本文介绍了离群点(孤立点)检测的常见方法,以及应用各种算法时需要注意的问题。
离群点是什么?
异常对象被称作离群点。异常检测也称偏差检测和例外挖掘。孤立点是一个明显偏离与其他数据点的对象,它就像是由一个完全不同的机制生成的数据点一样。
离群点检测是数据挖掘中重要的一部分,它的任务是发现与大部分其他对象显著不同的对象。大部分数据挖掘方法都将这种差异信息视为噪声而丢弃,然而在一些应用中,罕见的数据可能蕴含着更大的研究价值。
离群点检测已经被广泛应用于电信和信用卡的诈骗检测、贷款审批、电子商务、网络入侵、天气预报等领域,如可以利用离群点检测分析运动员的统计数据,以发现异常的运动员。
孤立 点 检 测 在 国 外 获 得 了 广 泛 的 研 究 和 应用, E. M. Knorr 和 R. T. N将孤立点检测用于分析 NHL ( Nationai Hockey League )的 运 动 员 统 计 数据,用来发现表现例外的运动员;
离群点监测所面临的困难和挑战
【1】定义一个正常状态的范围,以覆盖所有可能的正常状态是非常困难的。通常,正常状态和异常状态之间的边界不是非常精确,而是模糊的。因此在边界附近的状态(点)容易被误分。
【2】如果异常来自有敌意的(如黑客或恐怖袭击)行为,那么它会试图看起来和正常的行为一样,因此,区分难度就更大了。
【3】缺乏标记数据来训练/验证异常监测模型,是一个主要的问题。
【4】数据通常含有噪音,含有噪音的数据可能和实际的异常值很相像,这时很难区分噪音/异常值,也很难去除噪音的。
另外还有一些困难,没有一一列举。
由于存在以上的困难,使得异常值检测,通常是不容易处理的。
在实际应用中,许多方法只能解决某一种特定的问题,方法的选择取决于数据的天然特性,标记数据的多寡,异常值的类型等等。
下图是异常值检测相关的技术方法。
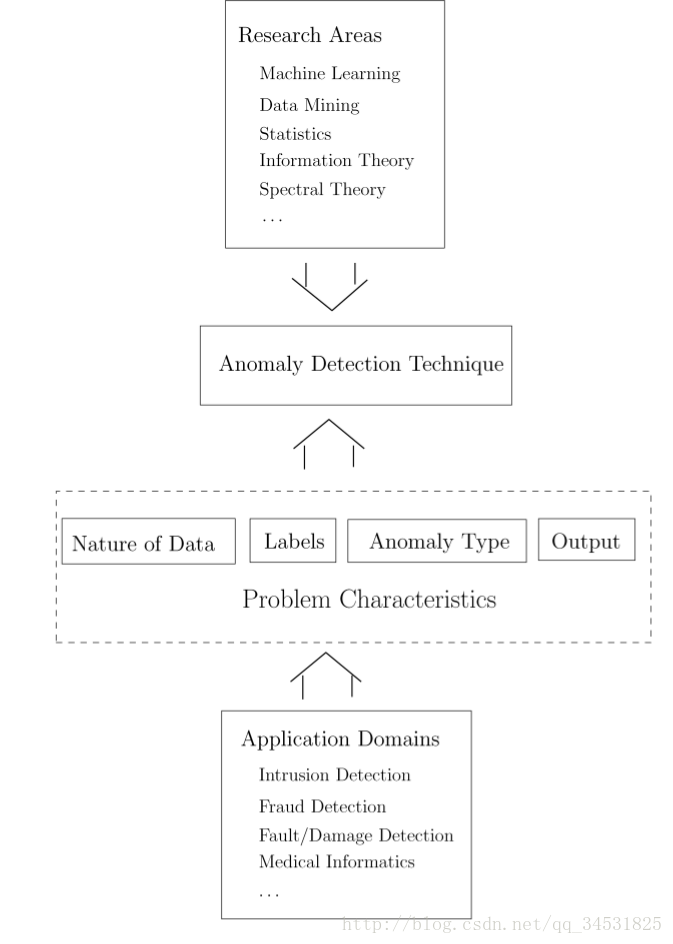
(来自文献9)
按标记数据的多寡确定检测方法
【1】监督学习方法
正常样本和异常样本都有标记:
典型的处理方法是对正常值和异常值这两类分别建立预测模型,预测时进行对比,看预测样本属于哪一类?
不平衡数据处理是关键问题。因为获得标记的异常值样本通常远少于正常值样本。
另外,获得正确的有代表性的标记,尤其是对异常值类通常是困难的,可以对训练集中的正常样本采取一些人工产生异常值的办法【文献10~12】。
A typical approach in such cases is to build a predictive model for normal vs. anomaly classes. Any unseen data instance is compared against the model to determine which class it belongs to.
There are two major issues that arise in supervised anomaly detection.
First, the anomalous instances are far fewer compared to the normal instances in the training data.
Second, obtaining accurate and representative labels, especially for the anomaly class is usually challenging. A number of techniques have been proposed that inject artificial anomalies into a normal data set to obtain a labeled training data set [Theiler and Cai 2003; Abe et al. 2006; Steinwart et al. 2005].
Other than these two issues, the supervised anomaly detection problem is similar to building predictive models.
【2】半监督学习方法
仅正常值样本有标记。
对正常值建立模型,然后用来预测异常值。
【3】无监督学习方法
正常值和异常值样本都没有标记。
理想地假设正常值比异常值样本多得多。一旦不满足这个假设,将会出现非常高的错误预警。
The techniques in this category make the implicit assumption that normal instances are far more frequent than anomalies in the test data. If this assumption is not true then such techniques suffer from high false alarm rate.
(文献9)
常用的异常值检测方法概述
【1】基于统计模型的方法:首先建立一个数据模型,异常是那些同模型不能完美拟合的对象;如果模型是簇的集合,则异常是不显著属于任何簇的对象;在使用回归模型时,异常是相对远离预测值的对象。
【2】基于邻近度的方法:通常可以在对象之间定义邻近性度量,异常对象是那些远离其他对象的对象。
【3】基于密度的方法:仅当一个点的局部密度显著低于它的大部分近邻时才将其分类为离群点。
【4】基于聚类的方法:聚类分析用于发现局部强相关的对象组,而异常检测用来发现不与其他对象强相关的对象。因此,聚类分析非常自然的可以用于离群点检测。
基于统计模型的方法
基于分布(概率模型)的假设检验的方法:
给定的数据集假设了一个分布或概率模型(例如一个正态分布),然后采用不一致性检验来确定离群点。要求预先知道数据的分布和分布的参数(例如均值和方法)。
根据问题的需要对所研究的总体作某种假设,记作H0;选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;由实测的样本,计算出统计量的值,并根据预先给定的显著性水平进行检验,作出拒绝或接受假设H0的判断。常用的假设检验方法有u—检验法、t检验法、χ2检验法(卡方检验)、F—检验法,秩和检验等。
如何通俗理解假设检验
http://mt.sohu.com/it/d20170319/129357584_609133.shtml
需要注意的地方:
(1)绝大多数检验是针对单个属性的,而许多数据挖掘问题要求在多维空间中发现离群点。
(2)要求一些要求关于数据集合参数的知识:如数据分布。观察到的分布需要用恰当的用一个标准分布来模拟。
离群点具有低概率。这种情况的前提是必须知道数据集服从什么分布,如果估计错误就造成了重尾分布。
关于重尾分布,可参考:
https://wenku.baidu.com/view/208864738e9951e79a892705.html
基于簇的离群点检测
模型是簇,则异常是不显著属于任何簇的对象。
需要注意的是:
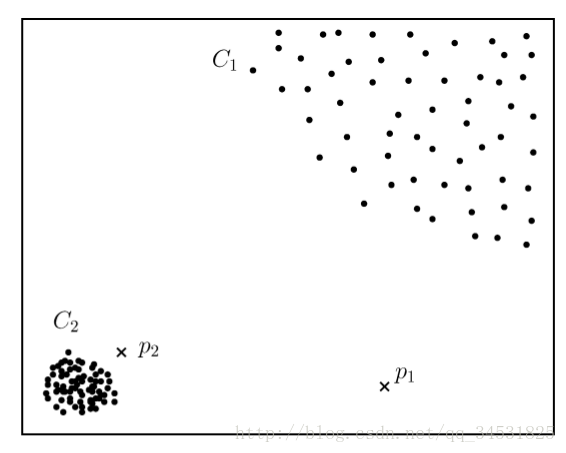
传统的观点都认为孤立点是一个单独的点,然而很多的现实情况是异常事件具有一定的时间和空
间的局部性,这种局部性会产生一个小的簇.这时候离群点(孤立点)实际上是一个小簇(图下图的C1和C3)。

(来自文献2)
基于回归模型的离群点检测
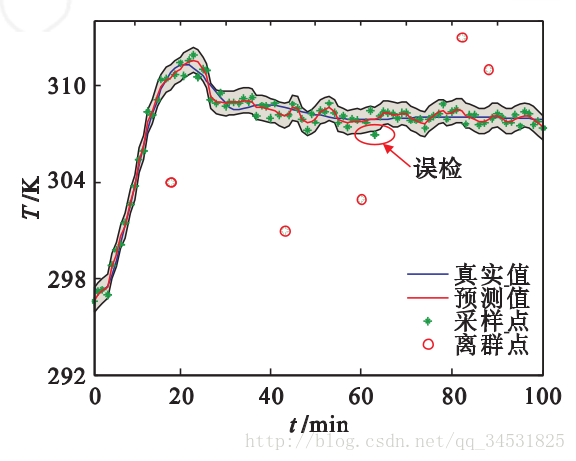
(来自文献3,对,反应釜中温度的相关过程数据用于算法测试 . 对于反应釜中的温度 ,利用温度传感器 , 每隔 1 min对其进行采样 . 同时 , 上述过程数据中还包含了测量噪声 .)
应用时需要注意的地方:
(1)由于有离群点的存在,在建立模型时,需要建立一个鲁棒预测模型。
防止出现过拟合现象,非鲁棒性预测模型尽管该能够检测出全部离群点 , 但同时也会出现了误检的情况 , 随着测量噪声的进一步加大 , 误检或漏检的问题也将更加突出 。
(2)需要选择合适的阈值。
优缺点分析
文献9中的分析如下:
Advantages and Disadvantages of Statistical Techniques. The advantages of statistical techniques are:
(1) If the assumptions regarding the underlying data distribution hold true, statistical techniques provide a statistically justifiable solution for anomaly detection.
(2) The anomaly score provided by a statistical technique is associated with a confidence interval, which can be used as additional information while making a decision regarding any test instance.
(3) If the distribution estimation step is robust to anomalies in data, statistical techniques can operate in a unsupervised setting without any need for labeled training data.
The disadvantages of statistical techniques are:
(1) The key disadvantage of statistical techniques is that they rely on the assumption that the data is generated from a particular distribution. This assumption often does not hold true, especially for high dimensional real data sets.
(2) Even when the statistical assumption can be reasonably justified, there are several hypothesis test statistics that can be applied to detect anomalies; choosing the best statistic is often not a straightforward task [Motulsky 1995]. In particular, constructing hypothesis tests for complex distributions that are required to fit high dimensional data sets is nontrivial.
(3) Histogram-based techniques are relatively simple to implement, but a key short- coming of such techniques for multivariate data is that they are not able to capture the interactions between different attributes. An anomaly might have attribute values that are individually very frequent, but whose combination is very rare, however an attribute-wise histogram-based technique would not be able to detect such anomalies.
基于邻近度、距离、相似度的离群点检测
不依赖统计检验,我们可以将基于邻近度的离群点看作是那些没有“足够多“邻居的对象。这里的邻居是用邻近度(距离)来定义的。
最常用的距离是绝对距离(曼哈顿)和欧氏距离等等。
一 般 情况 下 ,在低 维 空间 用距离 来 度量 能效 果较 好 ,但 在 高 维 空 间 中效 果 并 不好 。如 果将 低 维 空 间 中基 于 距 离 问题 的解 决 方法 推广 到 高维 空 间 ,将会 引起 难 以预 料 维度 灾 难 问题 。最 近几 年 有很 多 学者 有 提 出相 似 度 函数(文献5)。

(文献5)
算法基本思想是:查找每个对象o在半径d范围内的邻居数,假设对于一个孤立点来说,在d领域内最多只能有M的邻居,那么对于一个对象x而言,如果发现了M+1邻居,那么x就不是一个孤立点。
考虑算法的计算复杂度,需要进行优化,主要的算法有:基于索引( iDcex - baSec )的算法 ,循环一嵌套( DeStec - ioop , NL )算法 ;基于单元( ceII - based )的算法,详细可参考文献1、4。
需要注意的地方:
不适合大数据集,不能处理具有不同区域密度的数据集。**
基于密度的方法
下面摘自http://blog.sina.com.cn/s/blog_6002b97001014njh.html
离群点是在低密度区域中的对象。一个对象的离群点得分是该对象周围密度的逆。所以我们可以看到基于密度的离群点检测与基于邻近度的离群点检测密切相关,因为密度通常用邻近度定义。
定义密度
一种常用的定义密度的方法是,定义密度为到k个最近邻的平均距离的倒数。如果该距离小,则密度高,反之亦然。另一种密度定义是使用DBSCAN聚类算法使用的密度定义,即一个对象周围的密度等于该对象指定距离d内对象的个数。需要小心的选择d,如果d太小,则许多正常点可能具有低密度,从而具有高离群点得分。如果d太大,则许多离群点可能具有与正常点类似的密度(和离群点得分)。使用任何密度定义检测离群点具有与基于邻近度的离群点方案类似的特点和局限性。特殊地,当数据包含不同密度的区域时,它们不能正确的识别离群点。
定义相对密度
为了正确的识别这种数据集中的离群点,我们需要与对象邻域相关的密度概念,也就是定义相对密度。
常见的有两种方法:(1)使用基于SNN密度的聚类算法使用的方法;(2)用点x的密度与它的最近邻y的平均密度之比作为相对密度。使用相对密度的离群点检测(局部离群点要素LOF技术):首先,对于指定的近邻个数(k),基于对象的最近邻计算对象的密度density(x,k),由此计算每个对象的离群点得分;然后,计算点的邻近平均密度,并使用它们计算点的平均相对密度。这个量指示x是否在比它的近邻更稠密或更稀疏的邻域内,并取作x的离群点得分(这个是建立在上面的离群点得分基础上的)。
方法优缺点:
(1)给出了对象是离群点的定量度量,并且即使数据具有不同的区域(密度分布及不均匀)也能够很好的处理;
(2)参数选择是困难的。虽然LOF算法通过观察不同的k值,然后取得最大离群点得分来处理该问题,但是,仍然需要选择这些值的上下界。
(文献9)
基于聚类的方法
算法核心思想
首先聚类所有的点,对某个待测点评估它属于某一簇的程度。方法是设定一目标函数(例如kmeans法时的簇的误差平方和),如果删去此点能显著地改善此项目标函数,则可以将该点定位为孤立点。
需要注意的是:
基于聚类技术来发现离群点可能是高度有效的,聚类算法产生的簇的质量对该算法产生的离群点的质量影响非常大。
还可以参考文献6。
公开包(算法)
【1】 Seasonal Hybrid ESD笔记 http://blog.csdn.net/huangbo10/article/details/51942006
Twitter异常监测包 AnomalyDetection
STL(Season Trend decomposition using Loess)==>残差项==>Generilized ESD提取离群点。
参考文献
【1】《数据挖掘概念与技术》 第8.9 节 Jiawei Han 著
【2】《基于簇的孤立点检测》 段炼,-,阎保平,李俊
【3】《基于偏鲁棒 M - 回归的间歇过程离群点检测》 贾润达,毛志忠
【4】《基于距离的孤立点检测及其应用》 陆声链,林士敏
【5】《种 基 于 相似 度 量 的 离群 点 检 测 方 法》 孙启林 ,方宏彬 ,张
健 ,刘 明术
【6】http://blog.csdn.net/qq_26591517/article/details/50677889 基于聚类的离群点检测
【8】http://blog.csdn.net/huangbo10/article/details/51942006 Seasonal Hybrid ESD笔记
【9】Anomaly Detection: A Survey VARUN CHANDOLA, ARINDAM BANERJEE, and VIPIN KUMAR 2009
【10】Theiler and D.M.Cai. Resampling approach for anomaly detection in multispectral images. In Proceedings of the SPIE 5093,pages 230–240,2003.
【11】S TEINWART , I., H USH , D., AND S COVEL , C. 2005. A classification framework for anomaly detection. J. Mach. learn. Res. 6, 211–232.
【12】A BE , N., Z ADROZNY , B., AND L ANGFORD , J. 2006. Outlier detection by active learning. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM Press, New York, 504–509.