版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012292754/article/details/83339489
1 Spark Streaming 介绍
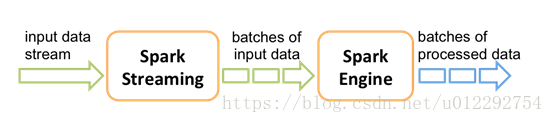
Spark Streaming类似于Apache Storm,用于流式数据的处理。根据其官方文档介绍,Spark Streaming有高吞吐量和容错能力强等特点。Spark Streaming支持的数据输入源很多,例如:Kafka、Flume、Twitter、ZeroMQ和简单的TCP套接字等等。数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,如HDFS,数据库等。另外Spark Streaming也能和MLlib(机器学习)以及Graphx完美融合。

1.1 特点
- 易用
- 容错
- 方便整合到Spark 体系


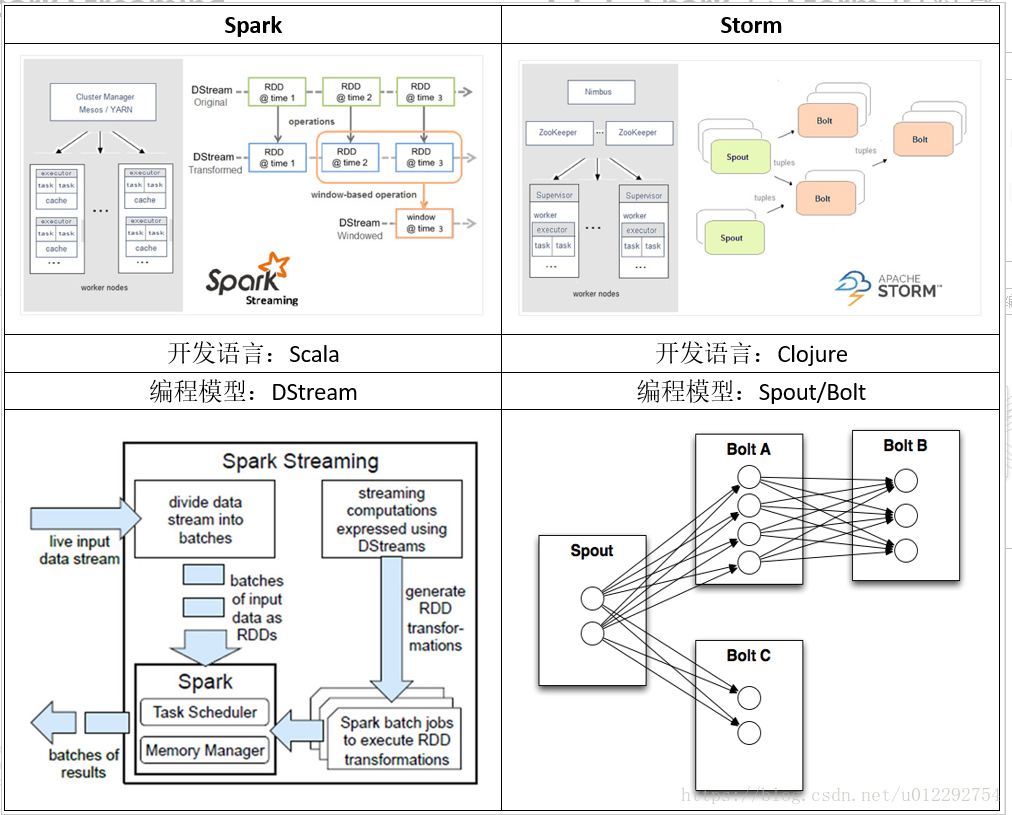
1.2 Streaming 和 Storm 的对比
2 DStream
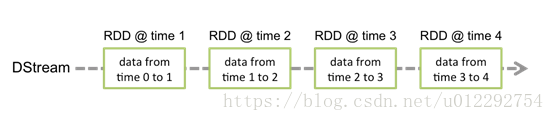
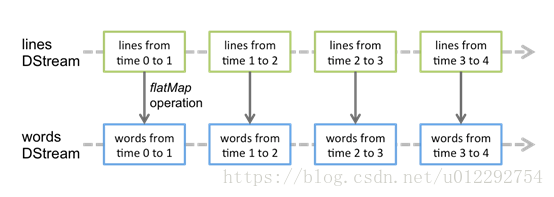
Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:
对数据的操作也是按照RDD为单位来进行的
计算过程由Spark engine来完成
3 测试案例
pom 文件添加
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.3</version>
</dependency>
3.1 源码
package mystreaming
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object StreamingWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("StreamingWordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(5))
//接收数据
val ds = ssc.socketTextStream("node1", 8888)
//DStream 是一个特殊的 RDD
val result = ds.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
3.2 在node1 启动SocketServer 发送数据

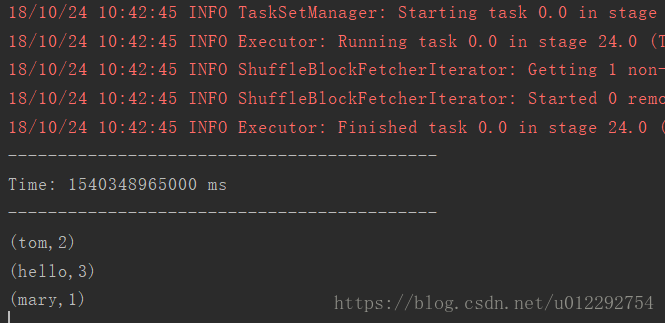
3.3 运行结果
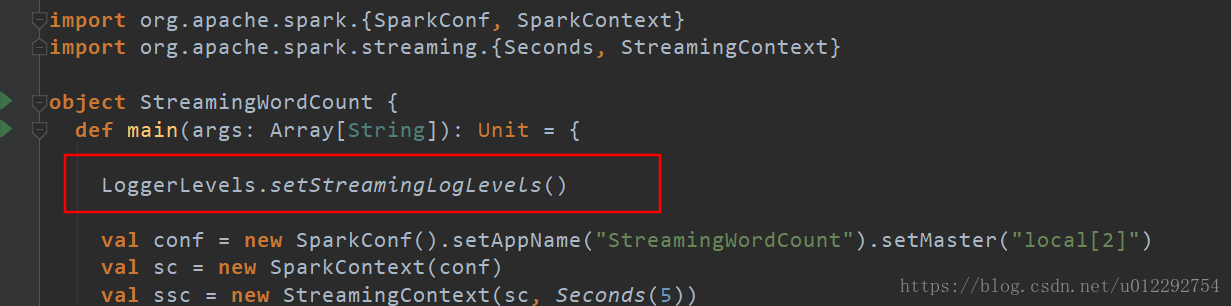
3.4 过滤打印日志
package mystreaming
import org.apache.log4j.{Logger, Level}
import org.apache.spark.Logging
object LoggerLevels extends Logging {
def setStreamingLogLevels() {
val log4jInitialized = Logger.getRootLogger.getAllAppenders.hasMoreElements
if (!log4jInitialized) {
logInfo("Setting log level to [WARN] for streaming example." +
" To override add a custom log4j.properties to the classpath.")
Logger.getRootLogger.setLevel(Level.WARN)
}
}
}