版权声明:小哥哥小姐姐们,本文为小博主原创文章,转载请附上博主博文网址,并标注作者谢谢~~。违者必究 https://blog.csdn.net/HuHui_/article/details/83960047
前言
后面准备更新hdfs操作(shell命令版本),hbase,hive的操作。
所以这里先更新一下hadoop集群安装。
装备
1.hadoop-2.6.5.tar.gz
2.三台服务器(虚拟机就可以)
3.centos7
Core
-
服务器规划
后面我就直接说名字不说IP了
| (192.168.31.60)master | (192.168.31.61)slave1 | (192.168.31.62)slave2 |
|---|---|---|
| NameNode | ResourceManage | SecondaryNameNode |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer |
-
下载hadoop源码包和JDK
hadoop官方下载
扫描二维码关注公众号,回复: 4032751 查看本文章
https://archive.apache.org/dist/hadoop/common/
java官方下载
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
-
上传到服务器master
根据个人规划路径
# cd /app/install # ls hadoop-2.6.5.tar.gz jdk-8u171-linux-x64.tar.gz -
创建hadoop用户
# useradd hadoop # passwd hadoop -
配置hostname
# vi /etc/hosts 192.168.31.60 master 192.168.31.61 slave1 192.168.31.62 slave2 -
配置SSH免密登录
# cd ~/.ssh/ # ssh-keygen -t rsa # ssh-copy-id -i 192.168.31.60 # scp -r /root/.ssh/ [email protected]:/root/ # scp -r /root/.ssh/ [email protected]:/root/ -
安装JDK
$ cd /app/install $ tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/local/java配置java环境变量
$ vi /etc/profile #set java environment JAVA_HOME=/usr/local/java/jdk1.8.0_171 JRE_HOME=$JAVA_HOME/jre PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME:/bin CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib export JAVA_HOME JRE_HOME PATH CLASSPATH -
安装Hadoop
$ cd /app/install $ tar -zxvf hadoop-2.6.5.tar.gz -C /usr/local/配置hadoop环境变量
$ vi /etc/profile #set hadoop environment export HADOOP_HOME=/usr/local/hadoop-2.6.5 export PATH=$PATH:$HADOOP_HOME/bin -
让配置文件起效
$ source /etc/profile $ source /etc/hosts -
修改hadoop配置文件
$ cd /usr/local/hadoop-2.6.5/etc/hadoop -
修改hadoop-env.sh、mapred-env.sh、yarn-env.sh添加jdk路径
$ export JAVA_HOME=/usr/local/java/jdk1.8.0_171 -
配置core-site.xml
$ vi core-site.xml <configuration> #NameNode的地址+端口 <property> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> #hadoop临时目录的地址,默认情况NameNode和DataNode的数据文件都会存在这个目录 <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop-2.6.5/data/tmp</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/dfs/data</value> </property> </configuration> -
配置hdfs-site.xml
$ vi hdfs-site.xml <configuration> #secondaryNameNode的地址+端口号 <property> <name>dfs.namenode.secondary.http-address</name> <value>slave2:50090</value> </property> </configuration> -
配置slaves
master slave1 slave2 -
配置yarn-site.xml
$ vi yarn-site.xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> #resourcemanager的地址 <property> <name>yarn.resourcemanager.hostname</name> <value>slave1</value> </property> #启用日志聚集功能 <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> #日志保存时间 <property> <name>yarn.log-aggregation.retain-seconds</name> <value>106800</value> </property> </configuration> -
配置mapred-site.xml
$ cp mapred-site.xml.template mapred-site.xml $ vi cp mapred-site.xml.template mapred-site.xml <configuration> #设置yarn运行mapreduce任务 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> #mapreduce的history服务器安装节点 <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> #history的web地址 <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration> -
删除doc
$ cd /usr/local/hadoop-2.6.5/share $ rm -rf doc -
配置另外两台服务器(slave1,slave2)
#复制hadoop到slave1,slave2 $ scp -r hadoop-2.6.5/ root@slave1:/usr/local/ $ scp -r hadoop-2.6.5/ root@slave2:/usr/local/ #复制jdk到slave1,slave2 $ scp -r java/ root@slave1:/usr/local/ $ scp -r java/ root@slave2:/usr/local/ #复制环境变量到slave1,slave2 $ scp /etc/profile root@slave1:/etc/ $ scp /etc/profile root@slave2:/etc/ #复制hostname到slave1,slave2 $ scp /etc/hosts root@slave1:/etc/ $ scp /etc/hosts root@slave2:/etc/ #记得source起效 -
NameNode格式化
$ cd /usr/local/hadoop-2.6.5/bin $ sh hdfs namenode –format -
启动集群
$ cd /usr/local/hadoop-2.6.5/sin $ sh start-dfs.sh -
启动yarn
$ sh start-yarn.sh -
Slave1启动ResourceManager
$ ssh slave1 $ cd /usr/local/hadoop-2.6.5/sin $ sh yarn-daemon.sh start resourcemanager -
master启动historyServer
$ cd /usr/local/hadoop-2.6.5/sin $ sh mr-jobhistory-daemon.sh start historyserver -
web页面访问
-
图看效果
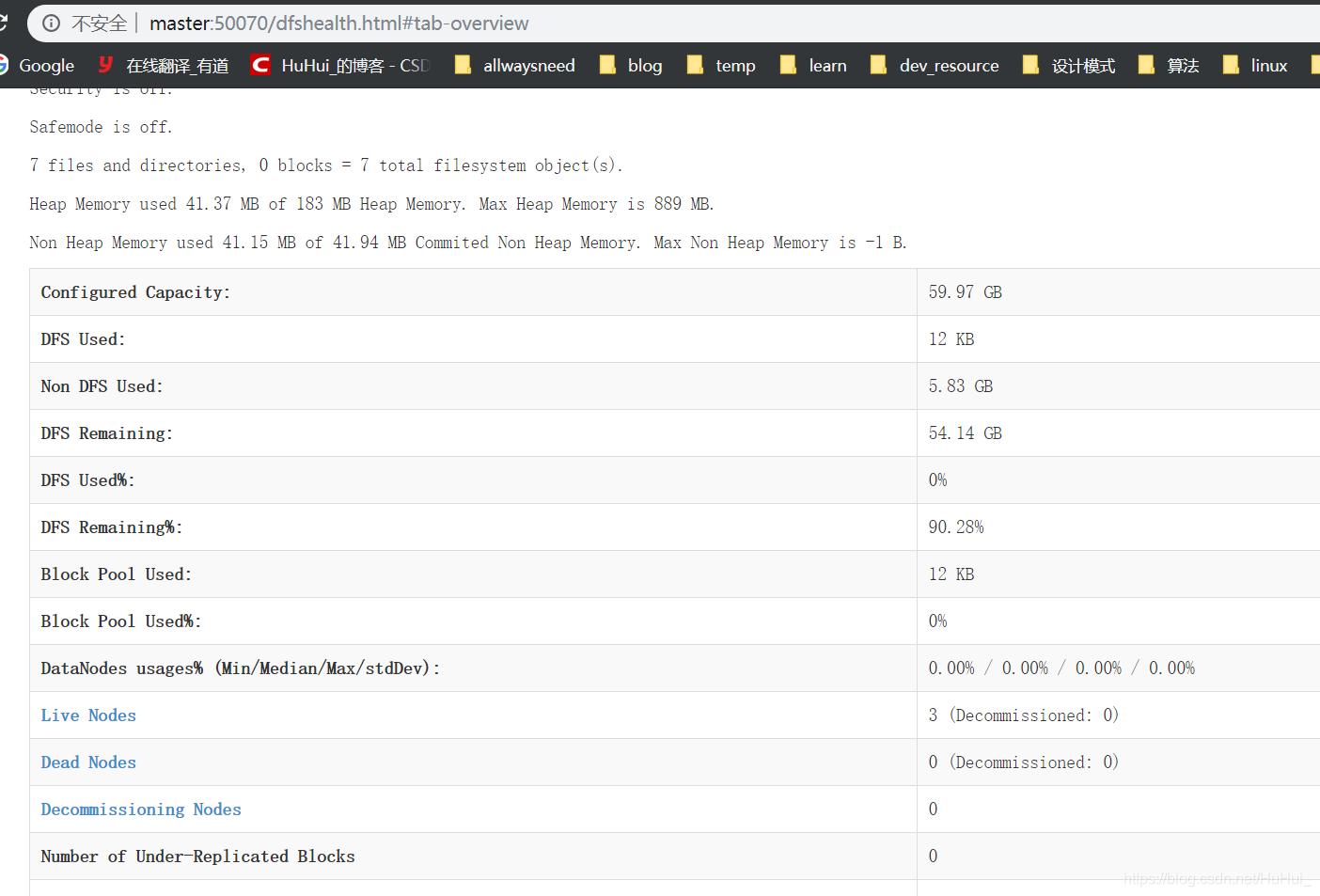
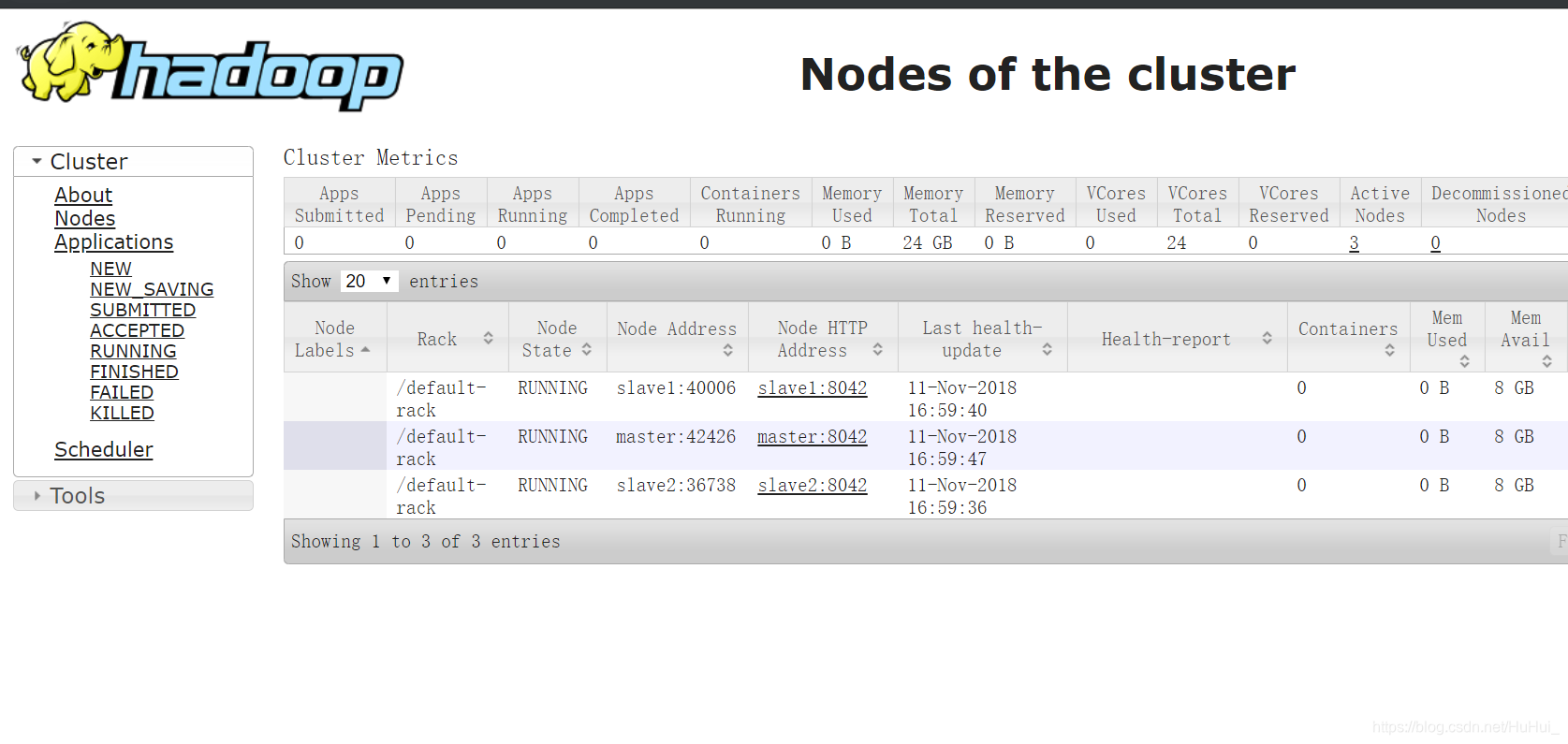
总结
- 搭建集群不难。重点是亲手去操作。
- 后面用上hive了,加hive,用了hbase,加hbase
- 更新到了zookeeper,就慢慢改造成高可用的
- 转载注明下作者 感谢~