【hadoop学习2】Hadoop完全分布式环境配置
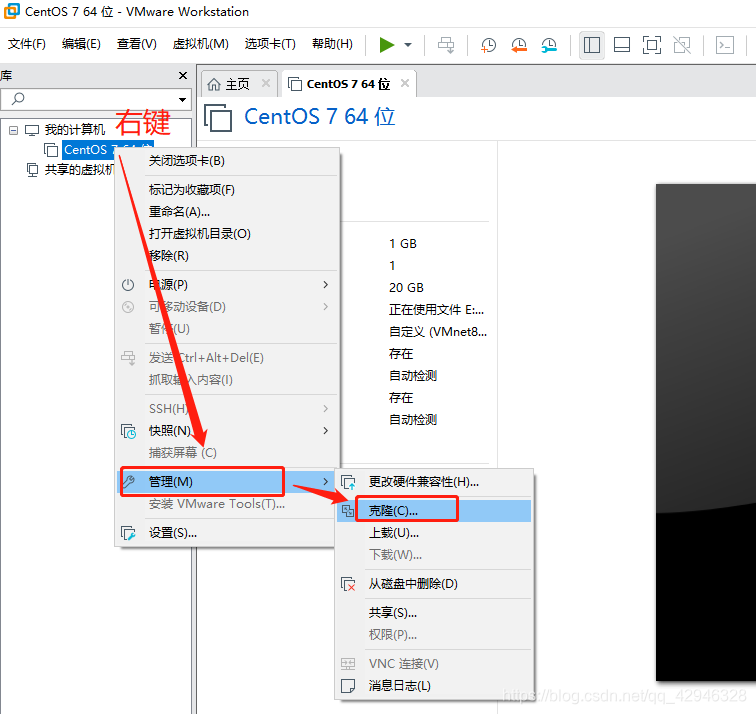
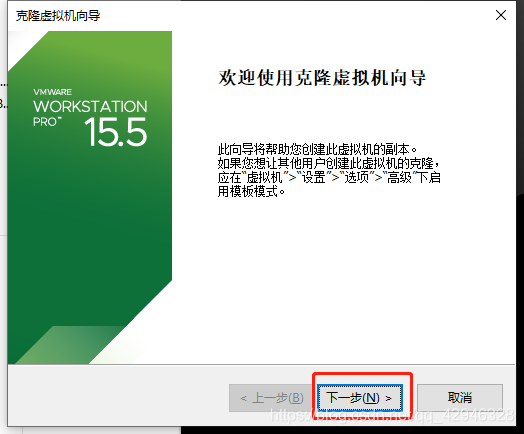
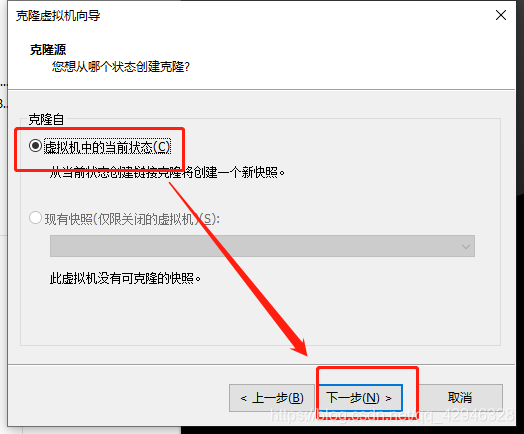
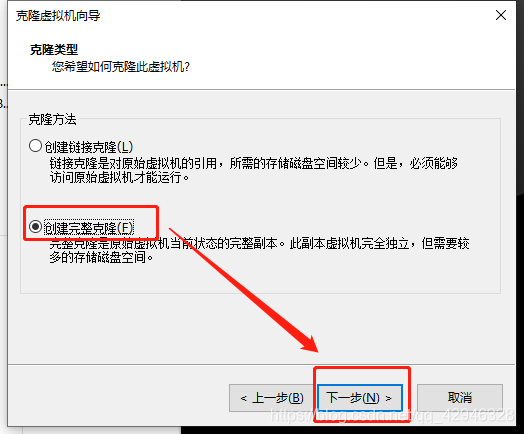
1 克隆虚拟机
被克隆虚拟机呈关机状态
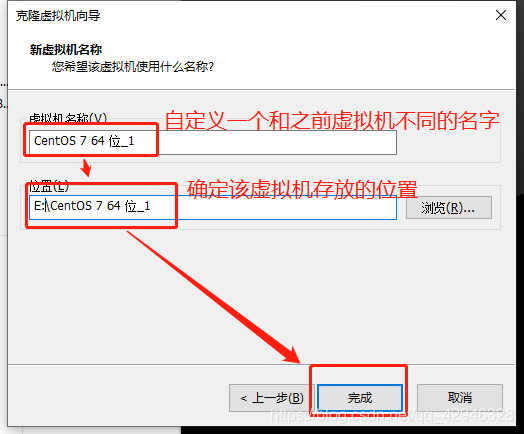
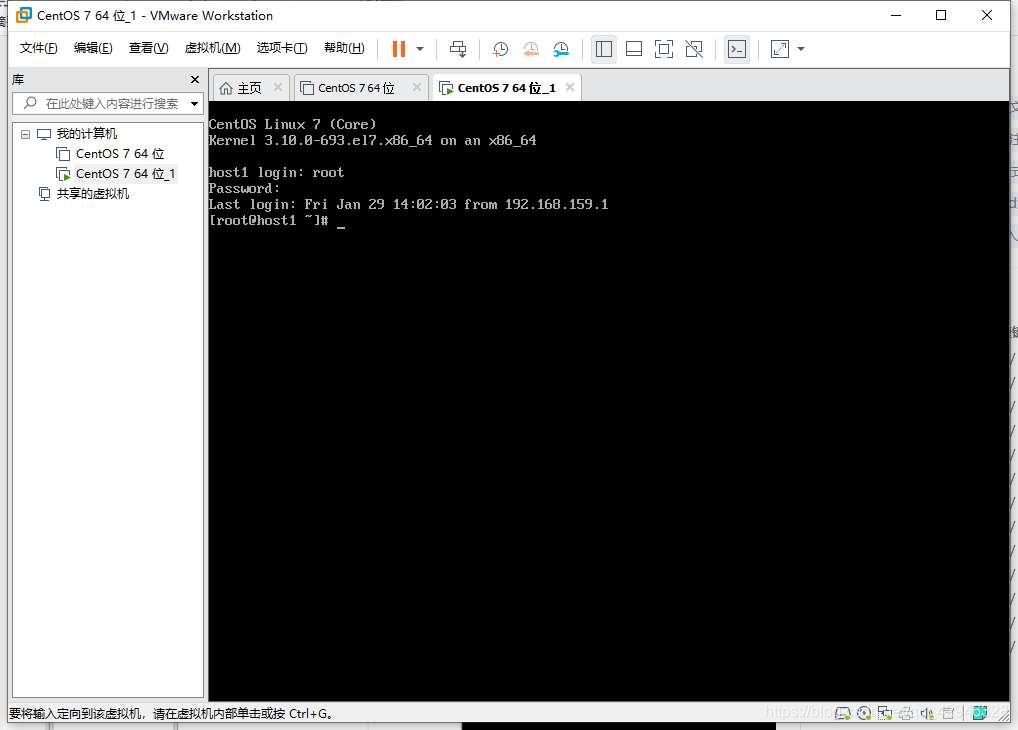
修改hostname
vi /etc/sysconfig/network
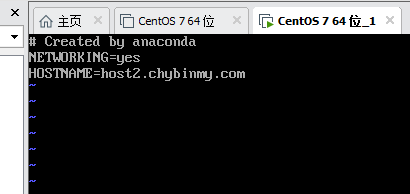
查看ip配置文件
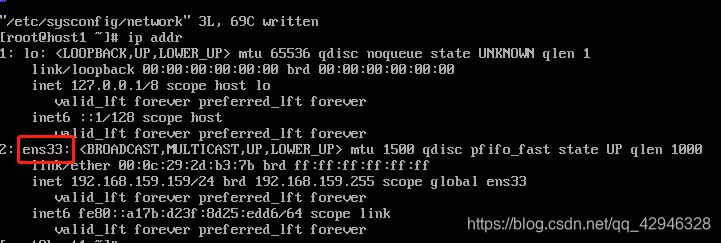
ip addr
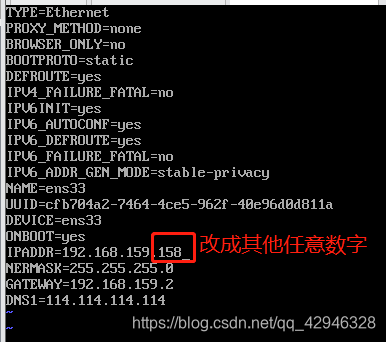
修改ip文件里的ip地址,只需要将ip的最后一位改成任意的数字
vi /etc/sysconfig/network-scripts/ifcfg-ens33
vi /etc/hosts
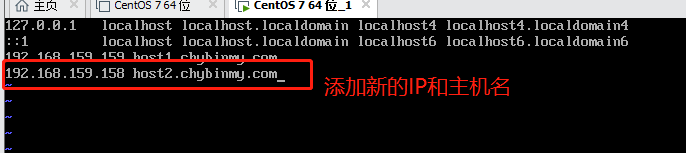
注意:被克隆的虚拟机和克隆后的虚拟机的etc/hosts 都需要添加
重新启动虚拟机
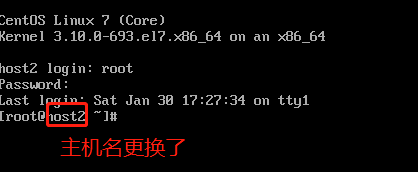
此时host2(ip:192.168.159.158)虚拟机完成克隆,同理再克隆一个host3(ip:192.168.159.157)虚拟机
2 服务器功能规划
确定每个服务器的功能
| host1 | host2 | host3 |
|---|---|---|
| NameNode | ResourceManage | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer | SecondaryNameNode |
3 在第一台机器上安装新的Hadoop
3.1 准备
为了和之前host1机器上安装伪分布式Hadoop区分开来,我们将host1的Hadoop服务都停止掉,然后在一个新的目录/opt/modules/app下安装另外一个Hadoop。
我们采用先在第一台机器上解压、配置Hadoop,然后再分发到其他两台机器上的方式来安装集群。
3.2 解压Hadoop目录:
tar -zxf /opt/hadoop/hadoop-2.10.1.tar.gz -C /opt/modules/app/
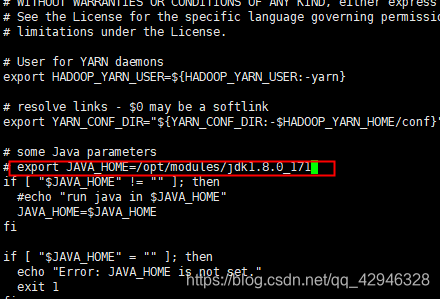
3.3 配置jdk,修改hadoop-env.sh,mapred-env.sh,yarn-env.sh
打开文件hadoop-env.sh,mapred-env.sh,yarn-env.sh,修改JAVA_HOME的路径,如图为JAVA_HOME=/opt/modules/jdk1.8.0_171
[hadoop@host1 ~]$ vi /opt/modules/app/hadoop-2.10.1/etc/hadoop/hadoop-env.sh
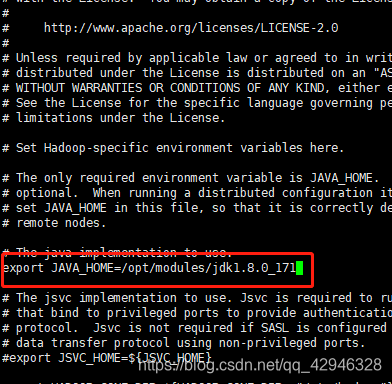
[hadoop@host1 ~]$ vi /opt/modules/app/hadoop-2.10.1/etc/hadoop/mapred-env.sh
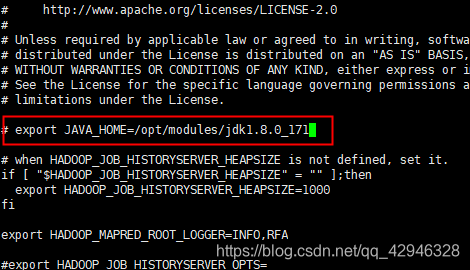
[hadoop@host1 ~]$ vi /opt/modules/app/hadoop-2.10.1/etc/hadoop/yarn-env.sh
3.4 配置core-site.xml
[hadoop@host1 ~]$ cd /opt/modules/app/hadoop-2.10.1
[hadoop@host1 hadoop-2.10.1]$ vi etc/hadoop/core-site.xml
在<configuration>和</configuration>中添加如下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://host1.chybinmy.com:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/app/hadoop-2.10.1/data/tmp</value>
</property>
解释说明:
fs.defaultFS为NameNode的地址。hadoop.tmp.dir为hadoop临时目录的地址,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下
3.5 配置hdfs-site.xml
[hadoop@host1 hadoop-2.10.1]$ vi etc/hadoop/hdfs-site.xml
在<configuration>和</configuration>中添加如下内容
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>host3.chybinmy.com:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/modules/app/hadoop-2.10.1/data/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/modules/app/hadoop-2.10.1/data/tmp/dfs/data</value>
</property>
解释说明:
dfs.namenode.secondary.http-address是指定secondaryNameNode的http访问地址和端口号,因为在规划中,我们将host3规划为SecondaryNameNode服务器。
所以这里设置为:host3.chybinmy.com:50090
3.6 配置slaves
[hadoop@host1 hadoop-2.10.1]$ vi etc/hadoop/slaves
在文件中添加
host1.chybinmy.com
host2.chybinmy.com
host3.chybinmy.com
slaves文件是指定HDFS上有哪些DataNode节点。
3.7 配置yarn-site.xml
[hadoop@host1 hadoop-2.10.1]$ vi etc/hadoop/yarn-site.xml
在<configuration>和</configuration>中添加如下内容
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>host2.chybinmy.com</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
解释说明:
- 根据规划
yarn.resourcemanager.hostname这个指定resourcemanager服务器指向host2.chybinmy.com。 yarn.log-aggregation-enable是配置是否启用日志聚集功能。yarn.log-aggregation.retain-seconds是配置聚集的日志在HDFS上最多保存多长时间。
3.8 配置mapred-site.xml
从mapred-site.xml.template复制一个mapred-site.xml文件。
[hadoop@host1 hadoop-2.10.1]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[hadoop@host1 hadoop-2.10.1]$ vi etc/hadoop/mapred-site.xml
在<configuration>和</configuration>中添加如下内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.159.159:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.159.159:19888</value>
</property>
解释说明:
mapreduce.framework.name设置mapreduce任务运行在yarn上。mapreduce.jobhistory.address是设置mapreduce的历史服务器安装在host1机器上。mapreduce.jobhistory.webapp.address是设置历史服务器的web页面地址和端口号。
4 设置SSH无密码登录
Hadoop集群中的各个机器间会相互地通过SSH访问,每次访问都输入密码是不现实的,所以要配置各个机器间的SSH是无密码登录的。
4.1 生成公钥
首先将用户转为root
su root

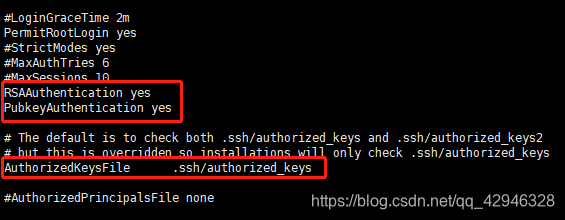
vi /etc/ssh/sshd_config
找到下面三句话,去掉注释,我没有找到RSAAuthentication yes,所以私自直接加上去了
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
重启服务,回到hadoop用户,生成公钥和私钥
service sshd restart
su hadoop
ssh-keygen -t dsa
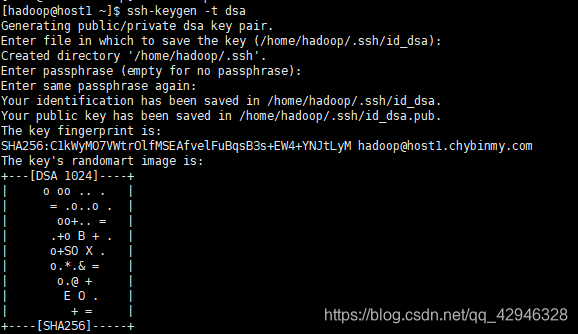
会在/home/hadoop/下生成.ssh文件(该文件为隐藏文件,需要ll -a才能看到),在.ssh下回看到两份文件代表公钥和私钥
将公钥复制到authorized_keys文件中,并改变authorized_keys文件的操作权限,此时ssh本机,如果不需要输入密码,则表明可以走通本机
以上文字的实现直接为以下代码:
cd .ssh
cat id_dsa.pub >> authorized_keys(或者cat id_rsa.pub >> authorized_keys)
chmod 600 authorized_keys
ssh localhost
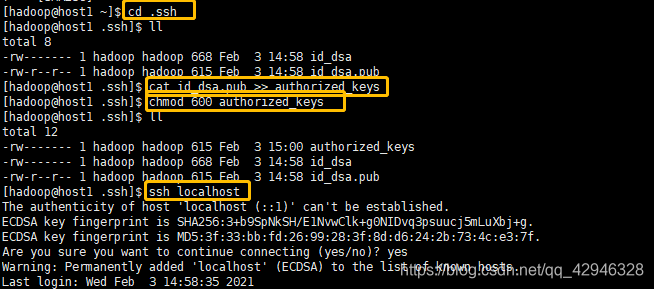
若出现ssh localhost仍然需要输入密码,则尝试如下语句,其中/home/hadoop/根据自己主机用户名灵活变换
chmod 755 /home/hadoop/
chmod 700 ~/.ssh
chmod 644 ~/.ssh/authorized_keys
以上操作同时在host1,host2和host3进行操作! 操作完再进入下一步。
4.2 分发公钥
以下语句的id_dsa.pub根据情况有可能会是id_rsa.pub
cat ~/.ssh/id_dsa.pub | ssh hadoop@host2.chybinmy.com 'cat - >> ~/.ssh/authorized_keys'
cat ~/.ssh/id_dsa.pub | ssh hadoop@host3.chybinmy.com 'cat - >> ~/.ssh/authorized_keys'
同样在host2, host3中做分发密钥的操作
验证SSH无密码登录是否成功,直接ssh 主机名
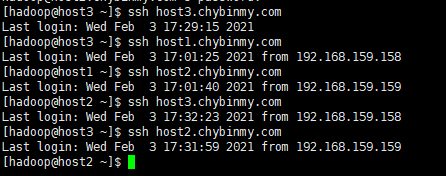
5 分发Hadoop文件
首先在其他两台机器上创建存放Hadoop的目录
[hadoop@host2 ~]$ mkdir /opt/modules/app
[hadoop@host3 ~]$ mkdir /opt/modules/app
通过Scp分发
Hadoop根目录下的share/doc目录是存放的hadoop的文档,文件相当大,建议在分发之前将这个目录删除掉,可以节省硬盘空间并能提高分发的速度。
[hadoop@host1 hadoop-2.5.0]$ du -sh /opt/modules/app/hadoop-2.10.1/share/doc
[hadoop@host1 hadoop-2.5.0]$ scp -r /opt/modules/app/hadoop-2.10.1/ 192.168.159.158:/opt/modules/app
[hadoop@host1 hadoop-2.5.0]$ scp -r /opt/modules/app/hadoop-2.10.1/192.168.159.157:/opt/modules/app
6 格式NameNode
在NameNode机器(host1)上执行格式化:
[hadoop@host1 hadoop-2.10.1]$ /opt/modules/app/hadoop-2.10.1/bin/hdfs namenode -format
注意:
如果需要重新格式化NameNode,需要先对每个主机都将下图中的两个文件夹删除(其中data文件夹就是在core-site.xml中配置的hadoop.tmp.dir)

因为每次格式化,默认是创建一个集群ID,并写入NameNode和DataNode的VERSION文件中(VERSION文件所在目录为dfs/name/current和 dfs/data/current),重新格式化时,默认会生成一个新的集群ID,如果不删除原来的目录,会导致namenode中的VERSION文件中是新的集群ID,而DataNode中是旧的集群ID,不一致时会报错。
另一种方法是格式化时指定集群ID参数,指定为旧的集群ID。
7 启动集群
7.1 启动HDFS
[hadoop@host1 ~]$ /opt/modules/app/hadoop-2.10.1/sbin/start-dfs.sh
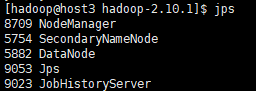
[hadoop@host1 ~]$ jps
对三个主机分别jps,出现下面三张图就说明启动成功
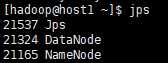
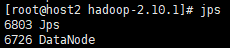

若要关闭HDFS,则用如下语句
[hadoop@host1 ~]$ /opt/modules/app/hadoop-2.10.1/sbin/stop-dfs.sh
7.2 启动YARN
在host1上启动YARN
[hadoop@host1 ~]$ /opt/modules/app/hadoop-2.10.1/sbin/start-yarn.sh
在host2上启动ResourceManager:
[hadoop@host2 hadoop-2.10.1]$ /opt/modules/app/hadoop-2.10.1/sbin/yarn-daemon.sh start resourcemanager
[hadoop@host2 hadoop-2.10.1]$ jps

7.3 启动日志服务器
因为我们规划的是在host3服务器上运行MapReduce日志服务,所以要在host3上启动
[hadoop@host3 hadoop-2.10.1]$ /opt/modules/app/hadoop-2.10.1/sbin/mr-jobhistory-daemon.sh start historyserver
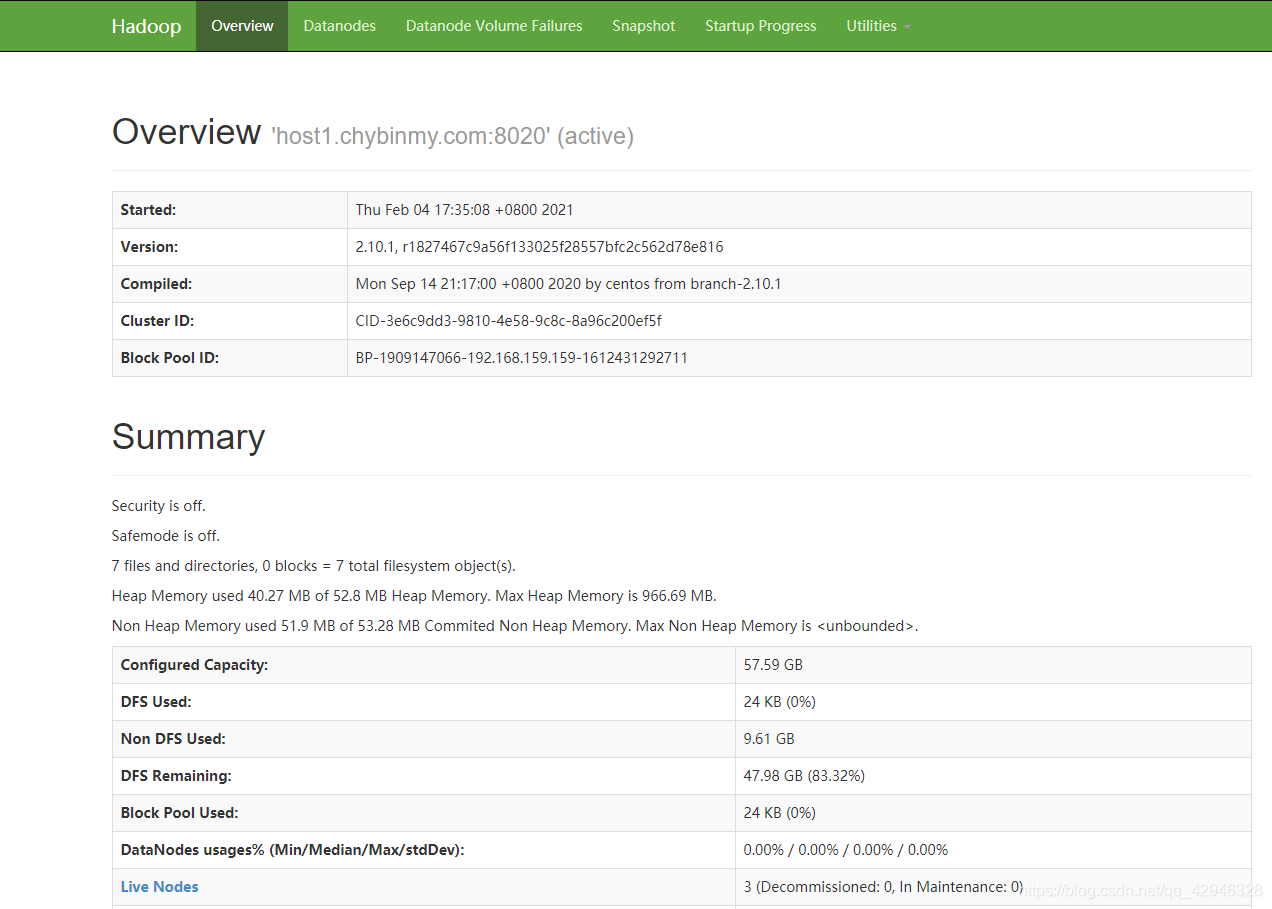
7.4 查看HDFS Web页面
http://192.168.159.159:50070/(网址根据你自己的ip来改动,这里的ip是host1的IP)
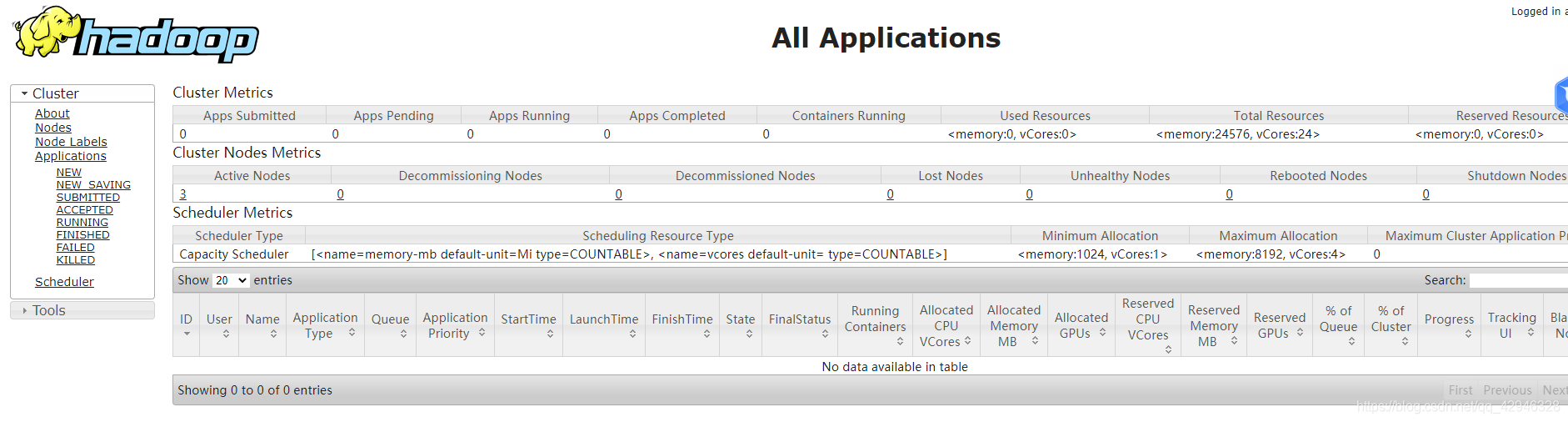
7.5 查看YARN Web 页面
http://192.168.159.158:8088/cluster(网址根据你自己的ip来改动,这里的ip是host2的IP)
8 测试Job
这里用hadoop自带的wordcount例子来在本地模式下测试跑mapreduce。
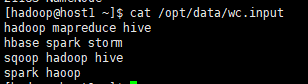
8.1 准备mapreduce输入文件wc.input
[hadoop@host1 ~]$ cat /opt/data/wc.input
8.2 在HDFS创建输入目录input
[hadoop@host1 ~]$ cd /opt/modules/app/hadoop-2.10.1
[hadoop@host1 hadoop-2.10.1]$ bin/hdfs dfs -mkdir /input
将wc.input上传到HDFS
[hadoop@host1 hadoop-2.10.1]$ bin/hdfs dfs -put /opt/data/wc.input /input/wc.input
8.3 运行hadoop自带的mapreduce Demo
[hadoop@host1 hadoop-2.10.1]$ bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.1.jar wordcount /input/wc.input /output
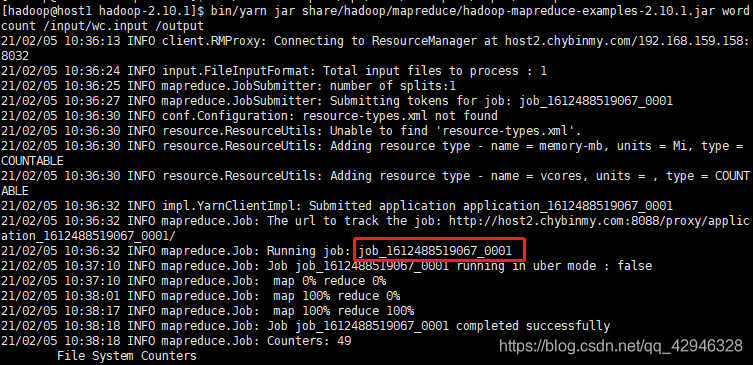
8.4 查看输出文件
[hadoop@host1 hadoop-2.10.1]$ bin/hdfs dfs -ls /output
