一:分析函数over
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是对于每个组返回多行,而聚合函数对于每个组只返回一行。
1、分析函数和聚合函数的不同之处:
分析函数和聚合函数很多是同名的,意思也一样,只是聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值。简单的说就是聚合函数返回统计结果,分析函数返回明细加统计结果。
(一)、分析函数语法:
FUNCTION_NAME(<argument>,<argument>...)
OVER
(<Partition-Clause><Order-by-Clause><Windowing Clause>)
例:(在oracle示例库中演示,用户scott)
select ename,sum(sal) over (partition by deptno order by ename) new_alias from emp;
a、sum就是函数名(FUNCTION_NAME)
b、(sal)是分析函数的参数,每个函数有0~3个参数,参数可以是表达式,例如:sum(sal+comm)
c、over 是一个关键字,用于标识分析函数,否则查询分析器不能区别sum()聚集函数和sum()分析函数
d、partition by deptno (按相应的值(deptno)进行分组统计)是可选的分区子句,如果不存在任何分区子句,则全部的结果集可看作一个单一的大区
e、order by ename 是可选的order by 子句,有些函数需要它,有些则不需要.依靠已排序数据的那些函数。
即:分析函数带有一个开窗函数over(),包含三个分析子句:
分组(partition by)
排序(order by)
窗口(rows)
示例1:
SELECT empno,ename,job,deptno, ----查询基础字段 COUNT(*) over(PARTITION BY deptno) cnt_dept_man, --- 查询部门人员数量 (等同于用部门deptno进行分组查询) COUNT(*) over (PARTITION BY deptno ORDER BY empno) AS sum_dept_add, --- 查询出的部门人员数依次为前一行的求和数加上当前行的行数(若未sum则会是逐行累加的数据) COUNT(*) over(PARTITION BY job) cnt_job_man , ---查询岗位的的人员数量 (等同于用岗位job进行分组查询) COUNT(*) over (PARTITION BY job ORDER BY empno) AS sum_job_add ---查询出岗位人员(依次为前一行的求和数加上当前行的行数(若未sum则会是逐行累加的数据) FROM emp;
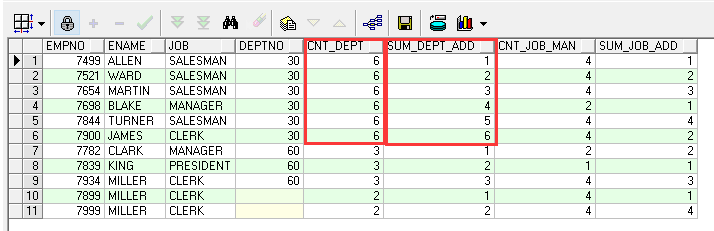
(二)、FUNCTION子句
ORACLE提供了N多个分析函数,按功能分5类
Oracle分析函数——函数列表
------------------------------------------------------------------------------------------------
SUM :该函数计算组中表达式的累积和
MIN :在一个组中的数据窗口中查找表达式的最小值
MAX :在一个组中的数据窗口中查找表达式的最大值
AVG :用于计算一个组和数据窗口内表达式的平均值。
COUNT :对一组内发生的事情进行累积计数
-------------------------------------------------------------------------------------------------
RANK :根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置
DENSE_RANK :根据ORDER BY子句中表达式的值,从查询返回的每一行,计算它们与其它行的相对位置
FIRST :从DENSE_RANK返回的集合中取出排在最前面的一个值的行
LAST :从DENSE_RANK返回的集合中取出排在最后面的一个值的行
FIRST_VALUE :返回组中数据窗口的第一个值
LAST_VALUE :返回组中数据窗口的最后一个值。
LAG :可以访问结果集中的其它行而不用进行自连接
LEAD :LEAD与LAG相反,LEAD可以访问组中当前行之后的行
ROW_NUMBER :返回有序组中一行的偏移量,从而可用于按特定标准排序的行号
-------------------------------------------------------------------------------------------------
STDDEV :计算当前行关于组的标准偏离
STDDEV_POP :该函数计算总体标准偏离,并返回总体变量的平方根
STDDEV_SAMP :该函数计算累积样本标准偏离,并返回总体变量的平方根
VAR_POP :该函数返回非空集合的总体变量(忽略null)
VAR_SAMP :该函数返回非空集合的样本变量(忽略null)
VARIANCE :如果表达式中行数为1,则返回0,如果表达式中行数大于1,则返回VAR_SAMP
COVAR_POP :返回一对表达式的总体协方差
COVAR_SAMP :返回一对表达式的样本协方差
CORR :返回一对表达式的相关系数
-------------------------------------------------------------------------------------------------
CUME_DIST :计算一行在组中的相对位置
NTILE :将一个组分为"表达式"的散列表示
PERCENT_RANK :和CUME_DIST(累积分配)函数类似
PERCENTILE_DISC :返回一个与输入的分布百分比值相对应的数据值
PERCENTILE_CONT :返回一个与输入的分布百分比值相对应的数据值
RATIO_TO_REPORT :该函数计算expression/(sum(expression))的值,它给出相对于总数的百分比
REGR_ (Linear Regression) Functions :这些线性回归函数适合最小二乘法回归线,有9个不同的回归函数可使用
-------------------------------------------------------------------------------------------------
CUBE :按照OLAP的CUBE方式进行数据统计,即各个维度均需统计
ROLLUP :
-------------------------------------------------------------------------------------------------
示例2:查询每个部门工资最高的员工信息
1、(count,rank,dense_rank,row_number)排名函数的使用及注意事项
在使用排名函数的时候需要注意以下三点:
(1、排名函数必须有 OVER 子句。
(2、排名函数必须有包含 ORDER BY 的 OVER 子句。
(3、分组内从1开始排序。
-- 一般的写法: SELECT E.ENAME, E.JOB, E.SAL MAXSAL , E.DEPTNO FROM SCOTT.EMP E, (SELECT E.DEPTNO, MAX(E.SAL) SAL FROM SCOTT.EMP E GROUP BY E.DEPTNO) ME WHERE E.DEPTNO = ME.DEPTNO AND E.SAL = ME.SAL; -- 分析函数OVER (使用count函数用order by将相应数据分组,获取分组编号) SELECT ENAME,JOB,MAXSAL,DEPTNO FROM (SELECT ENAME,JOB,MAX(SAL) OVER (PARTITION BY DEPTNO) AS MAXSAL,DEPTNO, COUNT(*) OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) AS NUM FROM EMP) WHERE NUM = 1; --析函数OVER (使用rank函数用order by将相应数据分组,获取分组编号) SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM (SELECT ENAME,JOB,SAL,RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E WHERE E.RANK = 1 AND NOT deptno IS NULL; --分析函数OVER (使用dense_rank函数用order by将相应数据分组,获取分组编号) SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM (SELECT ENAME,JOB,SAL,dense_RANK() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E WHERE E.RANK = 1 AND NOT deptno IS NULL; --分析函数OVER (使用row_number函数用order by将相应数据分组,获取分组编号) SELECT E.ENAME,E.JOB,E.SAL,E.DEPTNO FROM (SELECT ENAME,JOB,SAL,row_number() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RANK ,DEPTNO FROM EMP) E WHERE E.RANK = 1 AND NOT deptno IS NULL;
注意事项:
一般写法与分析函数的主要区别在于:使用分析函数可以提升sql的执行效率,一般写法是通过两个或多个表关联来进行查询(存在笛卡尔积),而用分析函数则所有的查询都在一个表中实现,大大提升了sql的查询效率(主要体现于自身表的关联查询)。
row_number的用途非常广泛,排序最好用它,它会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
count函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一,count()是跳跃排序,有两个第一名时两个第一名的序号都为2,就没有第一名,有两个第二名,接下来就是第三名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
示例3、查询员工信息的同时,查询员工工资与所在部门最低、最高工资的差额
2、(min、max)取最值函数的使用及注意事项
--一般写法
SELECT E.ENAME, E.JOB,E.SAL,E.DEPTNO,
ME.MIN_SAL MIN_SAL,
ME.MAX_SAL MAX_SAL, E.SAL - ME.MIN_SAL DIFF_MIN_SAL, ME.MAX_SAL - E.SAL DIFF_MAX_SAL FROM SCOTT.EMP E, (SELECT E.DEPTNO, MIN(E.SAL) MIN_SAL, MAX(E.SAL) MAX_SAL FROM SCOTT.EMP E GROUP BY E.DEPTNO) ME WHERE E.DEPTNO = ME.DEPTNO ORDER BY E.DEPTNO, E.SAL; --使用分析函数: SELECT E.ENAME, E.JOB,E.SAL,E.DEPTNO,
MIN(E.SAL) OVER(PARTITION BY E.DEPTNO) MIN_SAL, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) MAX_SAL, NVL(E.SAL - MIN(E.SAL) OVER(PARTITION BY E.DEPTNO), 0) DIFF_MIN_SAL, NVL(MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) - E.SAL, 0) DIFF_MAX_SAL FROM EMP E; /*注:这里没有排序条件,若加上order by 排序条件, MAX() OVER(PARTITION BY .. ORDER BY .. DESC) 排序规则只能为desc,否则不起作用,将查询到目前为止排序值最高字段的对应值 MIN() OVER(PARTITION BY .. ORDER BY .. ASC ) 排序规则只能为asc,否则不起作用,将查询到目前为止排序值最低的字段的对应值, 如下:*/ SELECT E.ENAME, E.JOB,E.SAL,E.DEPTNO, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO) MIN_SAL01, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) MAX_SAL01, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) MIN_SAL02, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL) MAX_SAL02, --不起作用 MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) MIN_SAL03, --不起作用 MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL DESC) MAX_SAL03, MIN(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ASC) MIN_SAL04, MAX(E.SAL) OVER(PARTITION BY E.DEPTNO ORDER BY E.SAL ASC) MAX_SAL04, --不起作用 NVL(E.SAL - MIN(E.SAL) OVER(PARTITION BY E.DEPTNO), 0) DIFF_MIN_SAL, NVL(MAX(E.SAL) OVER(PARTITION BY E.DEPTNO) - E.SAL, 0) DIFF_MAX_SAL FROM EMP E;