版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_40693171/article/details/83317694
- 知道python有强大的的爬虫库,但是对于我们普通小白来说,写一个完整的爬虫需要知道什么甚至了解什么都是很重要的。掌握了这些基本点,才能够熟悉爬虫的构成和获取有用的信息。
- 编写一个小爬虫个人感觉可以分为三个阶段:
- 1:请求,这个就是使用urlib2或者requests发送http请求。要掌握期中一些用法以及一些常用的请求方式。
- 2:解析,当得到一个网页的html,我们要用一些工具解析文件,获得我们需要的信息。常见是beautifulsoup解析大部分加部分正则。
- 3:存储:将信息写入mysql或本地。(mysql,file文件传输读写)
-当然,面对更大的爬虫,可能有更多的步骤,比如函数建模,去重,等等。
本文主要记录在学习请求部分的过程!
urllib板块:
python内置urllib版块,支持header,cookie,ip代理池等操作,但是比较麻烦的就是每次都要处理编码解码问题,搞得有点繁琐。 - urllib2 在 python3.x 中被改为urllib.request,一般为了使用习惯,导入时命名为urllib2:import urllib.request as urllib2。
get请求
一个基本的百度请求的代码如下:
import urllib.request as urllib2
header={"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}#模仿浏览器
request = urllib2.Request('http://www.baidu.com',headers=header)
response = urllib2.urlopen(request)
buff = response.read()
html = buff.decode()
print(html)
对于有url拼凑的地址:例如有
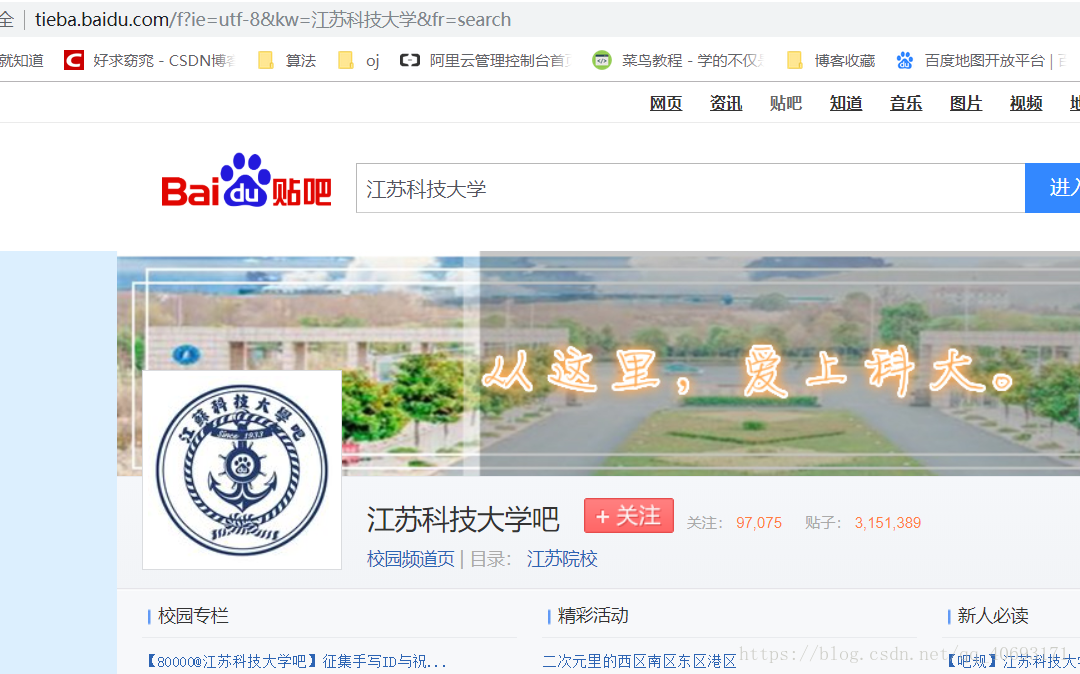
- 这样就要添加data信息(或者你直接拼凑url)
比如我要请求这个页面,就要在data字典组添加对应的查询头信息,并且还需要url编码转换成浏览器能够标识的字串。
编码工作使用urllib.parse的urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串,解码工作可以使用urllib的unquote()函数。(注意,不是urllib.urlencode())
代码为:
import urllib.request as urllib2
import urllib.parse
url = "http://tieba.baidu.com/f"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0"}
formdata = {
"ie":"utf-8",
"kw":"江苏科技大学",
"fr":"search"
}
data = urllib.parse.urlencode(formdata)#要转换成url编码
newurl=url+'?'+data
print(data)
request = urllib2.Request(newurl, headers = headers)
response = urllib2.urlopen(request)
html=response.read().decode("utf-8")
print( html)
可以看到,这样已经请求成功了呢。
post请求:post请求和get请求的不同之处在于传递参数的方式,get通过url拼凑进行不同的请求,而post请求则是将data放进请求列中进行模拟类似表单的请求。
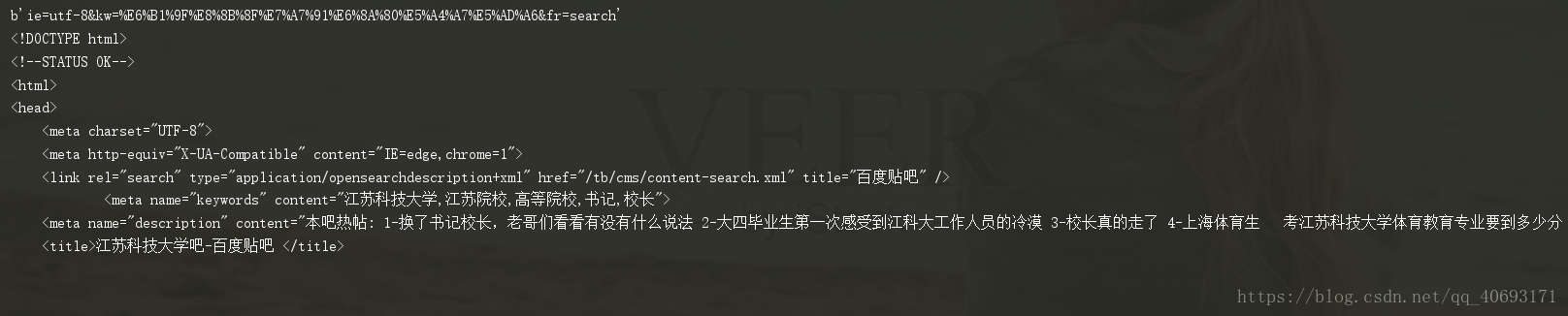
import urllib.request as urllib2
import urllib.parse
url = "http://tieba.baidu.com/f"
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0"}
formdata = {
"ie":"utf-8",
"kw":"江苏科技大学",
"fr":"search"
}
data = urllib.parse.urlencode(formdata).encode('utf-8')#要转换成url编码
print(data)
request = urllib2.Request(url, data = data, headers = headers)
response = urllib2.urlopen(request)
html=response.read().decode("utf-8")
print( html)
这大概就是常用的urllib的使用方式了,期中感觉请求步骤和编码问题都比较麻烦。requests很好的解决了这个问题。
requests(如果没有安装在teminal控制台pip install requests即可)
对于requests的一个最基本的请求流程为
import requests
url = "https://www.neihan8.com/article/list_5_" + "1" + ".html"
userangert = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
header = {'User-Agent': userangert}
req = requests.get(url, headers=header)
#乱码问题的解决方案油两个
req.encoding='gbk'
print(req.text)
#html = req.content#contenet是流内容,可以获得图片等信息。
#print(html.decode('gbk'))
注意如果输出乱码要注意解决。同样,如果是post请求,直接request.post即可,同时requests是从urllib编写而来,支持urllib的绝大部分操作。比如cookie管理,ip代理等等。
- 作为爬虫,经常会通过抓包找到数据源的json文件,如果是直接返回response.json()。
下面通过代码给出区别:
import requests
formdata = {
"type":"AUTO",
"i":"i love python",
"doctype":"json",
"xmlVersion":"1.8",
"keyfrom":"fanyi.web",
"ue":"UTF-8",
"action":"FY_BY_ENTER",
"typoResult":"true"
}
url = "http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom=null"
headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36"}
response = requests.post(url, data = formdata, headers = headers)
print (response.text)
# 如果是json文件可以直接显示
print (response.json())
输出为:
至于这个请求错误,原因是我的请求头不够完善,模拟不够好,可以通过抓包近似完全模拟请求。有兴趣的可以试试。

写的并不是很好,本人也是初学者,希望可以一起交流经验。总的来说requests效率更高更便捷,还是推荐使用requests!