本文是根据尚硅谷的视频教学,然后加上自己理解总结的。
配置hdfs和yarn如下:

所有的配置文件都在/opt/module/hadoop-2.7.7/etc/hadoop目录下。
[root@hadoop102 hadoop]#
[root@hadoop102 hadoop]# pwd
/opt/module/hadoop-2.7.7/etc/hadoop
[root@hadoop102 hadoop]#
[root@hadoop102 hadoop]#
[root@hadoop102 hadoop]#
[root@hadoop102 hadoop]#
[root@hadoop102 hadoop]# ll
total 156
-rw-r--r-- 1 zhenghui zhenghui 4436 Jul 18 2018 capacity-scheduler.xml
-rw-r--r-- 1 zhenghui zhenghui 1335 Jul 18 2018 configuration.xsl
-rw-r--r-- 1 zhenghui zhenghui 318 Jul 18 2018 container-executor.cfg
-rw-r--r-- 1 zhenghui zhenghui 1096 Jan 29 07:18 core-site.xml
-rw-r--r-- 1 zhenghui zhenghui 3670 Jul 18 2018 hadoop-env.cmd
-rw-r--r-- 1 zhenghui zhenghui 4236 Jan 27 17:16 hadoop-env.sh
-rw-r--r-- 1 zhenghui zhenghui 2598 Jul 18 2018 hadoop-metrics2.properties
-rw-r--r-- 1 zhenghui zhenghui 2490 Jul 18 2018 hadoop-metrics.properties
-rw-r--r-- 1 zhenghui zhenghui 9683 Jul 18 2018 hadoop-policy.xml
-rw-r--r-- 1 zhenghui zhenghui 1113 Jan 29 08:23 hdfs-site.xml
-rw-r--r-- 1 zhenghui zhenghui 1449 Jul 18 2018 httpfs-env.sh
-rw-r--r-- 1 zhenghui zhenghui 1657 Jul 18 2018 httpfs-log4j.properties
-rw-r--r-- 1 zhenghui zhenghui 21 Jul 18 2018 httpfs-signature.secret
-rw-r--r-- 1 zhenghui zhenghui 620 Jul 18 2018 httpfs-site.xml
-rw-r--r-- 1 zhenghui zhenghui 3518 Jul 18 2018 kms-acls.xml
-rw-r--r-- 1 zhenghui zhenghui 1527 Jul 18 2018 kms-env.sh
-rw-r--r-- 1 zhenghui zhenghui 1631 Jul 18 2018 kms-log4j.properties
-rw-r--r-- 1 zhenghui zhenghui 5540 Jul 18 2018 kms-site.xml
-rw-r--r-- 1 zhenghui zhenghui 11801 Jul 18 2018 log4j.properties
-rw-r--r-- 1 zhenghui zhenghui 951 Jul 18 2018 mapred-env.cmd
-rw-r--r-- 1 zhenghui zhenghui 1380 Jan 28 06:44 mapred-env.sh
-rw-r--r-- 1 zhenghui zhenghui 4113 Jul 18 2018 mapred-queues.xml.template
-rw-r--r-- 1 zhenghui zhenghui 1187 Jan 29 21:40 mapred-site.xml
-rw-r--r-- 1 zhenghui zhenghui 758 Jul 18 2018 mapred-site.xml.template
-rw-r--r-- 1 zhenghui zhenghui 30 Jan 29 20:55 slaves
-rw-r--r-- 1 zhenghui zhenghui 2316 Jul 18 2018 ssl-client.xml.example
-rw-r--r-- 1 zhenghui zhenghui 2697 Jul 18 2018 ssl-server.xml.example
-rw-r--r-- 1 zhenghui zhenghui 2250 Jul 18 2018 yarn-env.cmd
-rw-r--r-- 1 zhenghui zhenghui 4564 Jan 28 06:38 yarn-env.sh
-rw-r--r-- 1 zhenghui zhenghui 1740 Jan 29 21:44 yarn-site.xml
[root@hadoop102 hadoop]#
分别配置以下文件:
hadoop-env.sh
mapred-env.sh
yarn-env.sh
以上文件全部都添加JAVA环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_221
配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定HDFS副本的数量,默认是三个,因为现在只有1个节点-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--指定Hadoop辅助名称节点主机配置-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:50090</value>
</property>
</configuration>
配置mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--指定MR运行在YARN上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--历史服务器端地址-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop104:10020</value>
</property>
<!--历史服务器web端地址-->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop104:19888</value>
</property>
</configuration>
配置yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop103:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop103:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop103:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop103:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop103:8088</value>
</property>
<!--日志聚集功能使能-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
配置slaves
添加从服务器地址
hadoop102
hadoop103
hadoop104
修改完之后记得把配置文件同步到其他的机器上
copypath是一个脚本,如果大家不知道怎么写,可以访问:
https://blog.csdn.net/qq_17623363/article/details/104108316
[root@hadoop102 hadoop]#
[root@hadoop102 hadoop]# cd ..
[root@hadoop102 etc]# cd ..
[root@hadoop102 hadoop-2.7.7]#
[root@hadoop102 hadoop-2.7.7]#
[root@hadoop102 hadoop-2.7.7]# copypath etc
count=1
fname=etc
pdir=/opt/module/hadoop-2.7.7
-------------hadoop102-------------
root@hadoop102's password:
sending incremental file list
sent 920 bytes received 18 bytes 208.44 bytes/sec
total size is 80,771 speedup is 86.11
-------------hadoop103-------------
root@hadoop103's password:
sending incremental file list
etc/hadoop/
etc/hadoop/hdfs-site.xml
etc/hadoop/yarn-site.xml
sent 3,216 bytes received 93 bytes 441.20 bytes/sec
total size is 80,771 speedup is 24.41
-------------hadoop104-------------
root@hadoop104's password:
sending incremental file list
etc/hadoop/
etc/hadoop/hdfs-site.xml
etc/hadoop/yarn-site.xml
sent 3,216 bytes received 93 bytes 945.43 bytes/sec
total size is 80,771 speedup is 24.41
[root@hadoop102 hadoop-2.7.7]#
[root@hadoop102 hadoop-2.7.7]#
启动
hadoop102 上: start-dfs.sh
hadoop103上:start-yarn.sh
hadoop104上:hadoop-daemon.sh start secondarynamenode
hadoop104上:mr-jobhistory-daemon.sh start historyserver //历史服务功能
如果历史服务功能不知道怎么配置,可以查看:
https://blog.csdn.net/qq_17623363/article/details/104112878
查看进程是否全部启动
[root@hadoop102 ~]#
[root@hadoop102 ~]# jps
16851 NameNode
17240 NodeManager
20187 Jps
16991 DataNode
[root@hadoop102 ~]#
[root@hadoop103 ~]#
[root@hadoop103 ~]# jps
5875 NodeManager
5764 ResourceManager
7015 Jps
5645 DataNode
[root@hadoop103 ~]#
[root@hadoop103 ~]#
[root@hadoop103 ~]#
[zhenghui@hadoop104 ~]$
[zhenghui@hadoop104 ~]$
[zhenghui@hadoop104 ~]$ jps
5681 DataNode
5866 NodeManager
5788 SecondaryNameNode
7357 Jps
6014 JobHistoryServer
[zhenghui@hadoop104 ~]$
测试结果
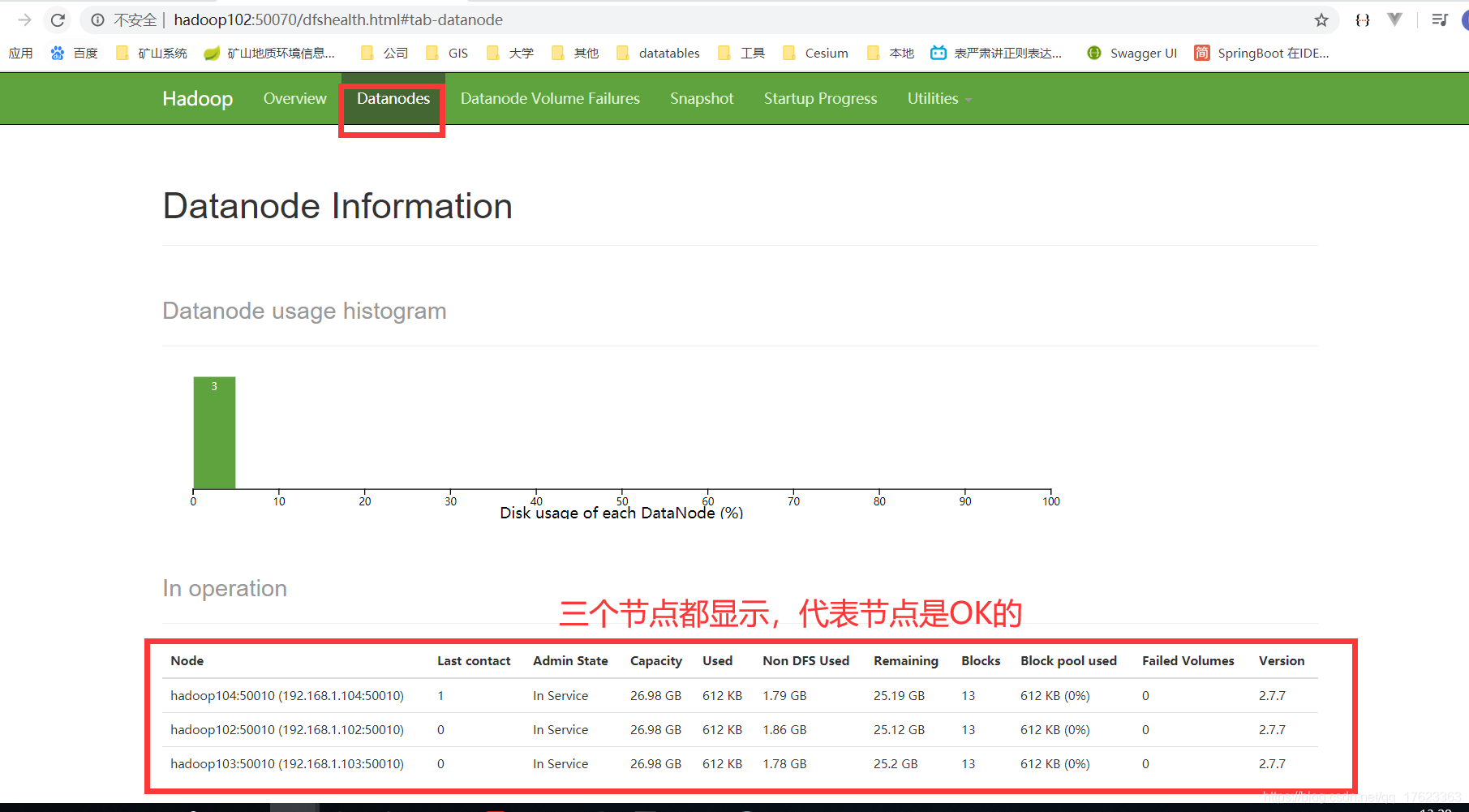
1、访问http://hadoop102:50070/
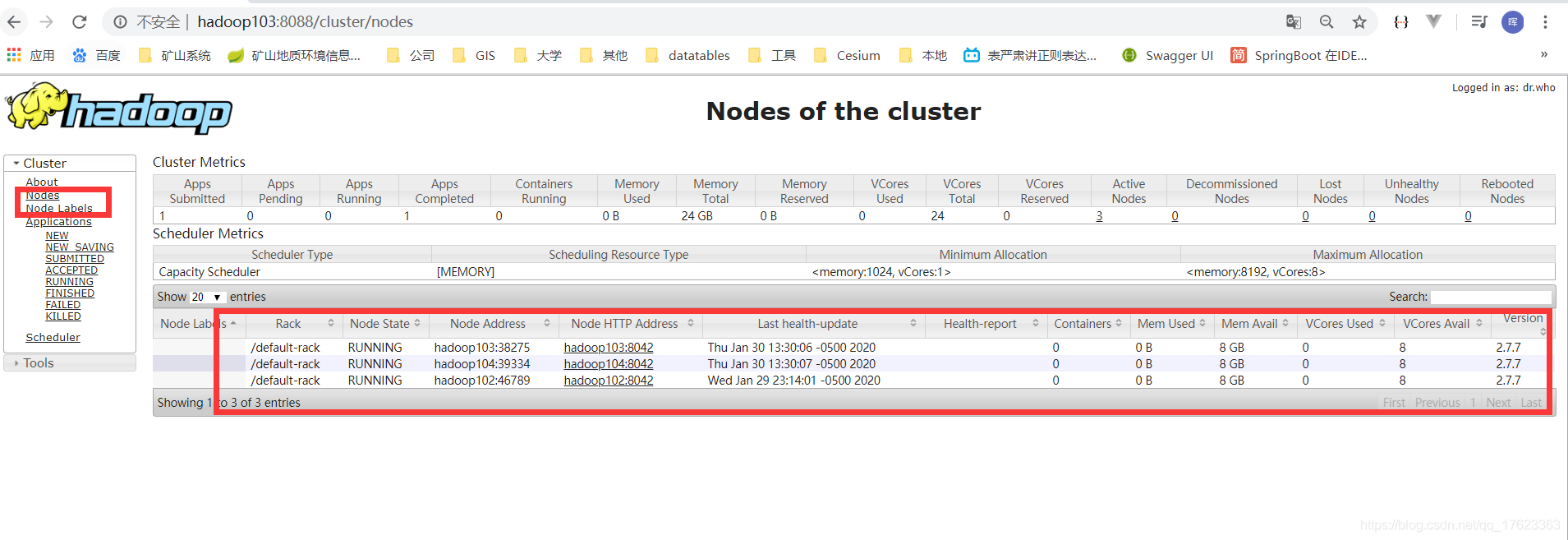
2、访问http://hadoop103:8088/
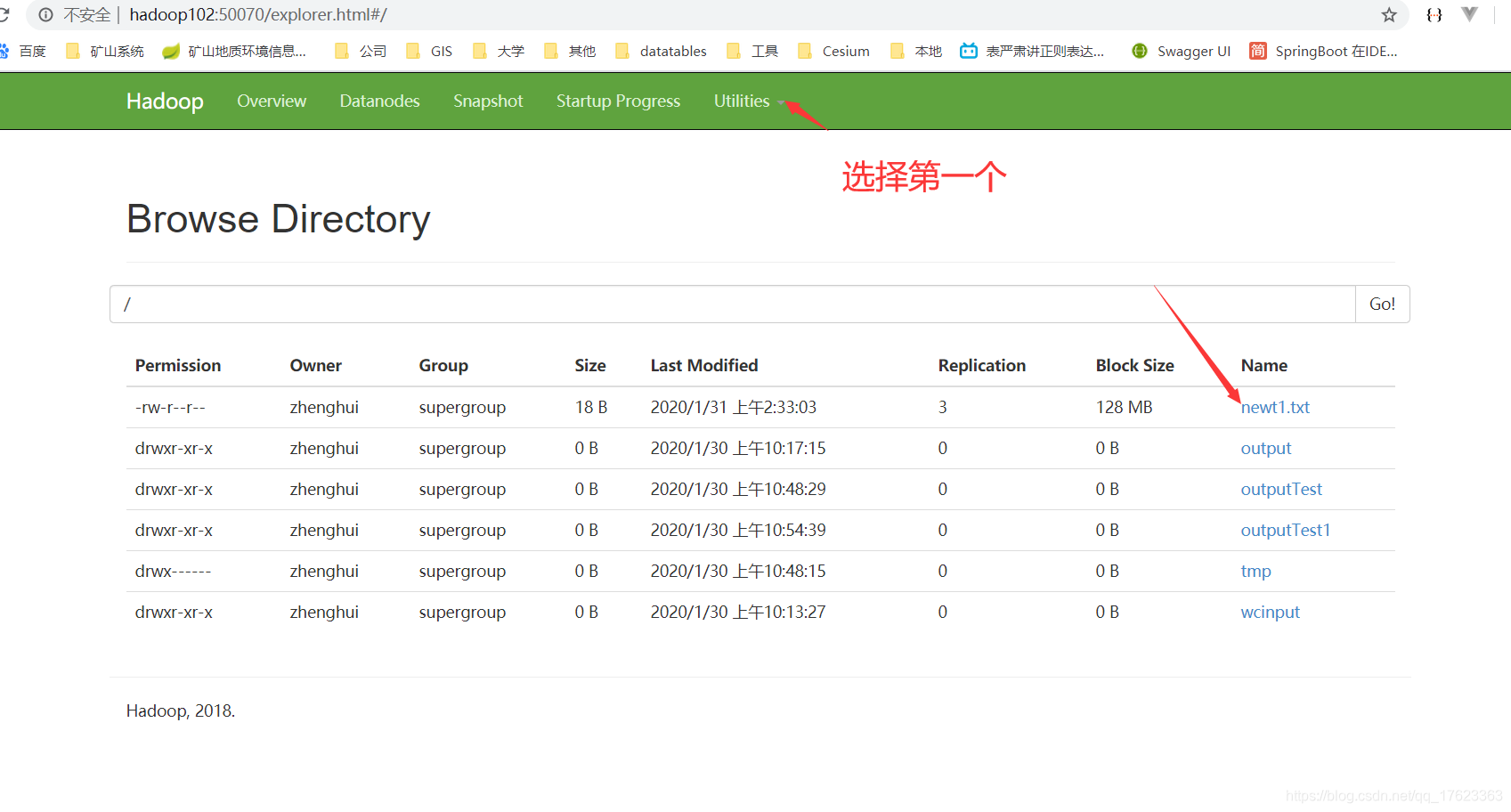
3、测试上传
[zhenghui@hadoop102 hadoop-2.7.7]$ touch newt1.txt
[zhenghui@hadoop102 hadoop-2.7.7]$ echo "This is newt1.txt" >> newt1.txt
[zhenghui@hadoop102 hadoop-2.7.7]$ hadoop fs -put newt1.txt / [zhenghui@hadoop102 hadoop-2.7.7]$
可以看出上传成功了。
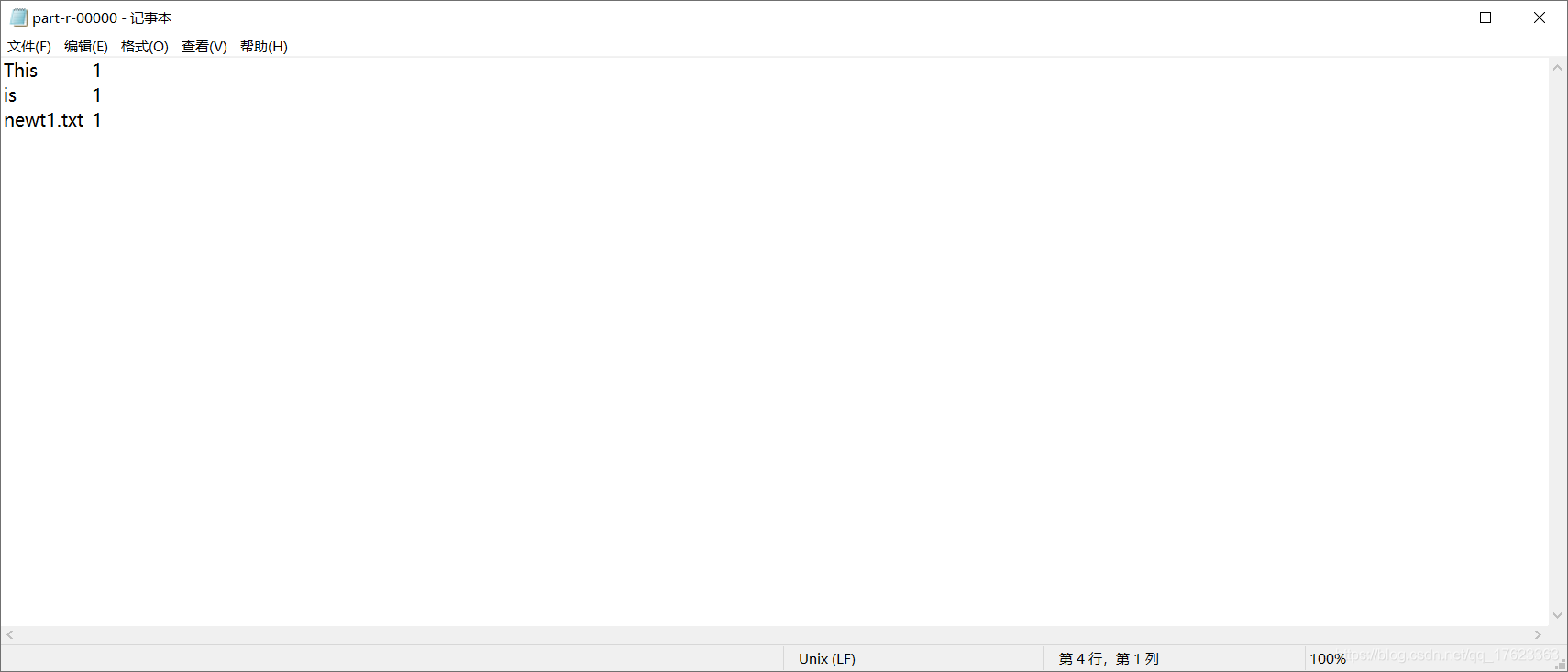
4、测试wordcount统计功能是否可用
[zhenghui@hadoop102 hadoop-2.7.7]$
[zhenghui@hadoop102 hadoop-2.7.7]$
[zhenghui@hadoop102 hadoop-2.7.7]$
[zhenghui@hadoop102 hadoop-2.7.7]$ hadoop fs -put newt1.txt / [zhenghui@hadoop102 hadoop-2.7.7]$
[zhenghui@hadoop102 hadoop-2.7.7]$
[zhenghui@hadoop102 hadoop-2.7.7]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /newt1.txt /newt1_output.txt
20/01/30 13:35:23 INFO client.RMProxy: Connecting to ResourceManager at hadoop103/192.168.1.103:8032
20/01/30 13:35:23 INFO input.FileInputFormat: Total input paths to process : 1
20/01/30 13:35:24 INFO mapreduce.JobSubmitter: number of splits:1
20/01/30 13:35:24 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1580352839303_0002
20/01/30 13:35:24 INFO impl.YarnClientImpl: Submitted application application_1580352839303_0002
20/01/30 13:35:24 INFO mapreduce.Job: The url to track the job: http://hadoop103:8088/proxy/application_1580352839303_0002/
20/01/30 13:35:24 INFO mapreduce.Job: Running job: job_1580352839303_0002
20/01/30 13:35:30 INFO mapreduce.Job: Job job_1580352839303_0002 running in uber mode : false
20/01/30 13:35:30 INFO mapreduce.Job: map 0% reduce 0%
20/01/30 13:35:36 INFO mapreduce.Job: map 100% reduce 0%
20/01/30 13:35:46 INFO mapreduce.Job: map 100% reduce 100%
20/01/30 13:35:46 INFO mapreduce.Job: Job job_1580352839303_0002 completed successfully
20/01/30 13:35:47 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=42
FILE: Number of bytes written=245329
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=114
HDFS: Number of bytes written=24
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3606
Total time spent by all reduces in occupied slots (ms)=6806
Total time spent by all map tasks (ms)=3606
Total time spent by all reduce tasks (ms)=6806
Total vcore-milliseconds taken by all map tasks=3606
Total vcore-milliseconds taken by all reduce tasks=6806
Total megabyte-milliseconds taken by all map tasks=3692544
Total megabyte-milliseconds taken by all reduce tasks=6969344
Map-Reduce Framework
Map input records=1
Map output records=3
Map output bytes=30
Map output materialized bytes=42
Input split bytes=96
Combine input records=3
Combine output records=3
Reduce input groups=3
Reduce shuffle bytes=42
Reduce input records=3
Reduce output records=3
Spilled Records=6
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=133
CPU time spent (ms)=1570
Physical memory (bytes) snapshot=411852800
Virtual memory (bytes) snapshot=4210016256
Total committed heap usage (bytes)=269484032
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=18
File Output Format Counters
Bytes Written=24
[zhenghui@hadoop102 hadoop-2.7.7]$
可以看出测试成功
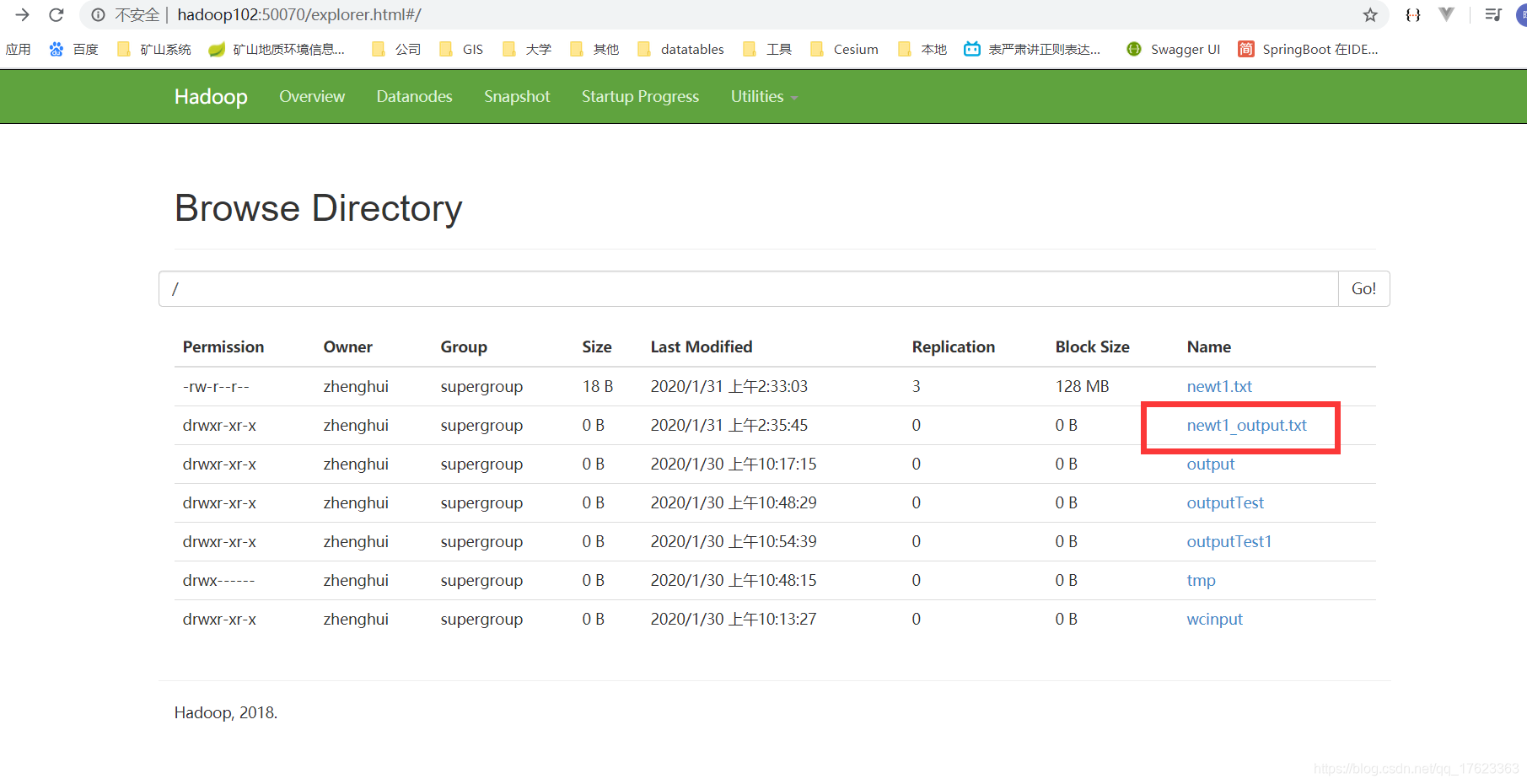
点进去,下载查看是否成功
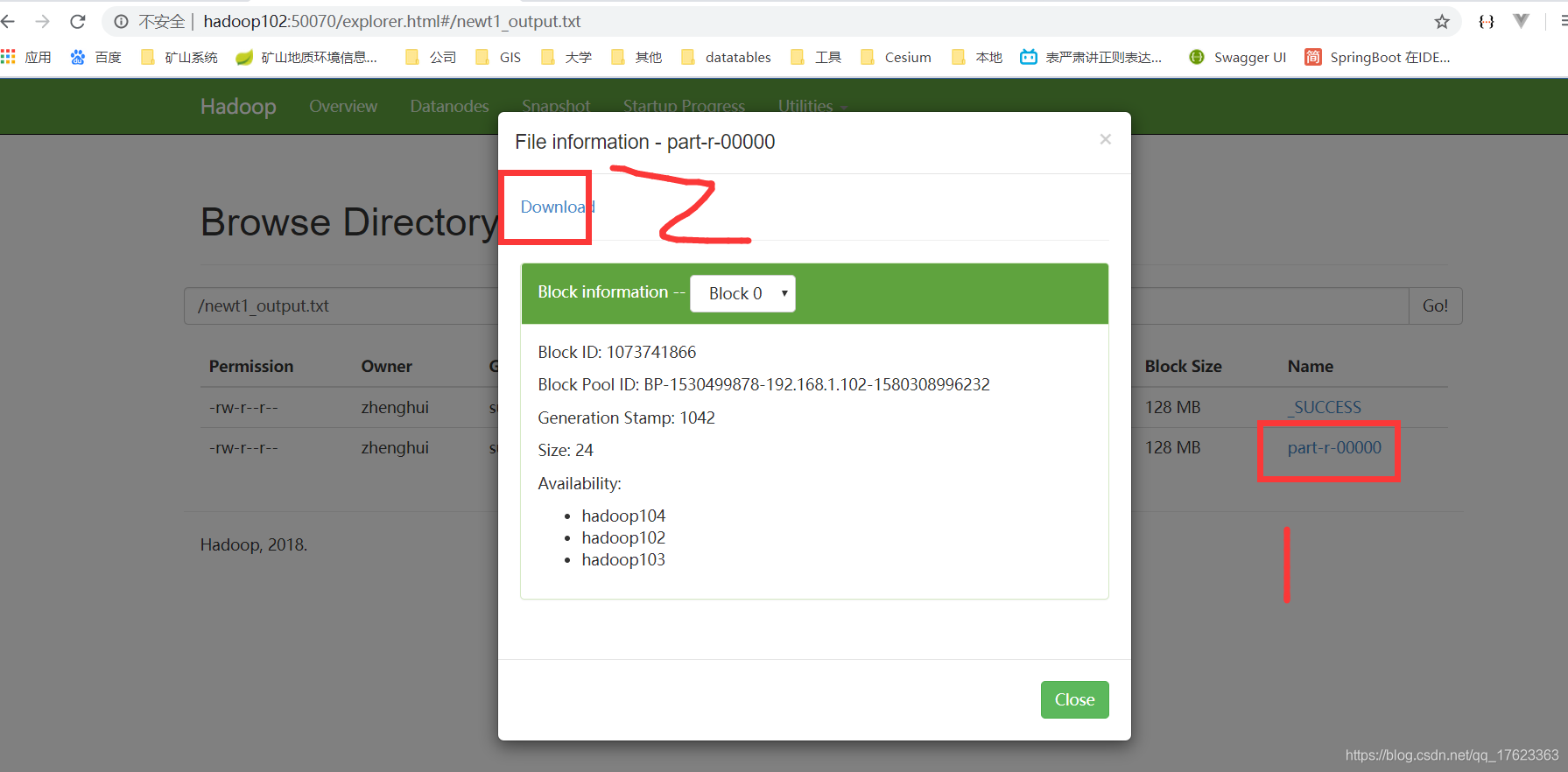
统计成功