空集群
- 只有一个空节点的集群
- 一个节点(node)就是一个Elasticsearch实例,而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数据和负载。当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据。
- 集群中一个节点会被选举为主节点(master),它将临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。任何节点都可以成为主节点。我们例子中的集群只有一个节点,所以它会充当主节点的角色。
- 做为用户,我们能够与集群中的任何节点通信,包括主节点。每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
集群健康
- 集群健康有三种状态:green、yellow或red
GET /_cluster/health
{
"cluster_name": "elasticsearch",
"status": "green", //状态
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
| green |
所有主要分片和复制分片都可用 |
| yellow |
所有主要分片可用,但不是所有复制分片都可用 |
| red |
不是所有的主要分片都可用 |
添加索引
- 为了将数据添加到Elasticsearch,我们需要索引(index)——一个存储关联数据的地方。实际上,索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”。
- 一个分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分。一个分片就是一个Lucene实例
- 您可以在集群节点上保存的分片数量与您可用的堆内存大小成正比,但这在Elasticsearch中没有的固定限制。 一个很好的经验法则是:确保每个节点的分片数量保持在低于每1GB堆内存对应集群的分片在20-25之间。 因此,具有30GB堆内存的节点最多可以有600-750个分片,但是进一步低于此限制,您可以保持更好。 这通常会帮助群体保持处于健康状态。
- 分片大小为50GB通常被界定为适用于各种用例的限制
- 为了演示的目的,我们只分配3个主分片和一个复制分片(每个主分片都有一个复制分片)
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
{
"cluster_name": "elasticsearch",
"status": "yellow", //状态
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3 <2>
}

- 状态为yelloww,因为只有主节点,复制节点没有被分配
增加故障转移
- 在单一节点上运行意味着有单点故障的风险——没有数据备份。幸运的是,要防止单点故障,我们唯一需要做的就是启动另一个节点
- 只要第二个节点与第一个节点有相同的cluster.name(请看./config/elasticsearch.yml文件),它就能自动发现并加入第一个节点所在的集群
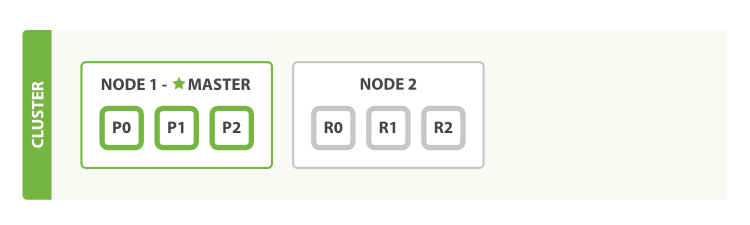
横向扩展
- 如果我们启动第三个节点,我们的集群会重新组织自己
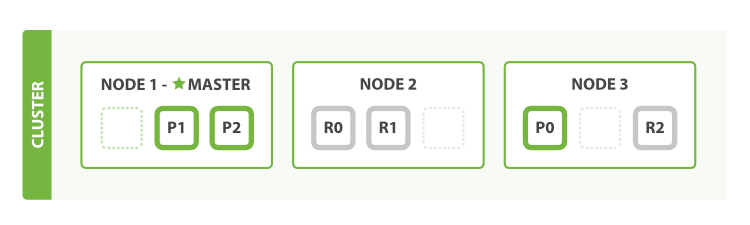
继续扩展
- 主分片的数量在创建索引时已经确定。实际上,这个数量定义了能存储到索引里数据的最大数量(实际的数量取决于你的数据、硬件和应用场景)。然而,主分片或者复制分片都可以处理读请求——搜索或文档检索,所以数据的冗余越多,我们能处理的搜索吞吐量就越大。
- 复制分片的数量从原来的1增加到2
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
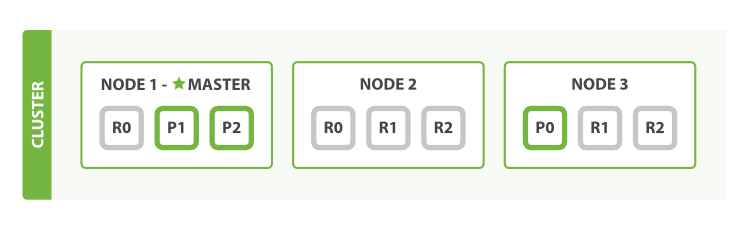
- 这样使我们的搜索性能相比原始的三节点集群增加三倍
- 在同样数量的节点上增加更多的复制分片并不能提高性能,因为这样做的话平均每个分片的所占有的硬件资源就减少了
- 不过这些额外的复制节点使我们有更多的冗余:通过以上对节点的设置,我们能够承受两个节点故障而不丢失数据
应对故障(3个主分片,6个副本节点)
- 杀掉第一个节点的进程
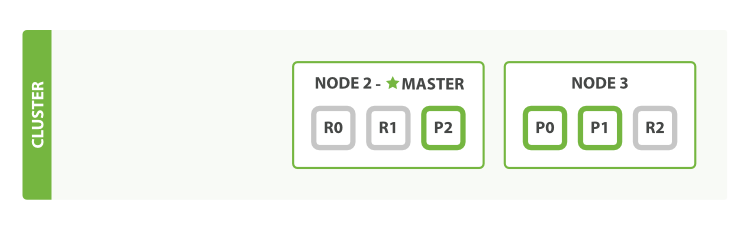
- 我们杀掉的节点是一个主节点。一个集群必须要有一个主节点才能使其功能正常,所以集群做的第一件事就是各节点选举了一个新的主节点:Node 2。
- 主分片1和2在我们杀掉Node 1时已经丢失,我们的索引在丢失主分片时不能正常工作。如果此时我们检查集群健康,我们将看到状态red:不是所有主分片都可用!
- 但丢失的两个主分片的完整拷贝存在于其他节点上,所以新主节点做的第一件事是把这些在Node 2和Node 3上的复制分片升级为主分片,这时集群健康回到yellow状态。这个提升是瞬间完成的,就好像按了一下开关。
- 当我们杀掉Node 2,我们的程序依然可以在没有丢失数据的情况下继续运行,因为Node 3还有每个分片的拷贝。
- 如果我们重启Node 1,集群将能够重新分配丢失的复制分片