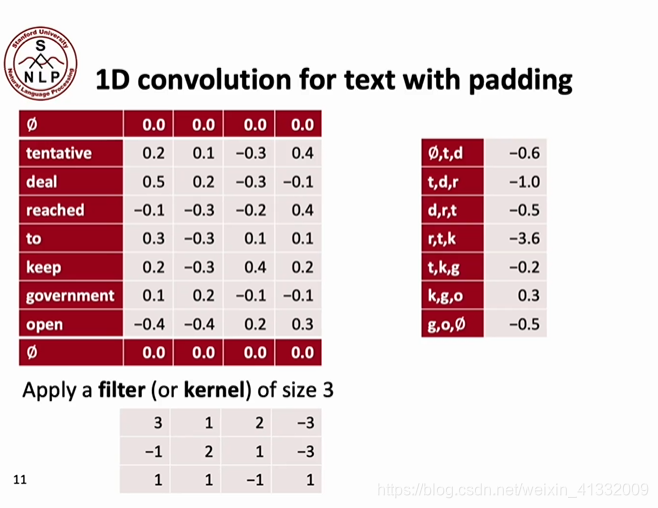
可以看出,经过0-padding之后,卷积后句子的长度依然是7。
到目前为止,我们只使用了一个卷积核,也就是只提取了一种特征。在实际应用中,我们经常需要提取多种特征,这就需要我们使用多个卷积核。下面这个例子中,我们使用了3个不同的卷积核来提取三种不同的特征:
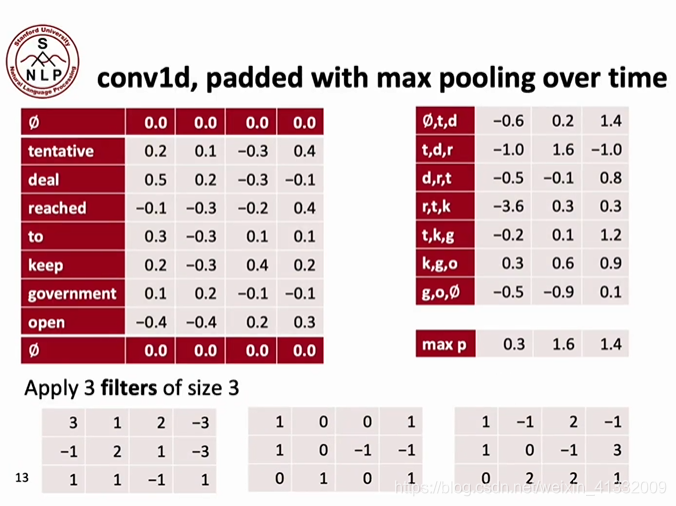
值得注意的点是,每个卷积核在backprop的过程中,会自己去学习一种特征。例如,卷积核1学习的特征可能是:这句话是不是有礼貌的?(is this sentence polite?); 卷积核2学习的特征可能是:这个句子是不是关于食物的?卷积核3学习的特征可能是:这个句子是不是积极的(positive)?
我们用这三个卷积核分别提取句子的特征,这就构成了3个channel。下面,我们使用max-pooling, 选取每个channel最大的那个值,得到 0.3, 1.6, 1.4。这说明,这句话中似乎没有特别礼貌的部分、但是包含食物,也包含积极的部分。
值得注意的是,在解决文本问题的CNN中,使用max-pooling是合理的。这是因为文本具有稀疏性(sparsity),如果要判断一个句子是否是有礼貌的,只有一处有礼貌就可以判断出它是有礼貌的(比如说有一块说了“would you please”),毕竟没有人可以在句子的每一处都有礼貌!
除了max-pooling,还有一种做法是使用average-pooling,这种方法就是将整体的特征的值做一个平均了,可以把握住整个句子的平均语义。另一种方法是k-max pooling,就是取前k个最大的值。

还有一种在图像领域经常用到的pooling方法:
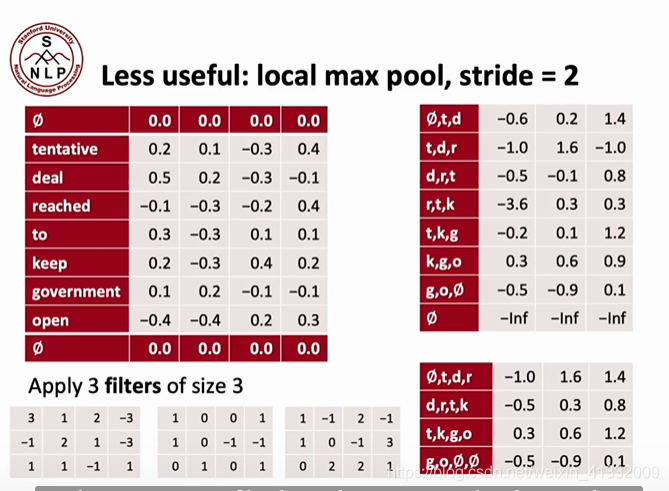
4.2 文本分类问题
4.2.1 FastText
fastText 是 word2vec 的作者 Mikolov 转战 Facebook 后发表的一篇论文 Bag of Tricks for Efficient Text Classification。把 fastText 放在此处并非因为它是文本分类的主流做法,而是它极致简单,模型图见下:
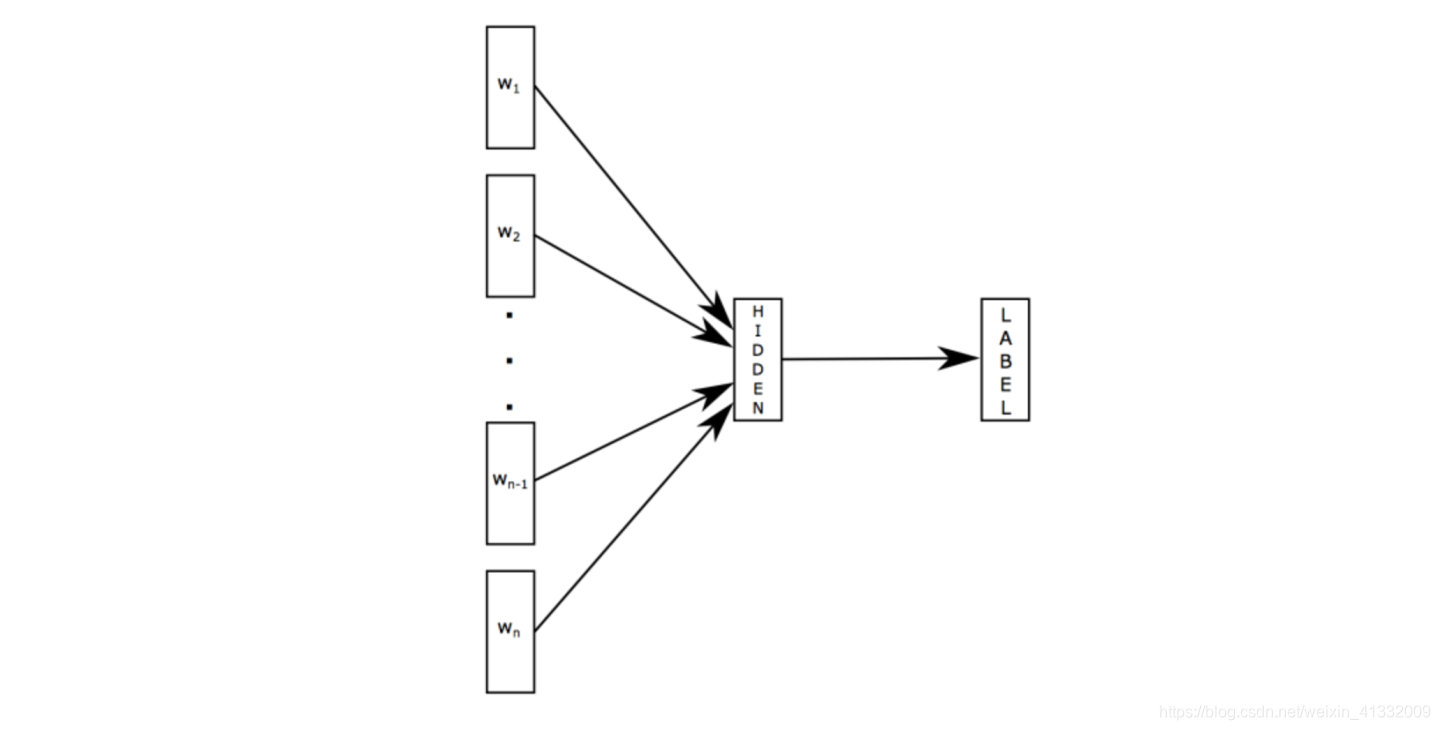
原理是把句子中所有的词向量进行平均(某种意义上可以理解为只有一个avg pooling特殊CNN),然后直接接 softmax 层。其实文章也加入了一些 n-gram 特征的 trick 来捕获局部序列信息。文章倒没太多信息量,算是“水文”吧,带来的思考是文本分类问题是有一些“线性”问题的部分,也就是说不必做过多的非线性转换、特征组合即可捕获很多分类信息,因此有些任务即便简单的模型便可以搞定了。
4.2.2. TextCNN
fastText 中的网络结构是完全没有考虑词序信息的,而它用的 n-gram 特征 trick 恰恰说明了局部序列信息的重要意义。卷积神经网络核心点在于可以捕捉局部相关性,具体到文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个 1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
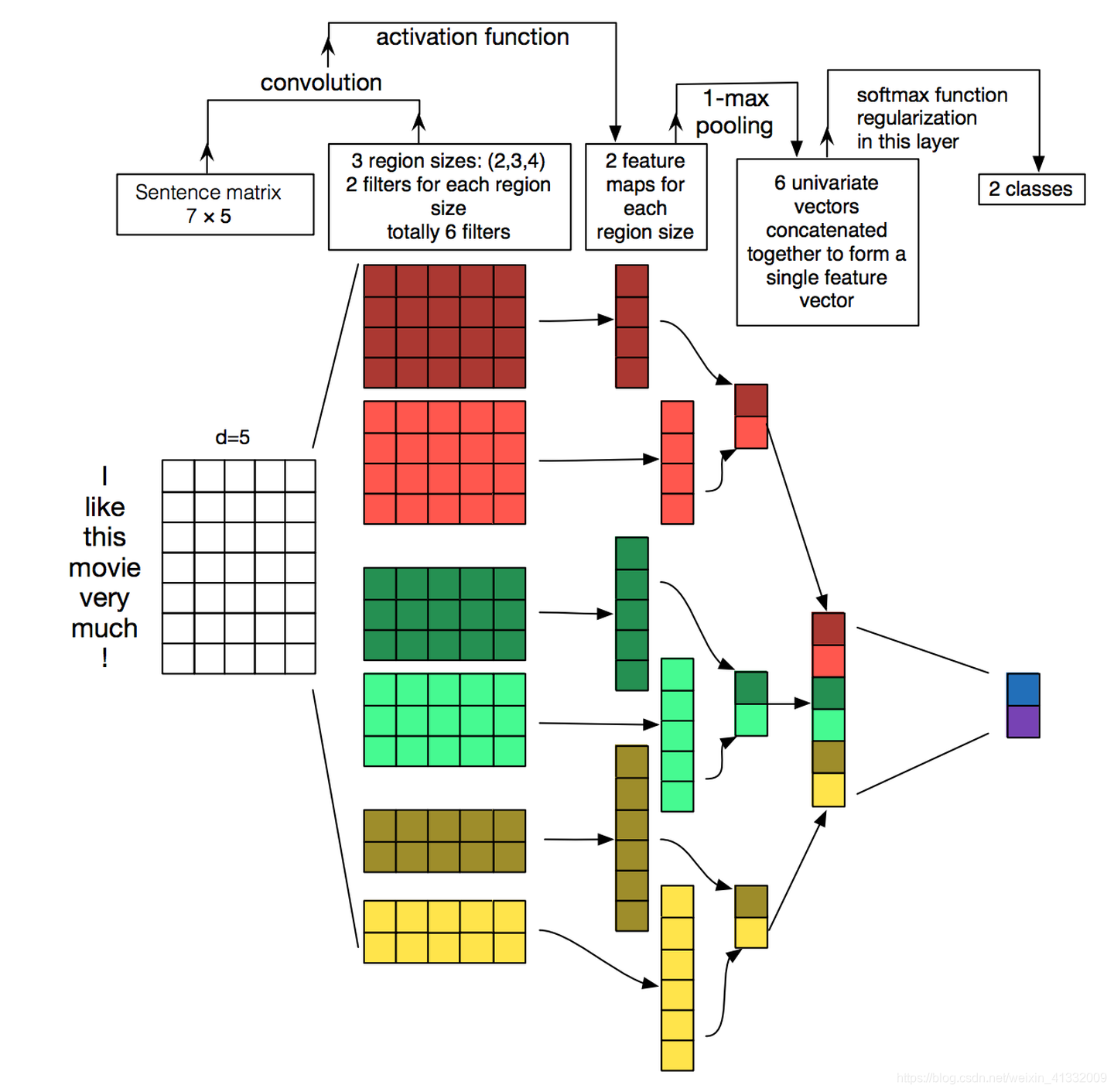
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道:图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“我觉得这个地方景色还不错,但是人也实在太多了”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
4.2.3 residual block
Residual Block: 增加一个skip-connection。学习F(x)相当于拟合残差。
highway: 类似LSTM的思想(more LSTM-ish), 增加了T门和C门,但其实它的表达能力和Residual Block是一样的。
4.2.4 全连接层
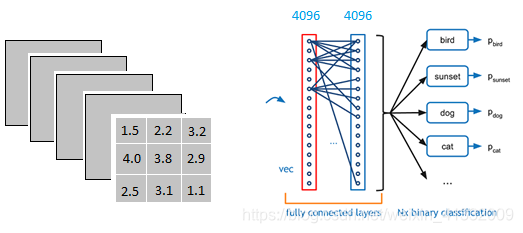
以上图为例,我们仔细看上图全连接层的结构。全连接层中的每一层是由许多神经元组成的( 1 × 4096 1 \times 4096 1×4096)的平铺结构。为了将 3 × 3 × 5 3 \times 3 \times 5 3×3×5的输出变成 1 × 4096 1 \times 4096 1×4096, 我们需要用一个 3 × 3 × 5 × 4096 3 \times 3 \times 5 \times 4096 3×3×5×4096的卷积层去卷积激活函数的输出。
这一步卷积一个非常重要的作用,就是把分布式特征表示映射到样本标记空间,意思就是说我们把所有的特征都整合在一起。
在这个例子中,全连接层有两层平铺结构。这是因为全连接层中一层的一个神经元就可以看成一个多项式,我们需要用许多神经元去拟合数据分布。但是只用一层有时候没法解决非线性问题,而如果有两层或以上全连接层,就可以很好地解决非线性问题了。(想想泰勒公式)
目前由于全连接层参数冗余(仅全连接层参数就可占整个网络参数80%左右),近期一些性能优异的网络模型如ResNet和GoogLeNet等均用全局平均池化(global average pooling)取代全连接来融合学到的深度特征,最后仍用softmax等损失函数作为网络目标函数来指导学习过程。需要指出的是,用GAP替代全连接的网络通常有较好的预测性能。
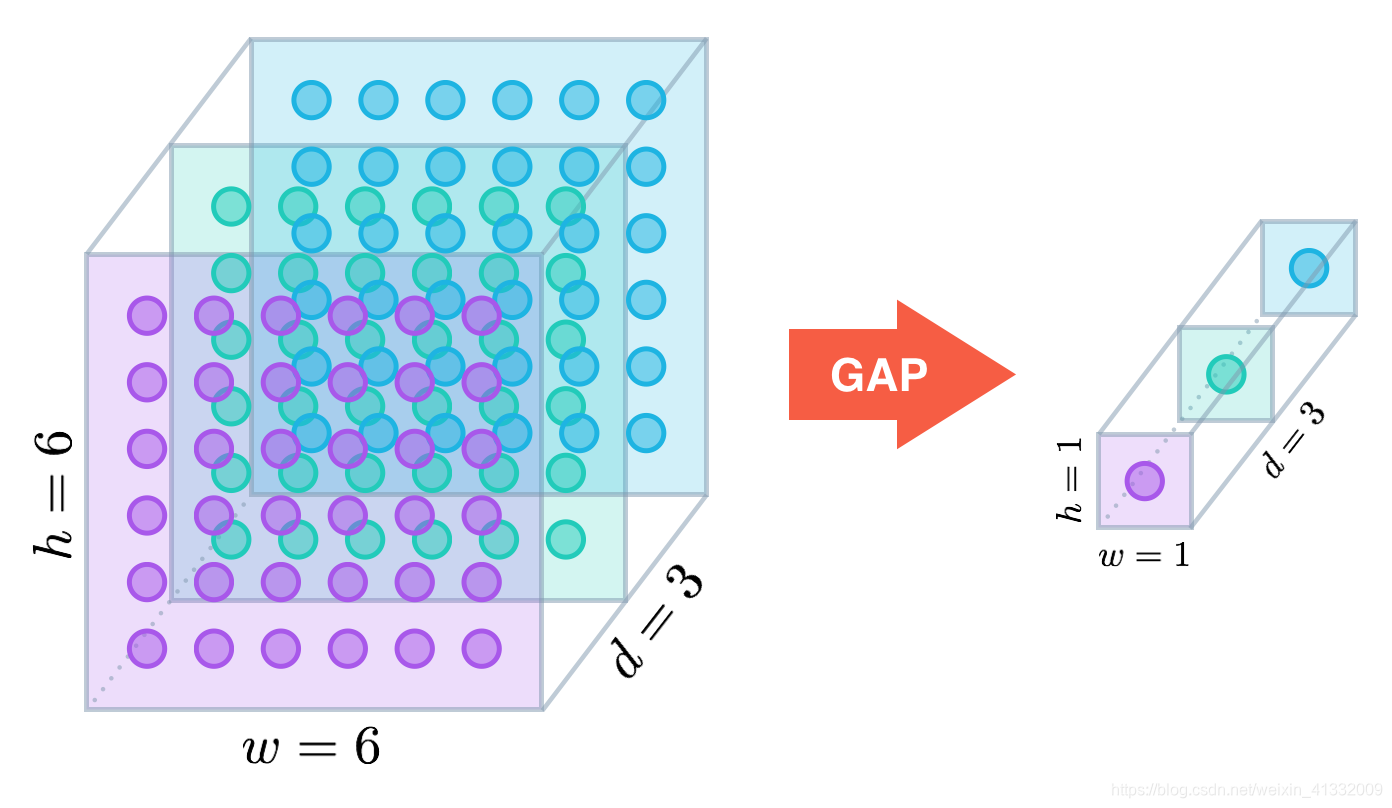
1 × 1 1 \times 1 1×1 卷积核
乍一看, 1 × 1 1 \times 1 1×1的卷积核好像并没有意义?但实际上,它是有意义的! 1 × 1 1 \times 1 1×1的卷积核可以将很多个channel的输出变成一个channel,相当于在多个channel之间做了一个全连接 (a fully connected linear layer across channels)。
这里通过一个例子来直观地介绍 1 × 1 1 \times 1 1×1卷积。输入 6 × 6 × 1 6 \times 6 \times 1 6×6×1的矩阵,这里的 1 × 1 1 \times 1 1×1卷积形式为 1 × 1 × 1 1 \times 1 \times 1 1×1×1,即为元素2,输出也是 6 × 6 × 1 6 \times 6 \times 1 6×6×1的矩阵。但输出矩阵中的每个元素值是输入矩阵中每个元素值 × 2 \times 2 ×2的结果。

上述情况,并没有显示1x1卷积的特殊之处,那是因为上面输入的矩阵channel为1,所以1x1卷积的channel也为1。
让我们看一下真正work的示例。当输入为6x6x32时,1x1卷积的形式是1x1x32。此时便可以体会到1x1卷积的实质作用:降维。当1x1卷积核的个数小于输入channels数量时,即降维。
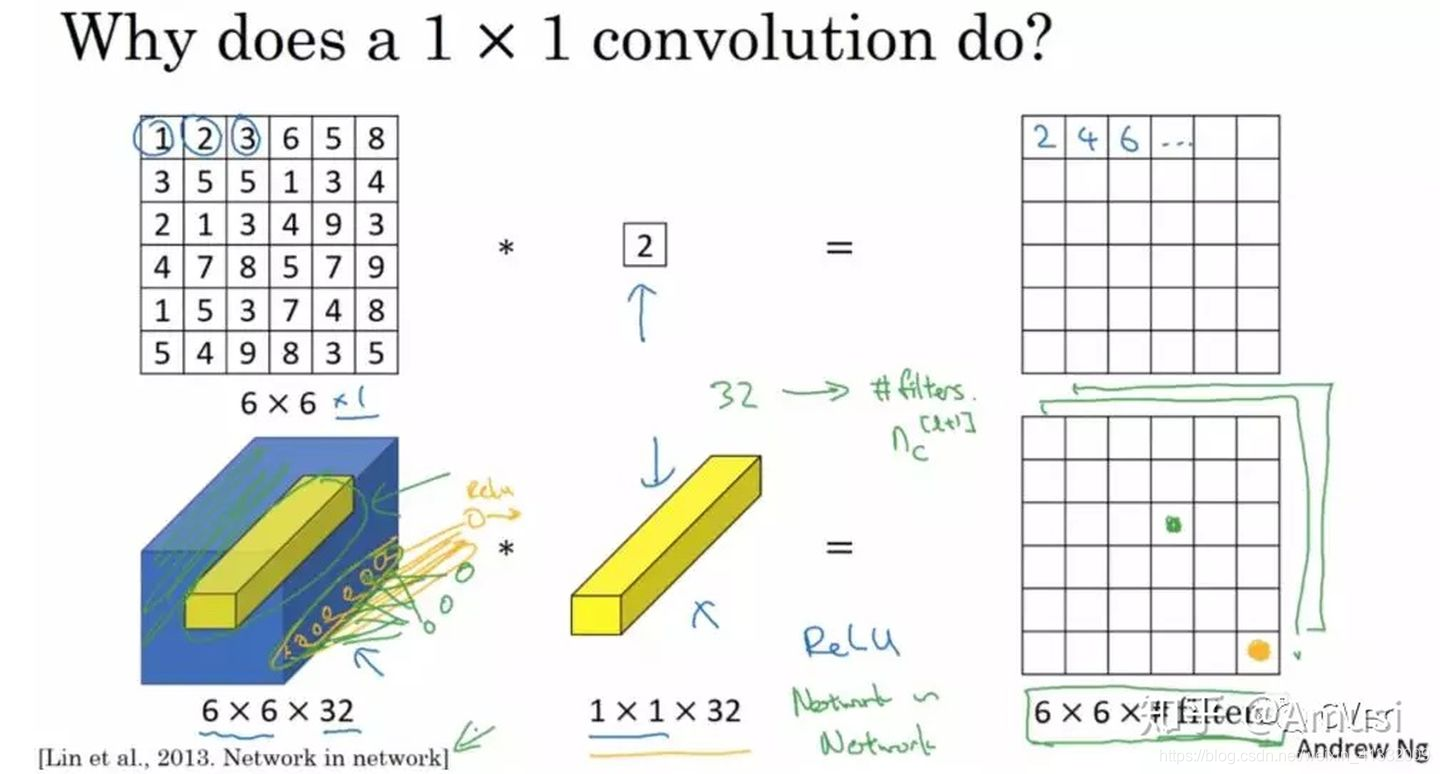
注:1x1卷积一般只改变输出通道数(channels),而不改变输出的宽度和高度

一些思考
1. 在实际应用中,我们会遇到各种各样的数据集和问题,那么什么样的数据集适合使用深度学习,什么不适合呢?
我认为,当数据集没有局部相关性,就不适于使用深度学习算法进行处理,而适用于用普通的统计机器学习方法处理。举个例子:预测一个人的健康状况,相关的参数会有年龄、职业、收入、家庭状况等各种元素,将这些元素打乱,并不会影响相关的结果。
目前深度学习表现比较好的领域主要是图像\语音\自然语言处理等领域,这些领域的一个共性是局部相关性。图像中像素组成图片,文本中单词组合成句子,这些特征元素的组合一旦被打乱,表示的含义同时也被改变。CNN抓住此共性的手段主要有四个:局部连接、权值共享、池化操作。
- 局部连接使网络可以提取数据的局部特征
- 权值共享大大降低了网络的训练难度,一个Filter只提取一个特征,在整个图片(或者文本) 中进行卷积
- 池化操作实现了数据的降维,将低层次的局部特征组合成为较高层次的特征,从而对整个图片进行表示。
参考资料
[1] Stanford cs224n lec11
[2] https://zhuanlan.zhihu.com/p/25928551
[3] https://zhuanlan.zhihu.com/p/33841176