话说有2个同学小明和大明,小明三年级,大明四年级。
有一天,大明做一道语文填空,填一句三年级背诵的古文句子,大明三年级的书早就扔掉了,只好求助附近的小明,小明刚背诵过这篇古文,马上就给出了填空答案,大明恍然大悟,顺利的填上了答案。
举一反三,这个道理告诉我们,特别是程序员,只要涉及到数学,十年工作经验有什么用,数学公式你还能看懂几个?再比如打CS,打得越久就越刚?所以别羡慕人家比你年轻工资拿的比你高,像我一样打了19年CS还不是照样排天梯时不时被打自闭?
扯远了,开头的例子其实想表达一个DQN不太好理解的一个关键,为什么会用2个一模一样的网络Q预测和Q现实(也叫目标网络)呢?
论文里面的伪代码先不停的实验得到一些<s1,a1,r1,s2>这样的经验数据保存起来,比如保存2000条,一旦达到2000条就可以进行训练,这里不是每2000条开始一次训练,而是达到2000条之后每一条都即时更新Q预测网络,但是Q现实网络比如每50条更新一次,为什么这样做,这样做有一个名称叫做时间差分算法(TD),为什么要用TD,如果不用TD计算LOSS又会怎样?来,看看这个核心的Q值更新函数: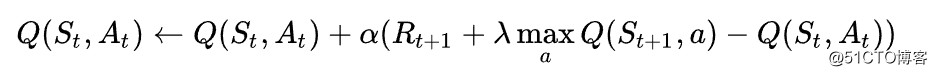
Q值等于现在的Q值加上学习率(当先奖励+衰减度未来能够获得的最大奖励-当前的Q值)
对了,还有一点没说,Q现实网络是不会反向更新的,所有的更新和学习都是再Q预测网络上进行的。前面谈到的Q现实网络每50条更新只是简单的把Q预测的每层网络权重值复制给Q现实网络。
那Q现实网络有什么作用呢?它的作用就是参与计算LOSS: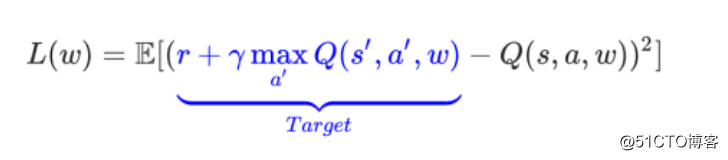
因为如果不用2个网络,只用一个Q预测网络,你想想看,Q预测网络是即时更新的,他的经验和最近的动作有关联,这样的预测就像是大明要填对那道三年级的题,但是他最近都是学习的四年级的课程,以前的课程早就忘了,怎么能做对呢?
换个角度理解DQN
猜你喜欢
转载自blog.51cto.com/1557154/2314962
今日推荐
周排行