前几天写了一个爬虫,用来爬伯乐在线的python版块的文章。其实这个爬虫只是保存网页而已,因为伯乐在线的文章既有图片又有代码,爬主要部分的话排版很难看,不如直接把网页保存下来。
然后这两天就在看python的一个轻量级爬虫框架–scrapy,并尝试用scrapy写爬虫。一开始觉得毫无头绪,后来慢慢就觉得挺好使的。但是好使归好使,就是不知道性能如何?于是就用scrapy也写一个爬虫来爬伯乐在线的文章,然后做一个对比。
自己写的爬虫-jobbole.py
因为自己用写爬虫接触多线程的时候,看到贴吧的一个人写的爬虫用到的是multiprocessing.dummy.Pool,然后就去用了一下,发现这个Pool真好用,于是基本上我写的每个爬虫都会用到Pool。其用法是:
from multiprocessing.dummy import Pool
pool=Pool(10)#10代码线程数
#定义一个函数
def run(num):
print num**2
num_list=[1,2,3,4,5,6,7,8,9,10]
pool.map(run,num_list) #运行
#关闭线程
pool.close()
pool.join()上面的就是基本用法,简单高效。
然后这里写的爬虫也是用这种方法。
爬虫分两步:
- 第一步:解析每一页如http://python.jobbole.com/all-posts/page/2/的网页,把文章的链接解析出来。
第二步:解析文章页(其实这里没有解析,因为是直接保存网页),并把内容保存为.html格式。
详细代码如下:
import re
import requests as req
from multiprocessing.dummy import Pool
import time
class DownloadArticle():
def __init__(self):
self.url='http://python.jobbole.com/all-posts/page/'
self.article_list=[]
self.savepath='D:/python/jobbole/articles/'
self.errorUrl={}
def parseArticleUrl(self,page):
global article_list
url=self.url+str(page)
s=req.get(url)
#<a target="_blank" href="http://python.jobbole.com/81896/" title="
art_re=re.compile('<a target=.*?href="(http://python.*?\d{3,5}/)" title=')
au=art_re.findall(s.content)
s.close()
self.article_list.extend(au)
def saveArticle(self,url):
global errorUrl
s=req.get(url)
title=(re.findall('<title>(.*?) -.*?</title>',s.content)[0]).decode('utf-8').encode(type_)
try:
for item in ['/',':','?','<','>']:
title=title.replace(item,' ')
f=open(r'%s%s.html'%(self.savepath,title),'w')
f.write(s.content)
f.close()
except:
self.errorUrl[title]=url
print 'error'
def run(self):
pool=Pool(20)
st=time.time()
#step 1
pages=range(1,21)
pool.map(self.parseArticleUrl,pages)
print 'step 1 finished! cost time:%fs'%(time.time()-st)
st1=time.time()
#step 2
pool.map(self.saveArticle,self.article_list)
print 'step 2 finished! cost time:%fs'%(time.time()-st1)
#finish
pool.close()
pool.join()
print 'all articles downloaded! cost time:%fs'%(time.time()-st)
if __name__=='__main__':
print 'articles begin download!'
d=DownloadArticle()
d.run()
运行结果:

总共花了8.65秒,扫了20页的文章,这速度还是挺快的了!
用scrapy写的爬虫
scrapy的基本知识就不介绍了,可以看官方文档。
先是打开cmd,然后cd命令切换到工作目录,输入:
scrapy startproject jobbole
其中jobbole是你给这个项目取得名字。
然后在工作目录下就会产生一个目录,其结构是这样的:
jobbole
|– jobbole
| |–spyders
| | |– init.py
| |
| |– init.py
| |– items.py
| |– pipelines.py
| |– settings.py
|
|– scrapy.cfg
- items.py用于设置要爬取的内容。
- pipelines.py用于处理爬取的数据,比如查重、清洗、储存。
- settings.py用于设置。。。
- 还要在spiders创建一个spider.py。
就一一来看分别怎么设置把。
- items.py
import scrapy
class JobboleItem(scrapy.Item):
title=scrapy.Field()
content=scrapy.Field()很简单,就这么几句,其中前两句还是固定的,而title、content就是我要爬取的内容,一个是文章标题,还有一个是文章主题–这里的话就是整个网页。
- spiders文件夹下的spider:JobSpider.py
# -*- coding: utf-8 -*-
"""
Created on %(date)s
@author: %(c.yingxian)s
"""
import sys
type_ = sys.getfilesystemencoding()
reload(sys)
sys.setdefaultencoding('utf-8')
from scrapy.spiders import Spider
from scrapy.linkextractors import LinkExtractor
from scrapy.http import Request
from jobbole.items import JobboleItem
from scrapy.selector import Selector
class Jobspider(Spider):
page_link=set()#
content_link=set()#这两个set集合适用于下面去重复链接的。
name='jobbole'#名字很重要,需要记住!
allowed_domain=['jobbole.com']#允许的域名,只允许在这个域名爬
#开始域名--也就是从哪里开始
start_urls=['http://python.jobbole.com/all-posts/']
#制定网页提取规则。第一个是用来"翻页"的,第二个是用来查找文章链接的
rules={'page':LinkExtractor(allow=('http://python.jobbole.com/all-posts/page/\d+/')),
'content':LinkExtractor(allow=('http://python.jobbole.com/\d+/'))}
#start_urls的网址会第一个传到parse()
def parse(self,response):
for link in self.rules['page'].extract_links(response):
#对于找到的每一个页链接,如果不在set中就加入并解析
if link.url not in self.page_link:
self.page_link.add(link.url)
yield Request(link.url,callback=self.parse_page)
#对于每一个文章链接,如果不在content_link集合中就加入并解析
for link in self.rules['content'].extract_links(response):
if link.url not in self.content_link:
self.content_link.add(link.url)
yield Request(link.url,callback=self.parse_content)
#用于解析每一页网页并找到文章链接
def parse_page(self,response):
for link in self.rules['page'].extract_links(response):
if link.url not in self.page_link:
self.page_link.add(link.url)
yield Request(link.url,callback=self.parse_page)
for link in self.rules['content'].extract_links(response):
if link.url not in self.content_link:
self.content_link.add(link.url)
yield Request(link.url,callback=self.parse_content)
#解析文章内容,找到标题还有内容
def parse_content(self,response):
item=JobboleItem()
sel=Selector(response)
title=sel.xpath('//title/text()').extract()[0]
item['title']=title
item['content']=response.body
return item#必须要return- pipeline.py
from jobbole.items import JobboleItem
class JobbolePipeline(object):
path='D:/python/scrapy/jobbole/art/'
def process_item(self, item, spider):
title=item['title']
for it in ['/',':','?','<','>']:
title=title.replace(it,' ')
f=open(self.path+title+'.html','w')
f.write(item['content'])
f.close()
return item
pipelines.py这里就不说了,主要是把接收到的数据写出去。
设置完pipelines.py之后还有一个非常重要的事要做,就是在settings.py里设置。
- settings.py
BOT_NAME = 'jobbole'
SPIDER_MODULES = ['jobbole.spiders']
NEWSPIDER_MODULE = 'jobbole.spiders'
ITEM_PIPELINES = {'jobbole.pipelines.JobbolePipeline': 1000,}#前三句都是创建项目的时候就有的,主要要加这句。到这里,一个scrapy爬虫就设置完毕了。
我们到项目根目录,也就是这里
jobbole
|– jobbole <—这个就是根目录
| |–spyders
| | |– init.py
| |
| |– init.py
| |– items.py
| |– pipelines.py
| |– settings.py
|
|– scrapy.cfg
打开cmd运行项目,在cmd输入
scrapy crawl jobbole像这样:
jobbole就是在spider里面设置的名字,还记得吗?
运行结果:
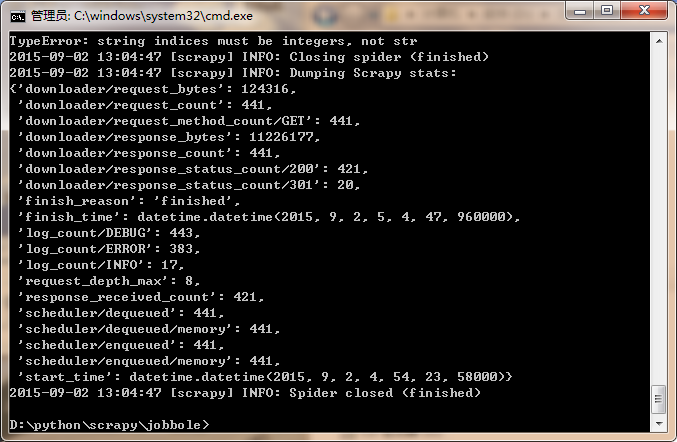
看到运行时间了吗?
运行时间等于【13:04:47-12:54:23】=624秒。
那个start_time就是开始时间,但是它给的时区是GMT-0的时间,也就是格林威治标准时间,而我们在GMT-8时区,因此是4+8=12……
看到了吗?一个8.65秒,一个624秒!!
额,不过我觉得造成这个结果的原因很可能是因为我写的scrapy这算还不够完善,因为我才接触了两天。
好吧,既然是这样就不对比这个时间了!
但是scrapy的好处还是很明显的,那就是写起来很简单(当你了解了其原理之后,当然我还不是很了解。。。)