实验指导书 下载密码:fja4
本篇博客主要讲解,吴恩达机器学习第三周的编程作业,作业内容主要是利用逻辑回归算法(正则化)进行二分类。实验的原始版本是用Matlab实现的,本篇博客主要用Python来实现。
目录
1.实验包含的文件

| 文件名称 | 含义 |
| ex2.py | 逻辑回归算法(不带正则化)主程序 |
| ex2_reg.py | 逻辑回归算法(带正则化)主程序 |
| ex2data1.txt | 第一个实验的训练数据集 |
| ex2data2txt | 第二个实验的训练数据集 |
| mapFeature.py | 在原始输入特征基础上生成新的多项式特征的程序 |
| plotDecisionBoundary.py | 绘制决策边界的程序 |
| plotData.py | 可视化待分类数据的程序 |
| sigmoid.py | Sigmoid函数 |
| costFunction.py | 计算逻辑回归(不带正则化)代价函数的程序 |
| predict.py | 逻辑回归测试函数 |
| costFunctionReg.py | 计算逻辑回归(带正则化)代价函数的程序 |
实验任务:编写红色部分程序的关键代码。
2.使用逻辑回归算法(不带正则化)进行二分类
- 打开主程序ex2.py
data = np.loadtxt('ex2data1.txt', delimiter=',') #读取txt文件 每一行以','分隔
X = data[:, 0:2] #前两列为原始输入特征 分别两门考试的成绩
y = data[:, 2] #第三列是输出变量(标签) 二分类 0/1 1代表通过 0代表未通过
'''第1部分 可视化训练数据集'''
print('Plotting Data with + indicating (y = 1) examples and o indicating (y = 0) examples.')
plot_data(X, y)
plt.axis([30, 100, 30, 100]) #设置x,y轴的取值范围
plt.legend(['Admitted', 'Not admitted'], loc=1) #设置图例
plt.xlabel('Exam 1 score') #x轴标题 考试1成绩
plt.ylabel('Exam 2 score') #y轴标题 考试2成绩- 编写可视化程序plotData.py
def plot_data(X, y):
plt.figure()
postive=X[y==1] #分离正样本
negtive=X[y==0] #分离负样本
plt.scatter(postive[:,0],postive[:,1],marker='+',c='red',label='Admitted') #画出正样本
plt.scatter(negtive[:,0],negtive[:,1],marker='o',c='blue',label='Not Admitted') #画出负样本- 查看可视化效果

- 计算逻辑回归的代价函数和梯度
'''第2部分 计算代价函数和梯度'''
(m, n) = X.shape #m样本数 n原始输入特征数
X = np.c_[np.ones(m), X] #特征矩阵X前加一列1 方便矩阵运算
#初始化模型参数为0
initial_theta = np.zeros(n + 1)
# 计算逻辑回归的代价函数和梯度
cost, grad = cf.cost_function(initial_theta, X, y)
np.set_printoptions(formatter={'float': '{: 0.4f}\n'.format}) #设置输出格式
#与期望值进行比较 验证程序的正确性
print('Cost at initial theta (zeros): {:0.3f}'.format(cost)) #0参数下的代价函数值
print('Expected cost (approx): 0.693')
print('Gradient at initial theta (zeros): \n{}'.format(grad)) #0参数下的梯度值
print('Expected gradients (approx): \n-0.1000\n-12.0092\n-11.2628')
# 用非零参数值计算代价函数和梯度
test_theta = np.array([-24, 0.2, 0.2])
cost, grad = cf.cost_function(test_theta, X, y)
#与期望值进行比较 验证程序的正确性
print('Cost at test theta (zeros): {}'.format(cost))#非0参数下的代价函数值
print('Expected cost (approx): 0.218')
print('Gradient at test theta: \n{}'.format(grad))
print('Expected gradients (approx): \n0.043\n2.566\n2.647')#非0参数下的代价函数值- 编写sigmoid函数sigmoid.py

def sigmoid(z):
g = np.zeros(z.size)
g=1/(1+np.exp(-z))
return g
- 编写计算代价函数和梯度的程序costFunction.py



def h(theta,X): #假设函数
return sigmoid(np.dot(X,theta))
def cost_function(theta, X, y):
m = y.size #样本数
cost = 0
grad = np.zeros(theta.shape)
myh=h(theta,X) #得到假设函数值
term1=-y.dot(np.log(myh))
term2=(1-y).dot(np.log(1-myh))
cost=(term1-term2)/m
grad=(myh-y).dot(X)/m
return cost, grad
证明我们的代码是正确的。
- 训练分类器,并用高级优化方法fmin_bfgs求解最优参数
'''第3部分 用高级优化方法fmin_bfgs求解最优参数'''
#可以把高级优化想像成梯度下降法 只不过不用人工设置学习率
'''
fmin_bfgs优化函数 第一个参数是计算代价的函数 第二个参数是计算梯度的函数 参数x0传入初始化的theta值
maxiter设置最大迭代优化次数
'''
def cost_func(t): #单独写一个计算代价的函数 返回代价函数值
return cf.cost_function(t, X, y)[0]
def grad_func(t): #单独写一个计算梯度的函数 返回梯度值
return cf.cost_function(t, X, y)[1]
# 运行高级优化方法
theta, cost, *unused = opt.fmin_bfgs(f=cost_func, fprime=grad_func, x0=initial_theta, maxiter=400, full_output=True, disp=False)
#打印最优的代价函数值和参数值 与期望值比较 验证正确性
print('Cost at theta found by fmin: {:0.4f}'.format(cost))
print('Expected cost (approx): 0.203')
print('theta: \n{}'.format(theta))
print('Expected Theta (approx): \n-25.161\n0.206\n0.201')
# 画出决策边界
pdb.plot_decision_boundary(theta, X, y)
plt.xlabel('Exam 1 score')
plt.ylabel('Exam 2 score')可以发现我们的结果和期望值差不多:

调用已经写好的plotDecisionBoundary.py画出决策边界:

- 用训练好的分类器进行预测,并计算在训练集上的准确率
'''第4部分 用训练好的分类器进行预测,并计算分类器在训练集上的准确率'''
#假设一个学生 考试1成绩45 考试2成绩85 预测他通过的概率
prob = sigmoid(np.array([1, 45, 85]).dot(theta))
#与期望值进行比较 验证正确性
print('For a student with scores 45 and 85, we predict an admission probability of {:0.4f}'.format(prob))
print('Expected value : 0.775 +/- 0.002')
# 计算分类器在训练集上的准确率
p = predict.predict(theta, X)
#与期望值进行比较 验证正确性
print('Train accuracy: {}'.format(np.mean(y == p) * 100))
print('Expected accuracy (approx): 89.0')
- 编写预测程序predict.py
def predict(theta, X):
m = X.shape[0] #样本数
p = np.zeros(m) #每个样本预测的标签
p=sigmoid(X.dot(theta)) #每个样本属于正类的概率
p[p>=0.5]=1 #概率大于等于0.5 认为属于正类 标签为1 否则为0
p[p<0.5]=0
return p发现我们的结果和期望值差不多:

3.逻辑回归算法(不带正则化)进行二分类完整项目代码
下载链接 下载密码:546j
4.利用逻辑回归算法(带正则化)进行二分类
使用逻辑回归进行分类时,一种方案是直接使用原始输入特征进行运算;另一种是当输入特征比较少或分类效果不理想时时,可以考虑在原始输入特征的基础上扩充一些新特征,再进行逻辑回归。本小节的实验就属于第二种情况,该数据集可视化后会发现线性不可分,所以仅用两个原始输入特征是不可行的,需要扩展一些新特征。
扩充的新特征多一些没关系,训练过程中会自动筛选对分类效果贡献大的特征,体现在求解的最优参数上,一般不重要的特征,前面的参数都接近于0.
- 打开主程序ex2_reg.py
data = np.loadtxt('ex2data2.txt', delimiter=',') #加载txt格式训练数据集 每一行用','分隔
X = data[:, 0:2] #前两列是原始输入特征(2)
y = data[:, 2] #最后一列是标签 0/1
plot_data(X, y) #可视化训练集
plt.xlabel('Microchip Test 1')
plt.ylabel('Microchip Test 2')
plt.legend(['y = 1', 'y = 0'])#图例
input('Program paused. Press ENTER to continue')
'''第1部分 增加新的多项式特征,计算逻辑回归(正则化)代价函数和梯度'''
X = mf.map_feature(X[:, 0], X[:, 1])
initial_theta = np.zeros(X.shape[1])
lmd = 1 #正则化惩罚项系数
# 计算参数为0时的代价函数值和梯度
cost, grad = cfr.cost_function_reg(initial_theta, X, y, lmd)
#与期望值比较 验证正确性
np.set_printoptions(formatter={'float': '{: 0.4f}\n'.format})
print('Cost at initial theta (zeros): {}'.format(cost))
print('Expected cost (approx): 0.693')
print('Gradient at initial theta (zeros) - first five values only: \n{}'.format(grad[0:5]))
print('Expected gradients (approx) - first five values only: \n 0.0085\n 0.0188\n 0.0001\n 0.0503\n 0.0115')
input('Program paused. Press ENTER to continue')
test_theta = np.ones(X.shape[1])
# 计算参数非0(1)时的代价函数值和梯度
cost, grad = cfr.cost_function_reg(test_theta, X, y, lmd)
#与期望值比较 验证正确性
print('Cost at test theta: {}'.format(cost))
print('Expected cost (approx): 2.13')
print('Gradient at test theta - first five values only: \n{}'.format(grad[0:5]))
print('Expected gradients (approx) - first five values only: \n 0.3460\n 0.0851\n 0.1185\n 0.1506\n 0.0159')- 编写可视化程序plotData.py
def plot_data(X, y):
plt.figure()
postive=X[y==1] #取出正样本
negtive=X[y==0] #取出负样本
plt.scatter(postive[:,0],postive[:,1],marker='x',c='red',label='y=1')
plt.scatter(negtive[:,0],negtive[:,1],marker='o',c='blue',label='y=0')
- 查看已经写好的特征映射程序mapFeature.py
在原始输入特征(两个)基础上增加新的多项式特征:

def map_feature(x1, x2): #生成新的多项式特征
degree = 6
x1 = x1.reshape((x1.size, 1))
x2 = x2.reshape((x2.size, 1))
result = np.ones(x1[:, 0].shape) #result初始为一个列向量 值全为1
for i in range(1, degree + 1):
for j in range(0, i + 1):
result = np.c_[result, (x1**(i-j)) * (x2**j)] #不断拼接新的列 扩充特征矩阵
return result- 编写逻辑回归(正则化)的代价函数和梯度计算程序costFunctionReg.py
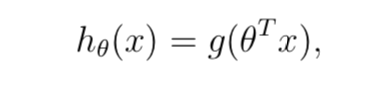

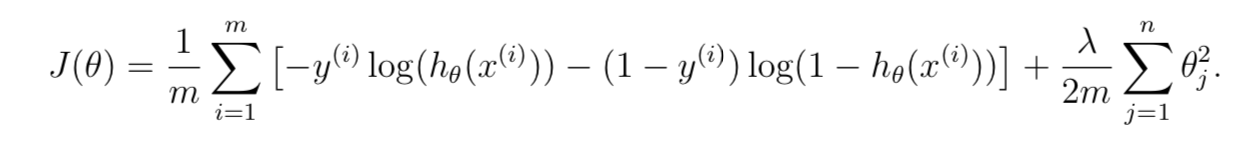
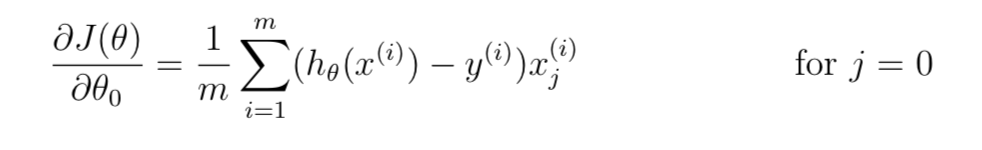

注意不惩罚第一个参数。
def h(theta,X): #假设函数
return sigmoid(X.dot(theta))
def cost_function_reg(theta, X, y, lmd):
m = y.size
cost = 0
grad = np.zeros(theta.shape)
myh=h(theta,X) #假设函数值
term1=-y.dot(np.log(myh))
term2=(1-y).dot(np.log(1-myh))
term3=(lmd/(2*m))*(theta[1:].dot(theta[1:])) #不惩罚第一项
cost=(term1-term2)/m+term3
grad=(myh-y).dot(X)/m
grad[1:]+=(lmd/m)*theta[1:]
return cost, grad
与期望值进行比较,差不多,说明我们的程序是正确的:

- 数据集可视化效果

- 训练与预测
'''第2部分 尝试不同的惩罚系数[0,1,10,100],分别利用高级优化算法求解最优参数,分别计算训练好的分类器在训练集上的准确率,
并画出决策边界
'''
initial_theta = np.zeros(X.shape[1])
# Set regularization parameter lambda to 1 (you should vary this)
lmd = 1 #需要改变这个值
# Optimize
def cost_func(t):
return cfr.cost_function_reg(t, X, y, lmd)[0]
def grad_func(t):
return cfr.cost_function_reg(t, X, y, lmd)[1]
theta, cost, *unused = opt.fmin_bfgs(f=cost_func, fprime=grad_func, x0=initial_theta, maxiter=400, full_output=True, disp=False)
print('Plotting decision boundary ...')
pdb.plot_decision_boundary(theta, X, y)
plt.title('lambda = {}'.format(lmd))
plt.xlabel('Microchip Test 1')
plt.ylabel('Microchip Test 2')
p = predict.predict(theta, X)
print('Train Accuracy: {:0.4f}'.format(np.mean(y == p) * 100))
print('Expected accuracy (with lambda = 1): 83.1 (approx)')- 编写预测函数
def predict(theta, X):
m = X.shape[0]
p = np.zeros(m)
p=sigmoid(X.dot(theta))
p[p>=0.5]=1
p[p<0.5]=0
return p- 尝试不同的惩罚系数值
时:
可视化决策边界,查看分类效果:

与期望值进行比较,差不多,说明我们的程序是正确的:

时:
相当于不进行正则化。
可视化决策边界,查看分类效果:


虽然此时分类效果看起来更好,在训练集上的准确率更高,但是很有可能出现过拟合,模型泛化能力比较差。
时:
可视化决策边界,查看分类效果:

![]()
此时,正则化惩罚系数有些大,分类效果不太好以及在训练集上的准确率不太高,应该稍微减小一下。
时:
可视化决策边界,查看分类效果:

![]()
此时,正则化惩罚系数有些过大,分类效果很不好以及在训练集上的准确率很低,应该大幅度减小一下。
综上,在训练过程中,需要添加正则化惩罚项防止过拟合,但惩罚系数要合理设置,过大过小都不行。
5.逻辑回归算法(正则化)进行二分类完整项目代码
下载链接 下载密码:73we