1.Supervised learning:regressionproblem,classification problem
2.unsupervisedlearning:clustering algorithm,cocktail party algorithm
3.
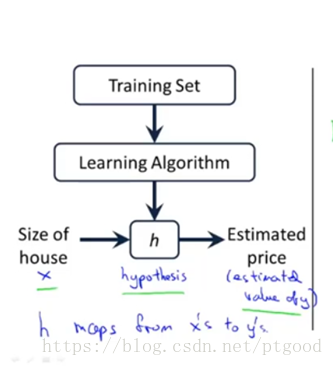
Hypothesis is justa standard terminology.


Cost function isalso called the squared error function or sometimes called square error costfunction
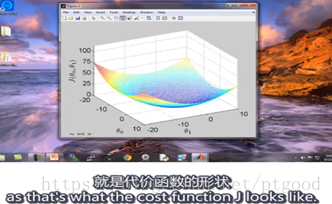
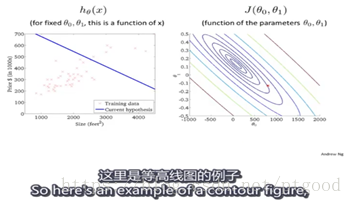


Initialize at onepoint ,step to the direction you decided that will take you downhill most quickly, until you converge to local minimum(local optimum) down here

Gradient decent algorithm

If you are alreadyat a local optimum , the derivative would be equal to zero .
And so on…

What we’re goingto do is apply gradient decent algorithm to minimize our squared error cost function

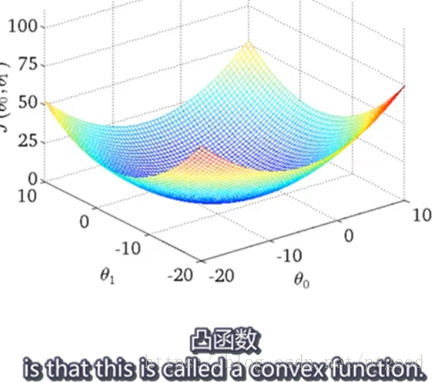
convex function only have a globaloptimum

Looking at the entirebatch of training examples
Another solution:Noramalequations methods will scale better to larger data sets
PPT source: http://study.163.com/course/courseLearn.htm?courseId=1004570029#/learn/text?lessonId=1050362429&courseId=1004570029