堆溢出与堆的内存布局有关,要搞明白堆溢出,首先要清楚的是malloc()分配的堆内存布局是什么样子,free()操作后又变成什么样子。
解决第一个问题:通过malloc()分配的堆内存,如何布局?

上图就是malloc()分配两块内存的情形。
其中mem指针指向的是malloc()返回的地址,pre_size与size都是4字节数据,size存放当前chunk(内存块,本文均不翻译)大小,pre_size存放上一个chunk大小。
因为malloc实现分配的内存空间是8字节对齐的,所以size的低3位其实没用,就取其中一位,用来标志前一个chunk是否被释放即PREV_INUSE位。当前一chunk释放,PREV_INUSE位置0,否则置1。
当malloc()分配的空间使用完毕后,将其mem指针传给free()进行释放。
解决第二个问题:free()对堆内存布局会产生什么影响?
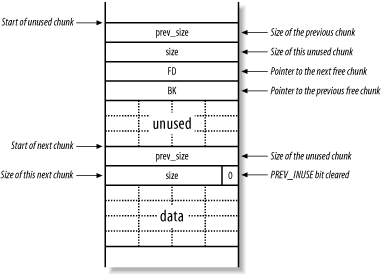

上图的情形是,当前chunk的上一chunk被free()释放,容易发现,当前chunk的PREV_ISUSE标志位置0,表示前一chunk已经被释放。
被释放的chunk中,原先data的位置的低地址处被填入两个指针,分别是fd和bk,它们是forward和backward单词的缩写,分别表示前一个free chunk和后一个free chunk的地址。这样所有通过free()释放的内存chunk会组成一个双向链表。也因此一个chunk最小长度为16字节:2个size和2个指针。

当一个chunk被释放时,还有一件事情要做,就是检查相邻chunk的是否处于释放状态,如果相邻chunk空闲的话,就会进行chunk合并操作。由于每个chunk中都存放了size信息,所以很容易就找到当前chunk前后chunk的状态。
free()里面会调用一个unlink宏来执行合并操作:
#define unlink(P, BK, FD) { \
FD = P->fd; \
BK = P->bk; \
FD->bk = BK; \
BK->fd = FD; \
}
好了,这个宏就是堆溢出利用的关键。仔细阅读这个宏其实就是在一个双向链表中删除一个结点的操作:
P->fd->bk = P->bk P->bk->fd = P->fd
其中P代表当前被删除结点。
解决最后一个问题:堆溢出如何利用?
首先构造一段堆溢出漏洞代码:
int main(void)
{
char *buff1, *buff2;
buff1 = malloc(40);
buff2 = malloc(40);
gets(buff1);
free(buff1);
exit(0);
}
给出堆空间布局:
low address +---------------------+ <--first chunk ptr | prev_size | +---------------------+ | size=48 | +---------------------+ <--first | | | allocated | | chunk | +---------------------+ <--second chunk ptr | prev_size | +---------------------+ | size=48 | +---------------------+ <--second | Allocated | | chunk | +---------------------+ high address
现在使用gets函数进行堆溢出,将第2块chunk的prev_size覆盖为任意值,size覆盖为-4即0xfffffffc,fd位置覆盖为exit@got-12,bk位置覆盖为shellcode地址。
覆盖后的堆空间布局情况:
low address +---------------------+ <--first chunk ptr | prev_size | +---------------------+ | size=48 | +---------------------+ <--first | | | allocated | | chunk | +---------------------+ <--second chunk ptr | XXXXXXXXX | +---------------------+ | size=0xfffffffc | +---------------------+ <--second | exit@got-12 | | shellcode地址 | | Allocated | | chunk | +---------------------+ high address
下面看free(buff1)时发生的操作:
1.first空间即buff1被释放掉
2.检查上一chunk是否需要合并(这里否)
3.检查下一chunk是否需要合并,检查的方法是检查下下个chunk的PREV_ISUSE标志位。即当前chunk加上当前size得到下个chunk,下个chunk加上下个size得到下下个chunk,因为我们设置下个chunk大小为-4,则下个chunk的pre_size位置被认为是下下个chunk的开始,下个size位置是0xfffffffc标志未置位,被认为是free的需合并。
那么,这里合并用到unlink宏时出问题了,同样对照上面图来看:
second->fd->bk=second->bk /* 1.second->bk是shellcode址 2.shellcode的地址被写进了second->fd+12的位置 3.second->fd是exit@got的地址-12 4.所以second->fd+12的位置就是exit@got-12 + 12 = exit@got即got中存的exit地址 因此exit()函数地址已经被shellcode地址替换 */ second->bk->fd=second->fd
“shellcode的地址被写进了second->fd+12的位置” 这句话要好好理解,为什么second->fd->bk是second->fd+12呢? 其实second->fd指向前一chunk头部,加12是跳过pre_size,size和fd即到达bk位置。
最后程序在执行到exit(0)语句时,由于地址被替换,shellcode执行。