正则表达式
正则表达式为高级的文本模式匹配,抽取,与/或文本形式的搜索和替换功能提供了基础。正则表达式是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符。

转义符\
在正则表达式中,有很多有特殊意义的是元字符,比如\n和\s等,如果要在正则中匹配正常的"\n"而不是"换行符"就需要对""进行转义,变成’\’。
在python中,无论是正则表达式,还是待匹配的内容,都是以字符串的形式出现的,在字符串中\也有特殊的含义,本身还需要转义。所以如果匹配一次"\n",字符串中要写成’\n’,那么正则里就要写成"\\n",这样就太麻烦了。这个时候我们就用到了r’\n’这个概念,此时的正则是r’\n’就可以了。

贪婪匹配
在满足匹配时,匹配尽可能长的字符串,默认情况下,采用贪婪匹配

分组()与或|[^]
(1)^[1-9]\d{13,16}[0-9x]$ #^以数字0-9开始, \d{13,16}重复13次到16次
$结束标志
上面的表达式可以匹配一个正确的身份证号码
(2)^[1-9]\d{14}(\d{2}[0-9x])?$
#?重复0次或者1次,当是0次的时候是15位,是1的时候是18位
(3)^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
#表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
Re模块

match方法
只能从开始字符串开始的地方进行匹配
#只从字符串开始匹配,并且guoup才能找到
import re
m = re.match('luck', 'luck')
if m is not None:
print(m.group()) #当返回的有对象,也就是说能够匹配到对象,就会有结果,否则会抛出异常
输出:'luck’
感受一下不是从字符串开始匹配,他就没有返回值, print(m.group()) 也没有输出
import re
m = re.match('luck', 'luck')
if m is not None:
print(m.group())
search方法
函数会在字符串中查找模式匹配,只会找到第一个匹配然后返回,一个包含匹配信息的对象,该对象通过调用group()方法得到匹配的,如果字符串没有匹配,则报错
import re
m = re.match('a', 'laucka')
if m is not None:
print(m.group())
输出的就只有一个a,虽然这里面有两个,但是,它就会只找出第一个就返回了,不会再继续向下找,但是这个就不能使用match方法。
findall方法
它返回要匹配出的所有结果,有几个就会匹配几个,最终把所有的放在列表里面。
import re
m = re.findall('a', 'alucka')
print(m)
#输出 [‘a’, ‘a’]
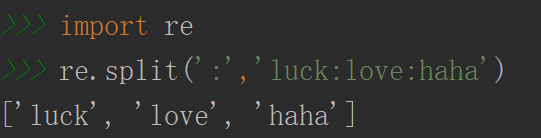
split方法
分割查找,以某一字符分割,并把分割后的结果放在列表里返回
sub方法,subn方法
这两个方法一样,都是替换与搜索,只是,sub方法只是替换,subn方法还会返回替换的次数
参数(正则表达式,替换成的字符,要搜素的字符,要替换的次数)
sub方法

subn方法

compile方法

finditer方法

findall的优先级
import re
ret = re.findall('www.(baidu|cnblogs).com','www.cnblogs.com')
print(ret) #结果是['cnblogs']这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|cnblogs).com','www.cnblogs.com')
print(ret) #['www.oldboy.com']
split的优先级
ret = re.split('\d+','luck123dasda9dg')#按数字分割开了
print(ret) #输出结果:['luck', 'dasda', 'dg']
ret = re.split('(\d+)','luck123dasda9dg')
print(ret) #输出结果:['luck', '123', 'dasda', '9', 'dg']
# 在匹配部分加上()之后和不加括号切出的结果是不同的,
# 没有括号的没有保留所匹配的项,但是有括号的却能够保留了
# 匹配的项,这个在某些需要保留匹配部分的使用过程是非常重要的
匹配标签
import re
ret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")
#还可以在分组中利用?<name>的形式给分组起名字
#获取的匹配结果可以直接用group('名字')拿到对应的值
print(ret.group('tag_name')) #结果 :h1
print(ret.group()) #结果 :<h1>hello</h1>
ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
#如果不给组起名字,也可以用\序号来找到对应的组,表示要找的内容和前面的组内容一致
#获取的匹配结果可以直接用group(序号)拿到对应的值
print(ret.group(1))
print(ret.group()) #结果 :<h1>hello</h1>
匹配整数
import re
ret=re.findall(r"\d+","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['1', '2', '60', '40', '35', '5', '4', '3']
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
print(ret) #['1', '-2', '60', '', '5', '-4', '3']
ret.remove("")
print(ret) #['1', '-2', '60', '5', '-4', '3']
数字匹配
1、 匹配一段文本中的每行的邮箱
http://blog.csdn.net/make164492212/article/details/51656638
2、 匹配一段文本中的每行的时间字符串,比如:‘1990-07-12’;
分别取出1年的12个月(^(0?[1-9]|1[0-2])$)、
一个月的31天:^((0?[1-9])|((1|2)[0-9])|30|31)$
3、 匹配qq号。(腾讯QQ号从10000开始) [1,9][0,9]{4,}
4、 匹配一个浮点数。 ^(-?\d+)(\.\d+)?$ 或者 -?\d+\.?\d*
5、 匹配汉字。 ^[\u4e00-\u9fa5]{0,}$
6、 匹配出所有整数