ElasticSearch权威指南学习
文章目录
1:基础入门
1.1:ElasticSearch交互:检索
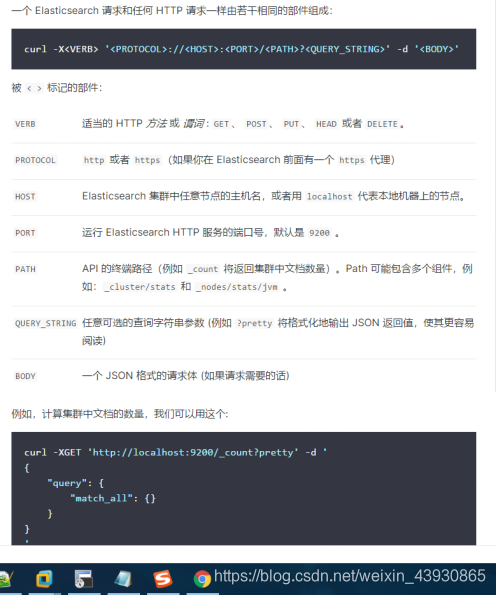
1.1.1:使用
GET /index/type/id
返回结果包含了文档的一些元数据,以及 _source 属性为保存的数据
2:分布式存储原理
在 Elasticsearch 中, 每个字段的所有数据 都是 默认被索引的 。 即每个字段都有为了快速检索设置的专用倒排索引
2.1:文档
在 Elasticsearch 中,术语 文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
文档元数据:
文档元数据:一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index
文档在哪存放
_type
文档表示的对象类别
_id
文档唯一标识
2.1文档的路由机制
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?
shard = hash(routing) % number_of_primary_shards
routing 是一个可变值,默认是文档的 _id ,也可以设置成一个自定义的值。 routing 通过 hash 函数生成一个数字,然后这个数字再除以 number_of_primary_shards (主分片的数量)后得到 余数 。这个分布在 0 到 number_of_primary_shards-1 之间的余数,就是我们所寻求的文档所在分片的位置
2.2:文档的搜索结果分析
hits
返回结果中最重要的部分是 hits ,它包含 total 字段来表示匹配到的文档总数,并且一个 hits 数组包含所查询结果的前十个文档。
在 hits 数组中每个结果包含文档的 _index 、 _type 、 _id ,加上 _source 字段。这意味着我们可以直接从返回的搜索结果中使用整个文档。这不像其他的搜索引擎,仅仅返回文档的ID,需要你单独去获取文档。
每个结果还有一个 _score ,它衡量了文档与查询的匹配程度。默认情况下,首先返回最相关的文档结果,就是说,返回的文档是按照 _score 降序排列的。在这个例子中,我们没有指定任何查询,故所有的文档具有相同的相关性,因此对所有的结果而言 1 是中性的 _score 。
max_score 值是与查询所匹配文档的 _score 的最大值。
took
took 值告诉我们执行整个搜索请求耗费了多少毫秒。
shards
_shards 部分告诉我们在查询中参与分片的总数,以及这些分片成功了多少个失败了多少个。正常情况下我们不希望分片失败,但是分片失败是可能发生的。如果我们遭遇到一种灾难级别的故障,在这个故障中丢失了相同分片的原始数据和副本,那么对这个分片将没有可用副本来对搜索请求作出响应。假若这样,Elasticsearch 将报告这个分片是失败的,但是会继续返回剩余分片的结果。
timeout
timed_out 值告诉我们查询是否超时。默认情况下,搜索请求不会超时。如果低响应时间比完成结果更重要,你可以指定 timeout 为 10 或者 10ms(10毫秒),或者 1s(1秒):
3:倒排索引以及分析
3.1:倒排索引
倒排索引包含一个有序列表,列表包含所有文档出现过的不重复个体,或称为 词项 ,对于每一个词项,包含了它所有曾出现过文档的列表。存储在磁盘。
**Term | Doc 1 | Doc 2 | Doc 3 | ...
brown | X | | X | ...
fox | X | X | X | ...
quick | X | X | | ...
the | X | | X | ...**
索引的构成
segment:一个索引包含多个段,每个段包含一部分索引的操作记录,定期刷新到索引完成更新
可以通过setting设置 refresh_interval , 降低每个索引的刷新频率:优化索引速度而不是近实时搜索
translog :translog 的目的是保证操作不会丢失
为了保证segment刷新的非实时缺陷,又不保证数据丢失的情况(段未提交集群挂了),
所有的操作同时也会写入 translog中,每隔一段时间—例如 translog 变得越来越大—索引被刷新(flush);
一个新的 translog 被创建,并且一个全量提交被执行,translog清空
translog 提供所有还没有被刷到磁盘的操作的一个持久化纪录。当 Elasticsearch 启动的时候, 它会从磁盘中使用最后一个提交点去恢复已知的段,并且会重放 translog 中所有在最后一次提交后发生的变更操作。
3.1.1:translog官方文档介绍
3.1.2:段合并
1:问题:
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。
而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。
更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
2:解决
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,
然后这些大的段再被合并到更大的段
3:段的合并:
合并大的段需要消耗大量的I/O和CPU资源,如果任其发展会影响搜索性能。Elasticsearch在默认情况下会对合并流程进行资源限制,所以搜索仍然 有足够的资源很好地执行。
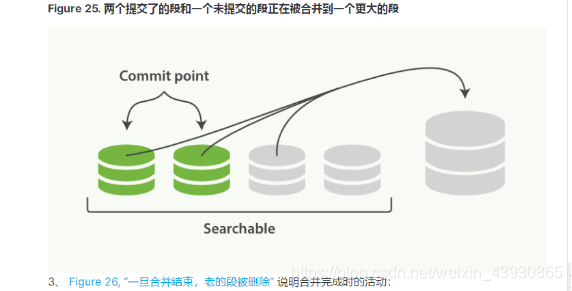
4:段合并的优化以及配置
3.2:分析与分析器
分析 包含下面的过程:
首先,将一块文本分成适合于倒排索引的独立的 词条 ,
之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
分析器执行上面的工作。 分析器 实际上是将三个功能封装到了一个包里:
1:
字符过滤器
首先,字符串按顺序通过每个 字符过滤器 。他们的任务是在分词前整理字符串。一个字符过滤器可以用来去掉HTML,或者将 & 转化成 and。
:2:
分词器
其次,字符串被 分词器 分为单个的词条。一个简单的分词器遇到空格和标点的时候,可能会将文本拆分成词条。
3:
Token 过滤器
最后,词条按顺序通过每个 token 过滤器 。这个过程可能会改变词条(例如,小写化 Quick ),删除词条(例如, 像 a, and, the 等无用词),或者增加词条(例如,像 jump 和 leap 这种同义词)。
Elasticsearch提供了开箱即用的字符过滤器、分词器和token 过滤器。 这些可以组合起来形成自定义的分析器以用于不同的目的
