select empid,deptid,salary,rank from (
select heyf_tmp.empid,heyf_tmp.deptid,heyf_tmp.salary,@rownum1:=@rownum1+1 ,
if(@pdept=heyf_tmp.deptid,@rank:=@rank+1,@rank:=1) as rank,
@pdept:=heyf_tmp.deptid
from (
select empid,deptid,salary from heyf_t10 order by deptid asc ,salary desc
) heyf_tmp ,(select @rownum1 :=0 , @pdept := null ,@rank:=0) a ) result
;
--最高效
select * from (
SELECT empid, deptid, salary,
case when @mid = deptid then @row:=@row+1 else @row:=1 end rownum,
@mid:=deptid
FROM heyf_t10
order by deptid,salary desc) tt where tt.rownum=1;
----------------------------------转载-----------------------------------------------------------
Mysql:实现row_number分组排序功能
在sql server 和 oracle 中均有row_number 实现功能,即对查询结果进行分组排序添加字段。而在mysql中无内置函数,需要曲线救国。
表结构:
CREATE TABLE `total_freq_ctrl` (
`time` int(10) unsigned NOT NULL,
`machine` char(64) NOT NULL,
`module` char(32) NOT NULL,
`total_flow` int(10) unsigned NOT NULL,
`deny_flow` int(10) unsigned NOT NULL,
PRIMARY KEY (`module`,`machine`,`time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1、通过内表连接进行对应字段大小计数方式判断该条记录所处的row_number
SELECT machine, deny_flow, total_flow, time
FROM total_freq_ctrl A
WHERE ( SELECT COUNT(machine)
FROM total_freq_ctrl
WHERE machine = A.machine AND time > A.time) < 1
AND A.module = 'all'
ORDER BY A.time desc;
在修改排序序号的位置,修改你需要取出的序列号,即为取出N-1的序号
2、引入@rownum 将表内数据添加序列号
set @row=0;
SELECT module, machine, time, @row:=@row+1 rownum
FROM total_freq_ctrl
order by module,machine,time desc
limit 10;
结果展示:
+--------+---------------+------------+--------+
| module | machine | time | rownum |
+--------+---------------+------------+--------+
| all | 10.201.20.181 | 1409640060 | 1 |
| all | 10.201.20.181 | 1409640000 | 2 |
| all | 10.201.20.181 | 1409639940 | 3 |
| all | 10.201.20.181 | 1409639880 | 4 |
| all | 10.201.20.97 | 1409640060 | 5 |
| all | 10.201.20.97 | 1409640000 | 6 |
| all | 10.201.20.97 | 1409639940 | 7 |
| all | 10.201.20.97 | 1409639880 | 8 |
| all | 10.201.20.98 | 1409640060 | 9 |
| all | 10.201.20.98 | 1409640000 | 10 |
+--------+---------------+------------+--------+
3、添加@mid来进行分组,按mid进行分组添加rownum
set @row=0;
set @mid='';
SELECT module, machine, time,
case when @mid = machine then @row:=@row+1 else @row:=1 end rownum,
@mid:=machine
FROM total_freq_ctrl
order by module,machine,time desc
limit 20;
结果展示:
+--------+---------------+------------+--------+---------------+
| module | machine | time | rownum | @mid:=machine |
+--------+---------------+------------+--------+---------------+
| all | 10.201.20.181 | 1409640180 | 1 | 10.201.20.181 |
| all | 10.201.20.181 | 1409640120 | 2 | 10.201.20.181 |
| all | 10.201.20.181 | 1409640060 | 3 | 10.201.20.181 |
| all | 10.201.20.181 | 1409640000 | 4 | 10.201.20.181 |
| all | 10.201.20.181 | 1409639940 | 5 | 10.201.20.181 |
| all | 10.201.20.181 | 1409639880 | 6 | 10.201.20.181 |
| all | 10.201.20.97 | 1409640180 | 1 | 10.201.20.97 |
| all | 10.201.20.97 | 1409640120 | 2 | 10.201.20.97 |
| all | 10.201.20.97 | 1409640060 | 3 | 10.201.20.97 |
| all | 10.201.20.97 | 1409640000 | 4 | 10.201.20.97 |
| all | 10.201.20.97 | 1409639940 | 5 | 10.201.20.97 |
| all | 10.201.20.97 | 1409639880 | 6 | 10.201.20.97 |
| all | 10.201.20.98 | 1409640180 | 1 | 10.201.20.98 |
| all | 10.201.20.98 | 1409640120 | 2 | 10.201.20.98 |
| all | 10.201.20.98 | 1409640060 | 3 | 10.201.20.98 |
| all | 10.201.20.98 | 1409640000 | 4 | 10.201.20.98 |
| all | 10.201.20.98 | 1409639940 | 5 | 10.201.20.98 |
| all | 10.201.20.98 | 1409639880 | 6 | 10.201.20.98 |
+--------+---------------+------------+--------+---------------+
注:1、Mysql中添加rownum功能,主要是group by变量改变,设置order by 排序进行rownum增加。再根据子查询,join,having 等条件进行对rownum筛选。
2、若只是取出前几条而不添加rownum字段值,可以直接进行内连接表,count内表值order by外表值的条数来进行控制选出的rownum。
3、若只是简单的排除数据可以利用exists,not exists,join ,in条件等。
注:这个用了几次发现应该注意的问题:
1、为什么没有分类排序?排序总是1等
可能是排序的group by变量没有设置正确,没有初始赋值set @mid=''语句,变量设置在判断条件之前进行了赋值操作,即@mid:=machine一定要在case when之后。
2、为什么排序的结果不是安装分组的顺序,总是1或者随机的等?
可能在排序的结果集中,你只是添加了order by的排序字段,但是没有将group by变量添加到order by里面。其中我想mysql是不断的对@mid:=machine的赋值来进行排序,那么一定要让数据先按照分组并排序好的状态下才能添加正确的id。如果没有对分组字段排序,就等于检索的结果是不确定的。
-----------------------------转载2---------------------------------------------------------------------
- 由于MYSQL没有提供类似ORACLE中OVER()这样丰富的分析函数. 所以在MYSQL里需要实现这样的功能,我们只能用一些灵活的办法:
- 1.首先我们来创建实例数据:
- drop table if exists heyf_t10;
- create table heyf_t10 (empid int ,deptid int ,salary decimal(10,2) );
- insert into heyf_t10 values
- (1,10,5500.00),
- (2,10,4500.00),
- (3,20,1900.00),
- (4,20,4800.00),
- (5,40,6500.00),
- (6,40,14500.00),
- (7,40,44500.00),
- (8,50,6500.00),
- (9,50,7500.00);
- 2. 确定需求: 根据部门来分组,显示各员工在部门里按薪水排名名次.
- 显示结果预期如下:
- +-------+--------+----------+------+
- | empid | deptid | salary | rank |
- +-------+--------+----------+------+
- | 1 | 10 | 5500.00 | 1 |
- | 2 | 10 | 4500.00 | 2 |
- | 4 | 20 | 4800.00 | 1 |
- | 3 | 20 | 1900.00 | 2 |
- | 7 | 40 | 44500.00 | 1 |
- | 6 | 40 | 14500.00 | 2 |
- | 5 | 40 | 6500.00 | 3 |
- | 9 | 50 | 7500.00 | 1 |
- | 8 | 50 | 6500.00 | 2 |
- +-------+--------+----------+------+
- 3. SQL 实现
- select empid,deptid,salary,rank from (
- select heyf_tmp.empid,heyf_tmp.deptid,heyf_tmp.salary,@rownum:=@rownum+1 ,
- if(@pdept=heyf_tmp.deptid,@rank:=@rank+1,@rank:=1) as rank,
- @pdept:=heyf_tmp.deptid
- from (
- select empid,deptid,salary from heyf_t10 order by deptid asc ,salary desc
- ) heyf_tmp ,(select @rownum :=0 , @pdept := null ,@rank:=0) a ) result
- ;
- 4. 结果演示
- mysql> select empid,deptid,salary,rank from (
- -> select heyf_tmp.empid,heyf_tmp.deptid,heyf_tmp.salary,@rownum:=@rownum+1 ,
- -> if(@pdept=heyf_tmp.deptid,@rank:=@rank+1,@rank:=1) as rank,
- -> @pdept:=heyf_tmp.deptid
- -> from (
- -> select empid,deptid,salary from heyf_t10 order by deptid asc ,salary desc
- -> ) heyf_tmp ,(select @rownum :=0 , @pdept := null ,@rank:=0) a ) result
- -> ;
- +-------+--------+----------+------+
- | empid | deptid | salary | rank |
- +-------+--------+----------+------+
- | 1 | 10 | 5500.00 | 1 |
- | 2 | 10 | 4500.00 | 2 |
- | 4 | 20 | 4800.00 | 1 |
- | 3 | 20 | 1900.00 | 2 |
- | 7 | 40 | 44500.00 | 1 |
- | 6 | 40 | 14500.00 | 2 |
- | 5 | 40 | 6500.00 | 3 |
- | 9 | 50 | 7500.00 | 1 |
- | 8 | 50 | 6500.00 | 2 |
- +-------+--------+----------+------+
- 9 rows in set (0.00 sec)
- MySql中取出每个分组中的前N条记录
- select a1.* from article a1
- inner join
- (select a.type,a.date from article a left join article b
- on a.type=b.type and a.date<=b.date
- group by a.type,a.date
- having count(b.date)<=2
- )b1
- on a1.type=b1.type and a1.date=b1.date
- order by a1.type,a1.date desc
------------------------------------------------转载3---------------------------------------------------------------------
这个表,数据如下:
mysql> SELECT * FROM t1;
+----+----------+-----+
| id | category | num |
+----+----------+-----+
| 1 | a | 1 |
| 2 | a | 2 |
| 3 | a | 3 |
| 4 | a | 4 |
| 5 | b | 5 |
| 6 | b | 1 |
| 7 | c | 0 |
| 8 | c | 9 |
| 9 | d | 0 |
+----+----------+-----+
需求要查询出每种category里面,num第二大的那条记录。比如应该返回:
+----+----------+-----+
| id | category | num |
+----+----------+-----+
| 3 | a | 3 |
| 6 | b | 1 |
| 7 | c | 0 |
+----+----------+-----+
由于mysql数据库比较弱,没有oracle里面的类似row_NUMBER orer()这样的高级分析函数。所以要实现这样的效果还是比较麻烦。
并且效率很差劲。不过还是可以实现的。下面来看看:
C:\>mysql -P3306Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 13
Server version: 5.7.11-log MySQL Community Server (GPL)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use test
Database changed
mysql> DROP TABLE IF EXISTS t1;
Query OK, 0 rows affected (0.37 sec)
mysql> CREATE TABLE t1 (
-> id INT AUTO_INCREMENT NOT NULL PRIMARY KEY,
-> category CHAR(1) NOT NULL,
-> num INT NOT NULL DEFAULT 0
-> ) ;
Query OK, 0 rows affected (0.40 sec)
mysql> desc t1;
+----------+---------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+---------+------+-----+---------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| category | char(1) | NO | | NULL | |
| num | int(11) | NO | | 0 | |
+----------+---------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> INSERT INTO t1 (category, num)
-> VALUES
-> ('a', 1),
-> ('a', 2),
-> ('a', 3),
-> ('a', 4),
-> ('b', 5),
-> ('b', 1),
-> ('c', 0),
-> ('c', 9),
-> ('d', 0) ;
Query OK, 9 rows affected (0.16 sec)
Records: 9 Duplicates: 0 Warnings: 0
mysql> SELECT * FROM t1;
+----+----------+-----+
| id | category | num |
+----+----------+-----+
| 1 | a | 1 |
| 2 | a | 2 |
| 3 | a | 3 |
| 4 | a | 4 |
| 5 | b | 5 |
| 6 | b | 1 |
| 7 | c | 0 |
| 8 | c | 9 |
| 9 | d | 0 |
+----+----------+-----+
9 rows in set (0.00 sec)
mysql>
测试数据有了,怎么返回我们要的效果呢?
mysql> SELECT * FROM t1;
+----+----------+-----+
| id | category | num |
+----+----------+-----+
| 1 | a | 1 |
| 2 | a | 2 |
| 3 | a | 3 |
| 4 | a | 4 |
| 5 | b | 5 |
| 6 | b | 1 |
| 7 | c | 0 |
| 8 | c | 9 |
| 9 | d | 0 |
+----+----------+-----+
9 rows in set (0.00 sec)
mysql> SELECT
-> t1.`id`,
-> t1.`category`,
-> t1.`num`,
-> (SELECT
-> COUNT(*)
-> FROM
-> t1 inner_t1
-> WHERE inner_t1.category = t1.`category`
-> AND inner_t1.num >= t1.`num`) AS ct
-> FROM
-> t1;
+----+----------+-----+------+
| id | category | num | ct |
+----+----------+-----+------+
| 1 | a | 1 | 4 |
| 2 | a | 2 | 3 |
| 3 | a | 3 | 2 |
| 4 | a | 4 | 1 |
| 5 | b | 5 | 1 |
| 6 | b | 1 | 2 |
| 7 | c | 0 | 2 |
| 8 | c | 9 | 1 |
| 9 | d | 0 | 1 |
+----+----------+-----+------+
9 rows in set (0.00 sec)
这个效率不行,对于每条记录都回去描述一次原表。再提取出ct=2的记录即可:
mysql> SELECT
-> ttmp_1.id,
-> ttmp_1.category,
-> ttmp_1.num
-> FROM
-> (SELECT
-> t1.`id`,
-> t1.`category`,
-> t1.`num`,
-> (SELECT
-> COUNT(*)
-> FROM
-> t1 inner_t1
-> WHERE inner_t1.category = t1.`category`
-> AND inner_t1.num >= t1.`num`) AS ct
-> FROM
-> t1) AS ttmp_1
-> WHERE ttmp_1.ct = 2
-> ORDER BY ttmp_1.category ASC
-> ;
+----+----------+-----+
| id | category | num |
+----+----------+-----+
| 3 | a | 3 |
| 6 | b | 1 |
| 7 | c | 0 |
+----+----------+-----+
3 rows in set (0.00 sec)
mysql>
完成。
-------------------------------------------------------转载4---------------------------------------------------------------
XSD以前写过HIVE脚本,记得有个 PARTITION BY语句 通过ROW_NUMBER() over (PARTITION BY xx ORDER BY ** DESC) as row_number 可以根据xx字段分组,在分组内根据**字段排序,然后赋予每一行数据一个行编号,通过 row_number = 1 就可以获得分组内的第一行的数字了。可是现在使用的是mysql,没有PARTITION BY语句 怎么办呢?最后在HM的帮助下XSD终于实现了。
首先列几个简单的字段
action_history表
| id | job_id | start_time | status |
|---|---|---|---|
| 1 | 1 | 2017-12-08 00:00:00 | failed |
| 2 | 2 | 2017-12-08 01:00:00 | success |
| 3 | 3 | 2017-12-08 02:00:00 | running |
| 4 | 1 | 2017-12-08 00:30:00 | success |
| 5 | 2 | 2017-12-08 01:30:00 | running |
| 6 | 3 | 2017-12-08 02:30:00 | failed |
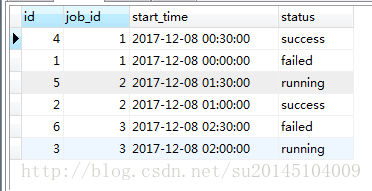
首先我们可以首先根据job_id 排序然后根据start_time进行二级排序
select * from action_history
where left(start_time,10) = CURDATE()
order by job_id asc ,start_time desc- 1
- 2
- 3
运行结果如下:
在下一步之前首先熟悉一下GROUP_CONCAT,这条语句会返回一个字符串,这个字符串由分组中的值连接组合而成。比如
select GROUP_CONCAT(status order by start_time desc )str from action_history- 1
结果为 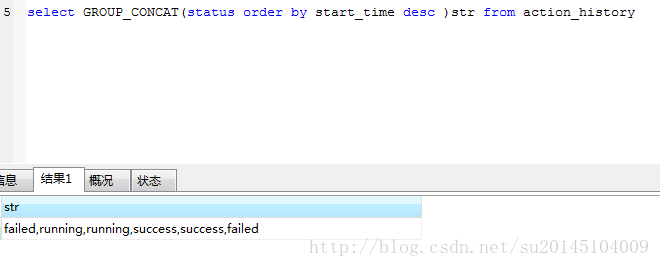
然后在这条sql的基础上就可以使用 SUBSTRING_INDEX( GROUP_CONCAT(status order by start_time desc),',',1)
就能得到最新的状态了
完整语句为:
select
job_id,SUBSTRING_INDEX( GROUP_CONCAT(status order by start_time desc),',',1) status
from
(
select
job_id,status,start_time
from
action_history
where
left(start_time,10) = CURDATE()
order by job_id asc ,start_time desc
)b
GROUP BY job_id
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这样就能得到所有的任务的最新的状态
| job_id | status |
|---|---|
| 1 | success |
| 2 | running |
| 3 | failed |
如果想得到success,failed或者running的任务 在这个最后这个基础上where条件进行status筛选就好啦~
XSD就这样在HM的帮助下完成了任务~