简介:我这里配置的完全分布式集群,使用的hadoop用户,所以在之前必须创建一个hadoop用户,上传hadoop的jar包,然后再继续使用我接下来完全分布式的配置方法。如果在配置的过程当中出现了什么问题,欢迎博友提出来,我们一起讨论解决问题哦!
-->三台主机配置好了也后先给其配置网卡,我这里先配置好主节点的,然后自己再克隆两台,再更其改主机名,网卡既可。
配置网卡命令:vi /etc/sysconfig/network-scripts/ifcfg-eth0
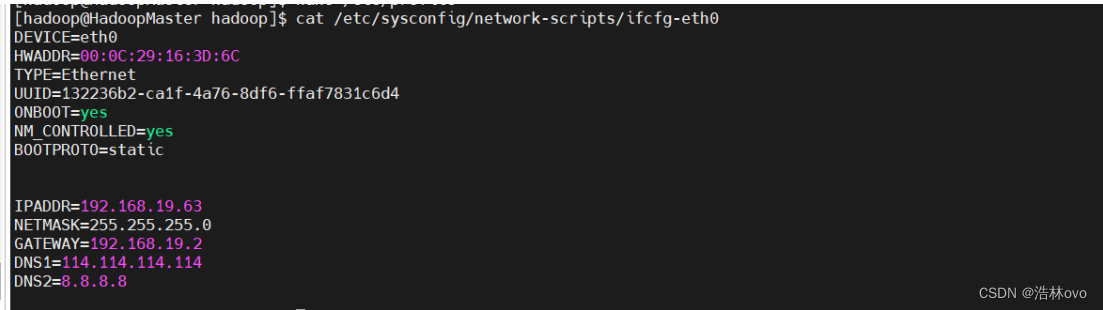
注:配置好网卡以后一定要重新重启一下网卡。命令:service network restart
做好网卡配置网卡后ping 一下百度,一般百度能通就没有问题。
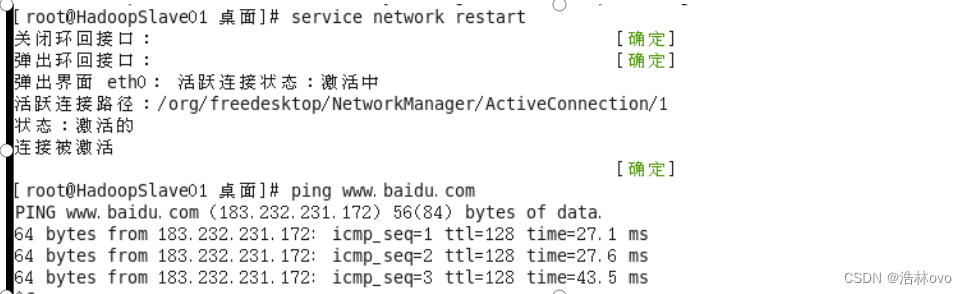
--->关闭防火墙
临时关闭:
执行命令: service iptables stop
永久关闭:
执行命令: chkconfig iptables off

--->设置主机名
执行命令 :hostname HadoopMaster
vi /etc/sysconfig/network
--->ip 与 hostname 绑定
执行命令: vi /etc/hosts
验证: ping HadooptMaster

--->然后用winscp传输hadoop和jdk到虚拟机上面,安装hadoop
用tar -zxvf hadoop-2.7.3.tar.gz 解压(jdk也是如此)
然后用 vi ~/.bash_profile
配置jdk
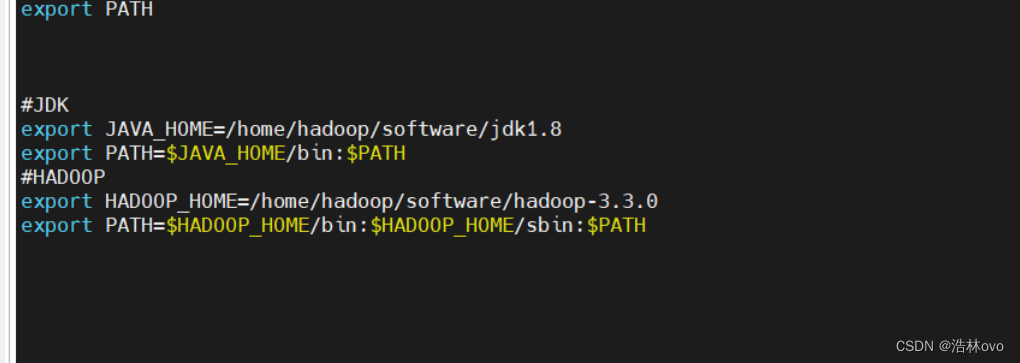
--->开始配置hadoop的环境
1.hadoop-env.sh
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/hadoop-env.sh
添加下面一行代码:
export JAVA_HOME=/home/hadoop/software/jdk1.8
然后保存文件

2.yarn-env.sh
在文件的靠前的部分找到下面的一行代码:
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
将这行代码修改为下面的代码(将#号去掉):
export JAVA_HOME=/home/hadoop/software/jdk1.8
然后保存文件。

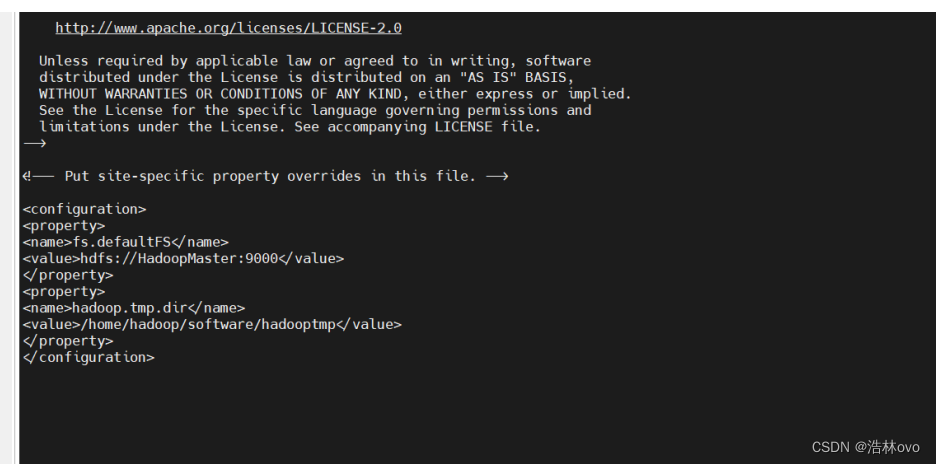
3.core-site.xml
core-site.xml 中的内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://HadoopMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/software/hadooptmp</value>
</property>
</configuration>
4.hdfs-site.xml
hdfs-site.xml 中的内容:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>

5.yarn-site.xml
yarn-site.xml 中的内容:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>HadoopMaster:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>HadoopMaster:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>HadoopMaster:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>HadoopMaster:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>HadoopMaster:8088</value>
</property>
</configuration>
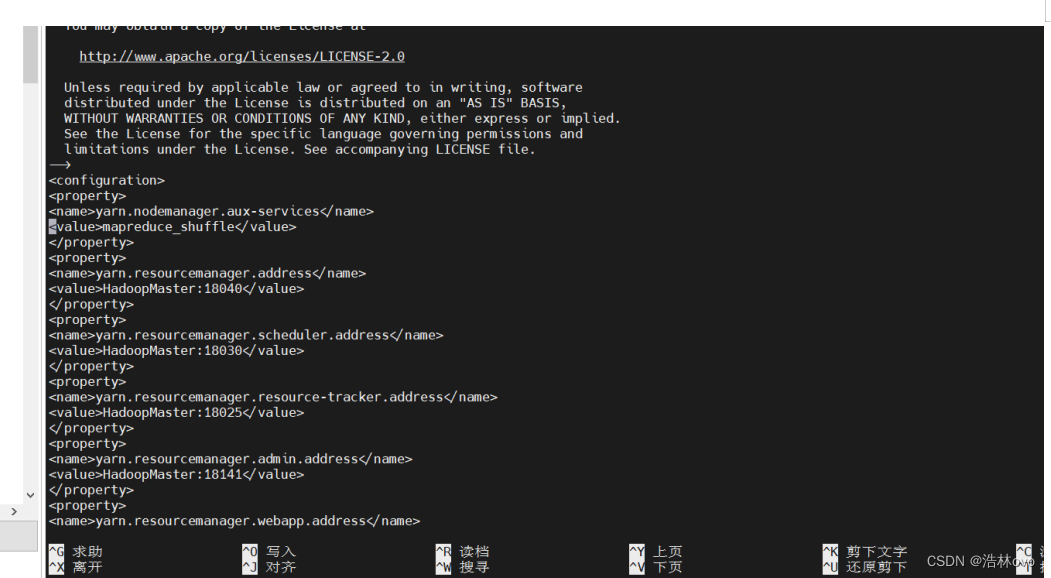
6.mapred-site.xml
mapred-site.xml 中的内容
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>

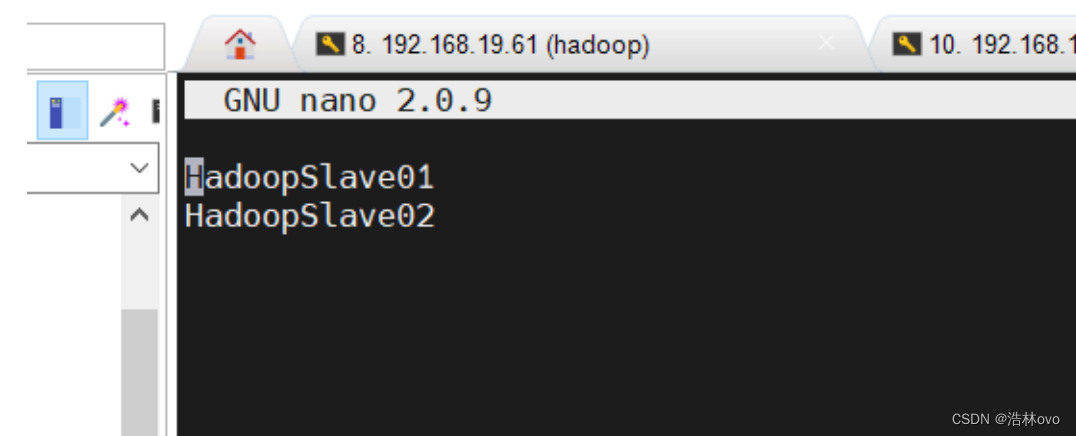
7.在 HadoopMaster 节点配置 works 文件
使用 vim 编辑:
vim /home/hadoop/hadoop-3.3.0/etc/hadoop/works
用下面的代码替换 works 中的内容:
HadoopSlave01
HadoopSlave02
8.主节点的内容配置好了,然后克隆两台从节点
9.配置 Hadoop 启动的系统环境变量
三个节点上进行操作,操作命令如下:
该配置需要同时在三个节点执行(HadoopMaster 、HadoopSlave01、HadoopSlave02)
vim ~/.bash_profile
将下面的代码追加到.bash_profile文件末尾:
#HADOOP
export HADOOP_HOME=/home/hadoop/software/hadoop-3.3.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
然后执行命令:
source ~/.bash_profile
注意:这里前面已经配置好了
10.重新配置网卡并修改虚拟机的主机名和重新绑定ip就可以了
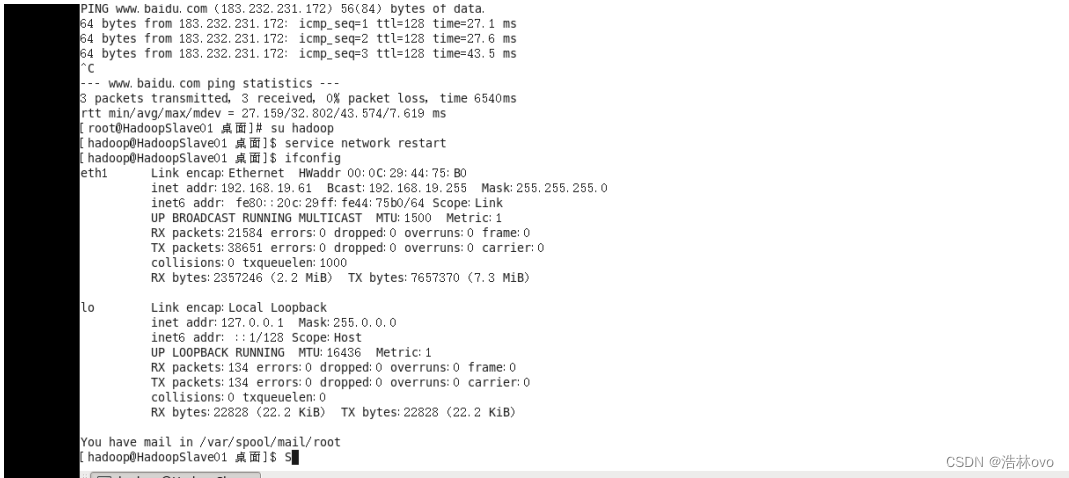
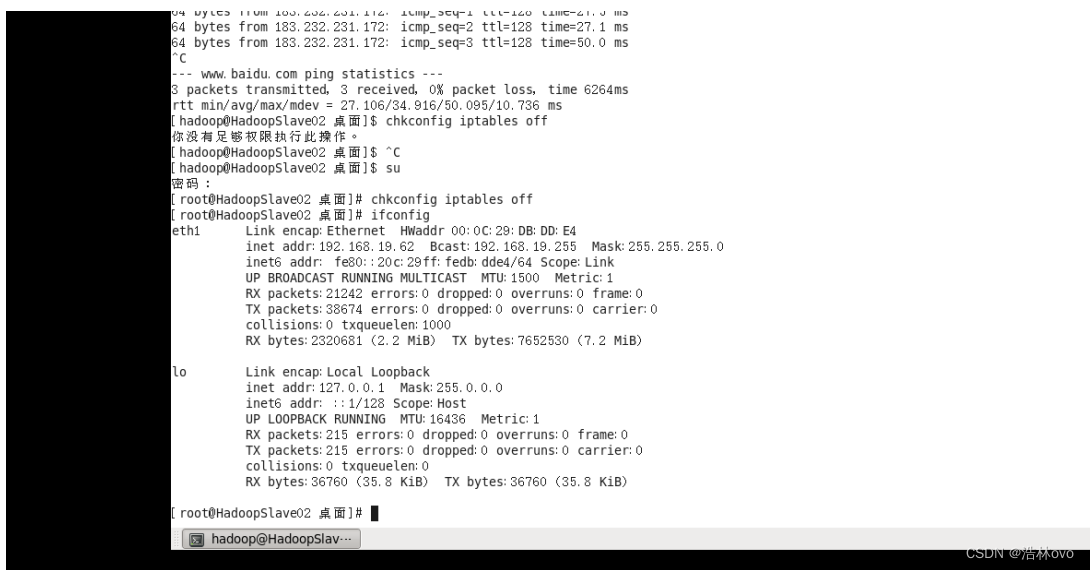
11.格式化NameNode文件系统
格式化命令如下,该操作需要在HadoopMaster 节点上执行:
hdfs namenode -format
注:主节点进行格式化,从节点不需要格式化。
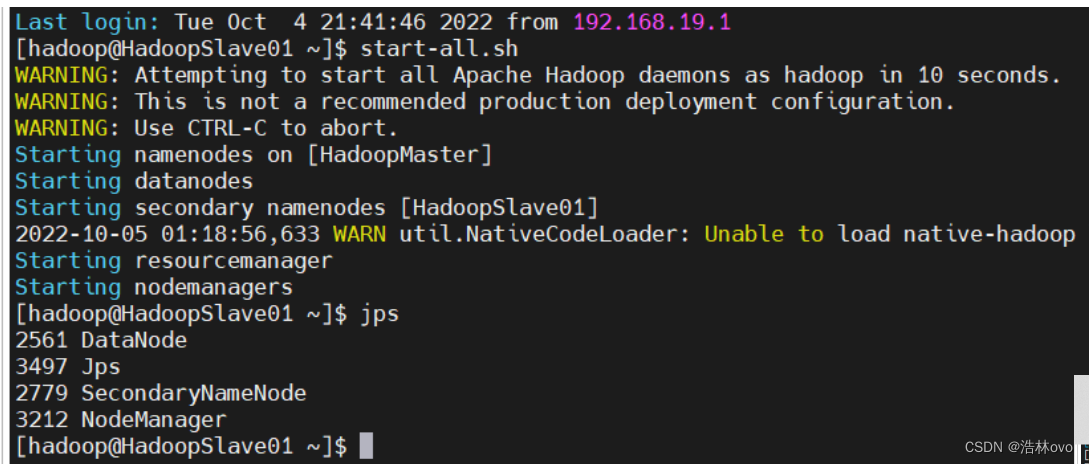
12.启动 Hadoop集群
start-all.sh
Jps
主节点:

第一个从节点:
第二个从节点:
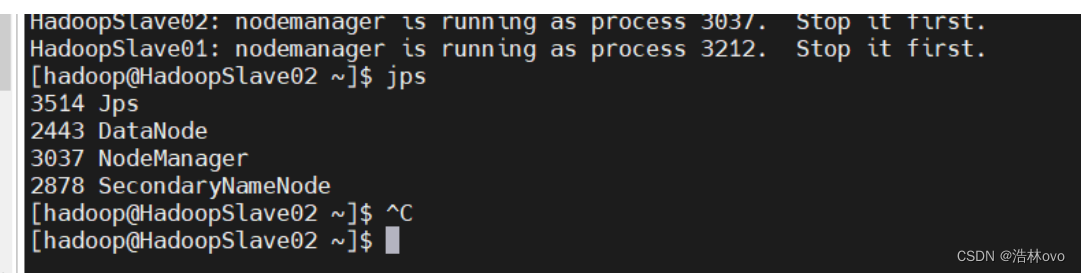
完全分布式已近配置完毕!!!