实战之updateStateByKey算子的使用
updateStateByKey操作允许您在使用新信息不断更新状态的同时维护任意状态。要使用它,您需要执行两个步骤。
1、定义状态——状态可以是任意数据类型。
2、定义状态更新函数——用函数指定如何使用以前的状态和输入流中的新值更新状态。
在每个批处理中,Spark将为所有现有键应用状态更新功能,而不管它们是否在批处理中有新数据。如果update函数不返回任何值,那么键-值对将被消除。
让我们用一个例子来说明这一点。
需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态)
package com.imooc.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用Spark Streaming完成有状态统计
*/
object StatefulWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("StatefulWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
//java.lang.IllegalArgumentException: requirement failed:
//The checkpoint directory has not been set.
//Please set it by StreamingContext.checkpoint().
// 如果使用了stateful的算子,必须要设置checkpoint
// (目前在当前目录下)在生产环境中,建议大家把checkpoint设置到HDFS的某个文件夹中
ssc.checkpoint(".")
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" ")).map((_,1))
val state = result.updateStateByKey[Int](updateFunction _)
state.print()
ssc.start()
ssc.awaitTermination()
}
/**
* 把当前的数据去更新已有的或者是老的数据
* @param currentValues 当前的
* @param preValues 老的
* @return
*/
def updateFunction(currentValues: Seq[Int], preValues: Option[Int]): Option[Int] = {
val current = currentValues.sum
val pre = preValues.getOrElse(0)
Some(current + pre)
}
}
Checkpointing
流应用程序必须全天候运行,因此必须能够适应与应用程序逻辑无关的故障(例如,系统故障、JVM崩溃等等)。为了实现这一点,Spark流需要将足够的信息检查点到容错存储系统,以便能够从故障中恢复。有两种类型的数据是检查点。
- Metadata checkpointing——将定义流计算的信息保存到容错存储(如HDFS)。它用于从运行流应用程序驱动程序的节点的故障中恢复(稍后将详细讨论)。元数据包括:
- Configuration——用于创建流应用程序的配置。
- DStream operations——定义流应用程序的DStream操作集。
- Incomplete batches—作业已排队但尚未完成的批处理。
- Data checkpointing——将生成的RDDs保存到可靠的存储中。在一些跨多个批处理组合数据的有状态转换中,这是必要的。在这种转换中,生成的rdd依赖于前几个批次的rdd,这使得依赖链的长度随着时间的推移而不断增加。为了避免恢复时间的无界增长(与依赖链成比例),有状态转换的中间rdd定期检查可靠存储(例如HDFS),以切断依赖链。
总之,元数据检查点主要用于从驱动程序故障中恢复,而数据或RDD检查点甚至对于使用有状态转换的基本功能也是必要的。
何时启用检查点
必须为有下列任何要求的应用程式启用检查点:
- 有状态转换的使用——如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(具有逆函数),那么必须提供检查点目录来允许周期性的RDD检查点。
- 从运行应用程序的驱动程序的故障中恢复——元数据检查点用于恢复进度信息。
注意,没有上述有状态转换的简单流应用程序可以在不启用检查点的情况下运行。在这种情况下,从驱动程序故障中恢复也是部分的(一些接收到但未处理的数据可能会丢失)。这通常是可以接受的,许多人以这种方式运行Spark流应用程序。对非hadoop环境的支持有望在未来得到改进。
如何配置请参考官网
http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#how-to-configure-checkpointing
实战之将统计结果写入到MySQL数据库中
需求:计算到目前为止累积出现的单词个数写入到MySQL
添加依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
编写:
需求:将统计结果写入到MySQL
create table wordcount(
word varchar(50) default null,
wordcount int(10) default null
);
通过该sql将统计结果写入到MySQL
insert into wordcount(word, wordcount) values(’" + record._1 + “’,” + record._2 + “)”
package com.imooc.spark
import java.sql.DriverManager
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 使用Spark Streaming完成词频统计,并将结果写入到MySQL数据库中
*/
object ForeachRDDApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("ForeachRDDApp").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
//result.print() //此处仅仅是将统计结果输出到控制台
//TODO... 将结果写入到MySQL(以下代码会报错)
// 这是不正确的,因为这需要将连接对象序列化并从驱动程序发送到工作程序。这样的连接对象很少能够跨机器进行传输。此错误可能表现为序列化错误
// result.foreachRDD(rdd =>{
// val connection = createConnection() // executed at the driver
// rdd.foreach { record =>
// val sql = "insert into wordcount(word, wordcount) values('"+record._1 + "'," + record._2 +")"
// connection.createStatement().execute(sql)
// }
// })
result.print()
result.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
val connection = createConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into wordcount(word, wordcount) values('" + record._1 + "'," + record._2 + ")"
connection.createStatement().execute(sql)
})
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
/**
* 获取MySQL的连接
*/
def createConnection() = {
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://localhost:3306/imooc_spark", "root", "root")
}
}
存在的问题:
-
对于已有的数据做更新,而是所有的数据均为insert
改进思路:
a) 在插入数据前先判断单词是否存在,如果存在就update,不存在则insert
b) 工作中:HBase/Redis -
每个rdd的partition创建connection,建议大家改成连接池
foreachrdd的操作官方详解:
http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#design-patterns-for-using-foreachrdd
实战之窗口函数的使用
window:定时的进行一个时间段内的数据处理
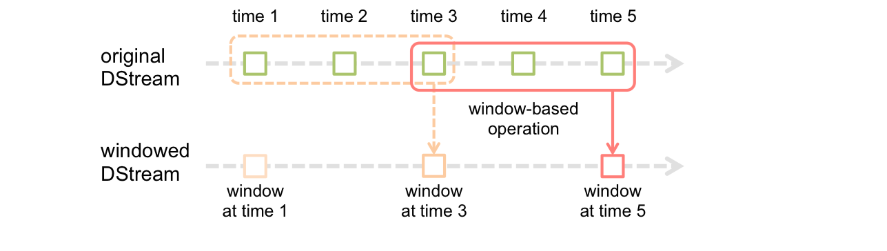
Spark流还提供了窗口计算,允许您在滑动的数据窗口上应用转换。上图演示了这个滑动窗口。
如图所示,每当窗口滑过源DStream时,位于该窗口内的源rdd被组合起来并对其进行操作,从而生成窗口化DStream的rdd。在这个特定的例子中,操作应用于过去3个时间单元的数据,并以2个时间单元进行幻灯片演示。这表明任何窗口操作都需要指定两个参数。
- window length窗口长度-窗口的持续时间。
- sliding interval滑动间隔-执行窗口操作的间隔。
这两个参数必须是源DStream批处理间隔的倍数。
让我们用一个例子来说明窗口操作。例如,您希望通过在最后30秒的数据中每10秒生成单词计数来扩展前面的示例。为此,我们必须在过去30秒的数据中对(word, 1)键值对的DStream应用reduceByKey操作。这是使用reduceByKeyAndWindow操作完成的。
// Reduce last 窗口长度30 seconds of data, every 滑动间隔10 seconds
//这2个参数和我们的batch size有关系:倍数
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
一些常见的窗口操作如下。所有这些操作都使用上述两个参数——windowLength和slideInterval
| Transformation | Meaning |
|---|---|
| window(windowLength, slideInterval) | 返回一个新的DStream,它是根据源DStream的窗口批次计算的。 |
| countByWindow(windowLength, slideInterval) | 返回流中元素的滑动窗口数。 |
| reduceByWindow(func, windowLength, slideInterval) | 返回一个新的单元素流,通过使用func在滑动间隔内聚合流中的元素而创建。该函数应该是关联的和可交换的,以便可以并行正确计算。 |
| reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当在(K,V)对的DStream上调用时,返回(K,V)对的新DStream,其中使用给定的reduce函数func 在滑动窗口中的批次聚合每个键的值。注意:默认情况下,这使用Spark的默认并行任务数(本地模式为2,在群集模式下,数量由config属性确定spark.default.parallelism)进行分组。您可以传递可选 numTasks参数来设置不同数量的任务。 |
| reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 上述更有效的版本,reduceByKeyAndWindow()其中使用前一窗口的reduce值逐步计算每个窗口的reduce值。这是通过减少进入滑动窗口的新数据,并“反向减少”离开窗口的旧数据来完成的。一个例子是当窗口滑动时“添加”和“减去”键的计数。但是,它仅适用于“可逆减少函数”,即那些具有相应“反向减少”函数的减函数(作为参数invFunc)。同样reduceByKeyAndWindow,reduce任务的数量可通过可选参数进行配置。请注意,必须启用检查点才能使用此操作。 |
| countByValueAndWindow(windowLength, slideInterval, [numTasks]) | 当在(K,V)对的DStream上调用时,返回(K,Long)对的新DStream,其中每个键的值是其在滑动窗口内的频率。同样 reduceByKeyAndWindow,reduce任务的数量可通过可选参数进行配置。 |
需求:每隔多久计算某个范围内的数据:每隔10秒计算前30分钟的wc
==> 每隔sliding interval统计前window length的值
只是算子的不同;其他都是和上面代码逻辑一样的。
实战之黑名单过滤
访问日志 ==> DStream
20180808,zs
20180808,ls
20180808,ww
==> (zs: 20180808,zs)(ls: 20180808,ls)(ww: 20180808,ww)
黑名单列表 ==> RDD
zs
ls
==>(zs: true)(ls: true)
==> 20180808,ww
leftjoin
(zs: [<20180808,zs>, ]) x
(ls: [<20180808,ls>, ]) x
(ww: [<20180808,ww>, ]) ==> tuple 1
package com.imooc.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 黑名单过滤
*/
object TransformApp {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
/**
* 创建StreamingContext需要两个参数:SparkConf和batch interval
*/
val ssc = new StreamingContext(sparkConf, Seconds(5))
/**
* 构建黑名单
*/
val blacks = List("zs", "ls")
val blacksRDD = ssc.sparkContext.parallelize(blacks).map(x => (x, true))
val lines = ssc.socketTextStream("localhost", 6789)
val clicklog = lines.map(x => (x.split(",")(1), x)).transform(rdd => {
rdd.leftOuterJoin(blacksRDD)
.filter(x=> x._2._2.getOrElse(false) != true)
.map(x=>x._2._1)
})
clicklog.print()
ssc.start()
ssc.awaitTermination()
}
}
实战之Spark Streaming整合Spark SQL操作
您可以轻松地在流数据上使用DataFrames和SQL操作。您必须使用StreamingContext使用的SparkContext创建一个SparkSession。此外,这样做可以在驱动程序失败时重新启动。这是通过创建一个延迟实例化的SparkSession单例实例来实现的。如下面的例子所示。它修改了前面的单词计数示例,以使用DataFrames和SQL生成单词计数。每个RDD都被转换为一个DataFrame,注册为一个临时表,然后使用SQL查询。
<!-- Spark SQL 依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
package com.imooc.spark
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext, Time}
/**
* Spark Streaming整合Spark SQL完成词频统计操作
*/
object SqlNetworkWordCount {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("ForeachRDDApp").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 6789)
val words = lines.flatMap(_.split(" "))
// Convert RDDs of the words DStream to DataFrame and run SQL query
words.foreachRDD { (rdd: RDD[String], time: Time) =>
val spark = SparkSessionSingleton.getInstance(rdd.sparkContext.getConf)
import spark.implicits._
// Convert RDD[String] to RDD[case class] to DataFrame
val wordsDataFrame = rdd.map(w => Record(w)).toDF()
// Creates a temporary view using the DataFrame
wordsDataFrame.createOrReplaceTempView("words")
// Do word count on table using SQL and print it
val wordCountsDataFrame =
spark.sql("select word, count(*) as total from words group by word")
println(s"========= $time =========")
wordCountsDataFrame.show()
}
ssc.start()
ssc.awaitTermination()
}
/** Case class for converting RDD to DataFrame */
case class Record(word: String)
/** Lazily instantiated singleton instance of SparkSession */
object SparkSessionSingleton {
@transient private var instance: SparkSession = _
def getInstance(sparkConf: SparkConf): SparkSession = {
if (instance == null) {
instance = SparkSession
.builder
.config(sparkConf)
.getOrCreate()
}
instance
}
}
}