简易爬虫
爬出该网页的 2018新片精品的"电影名称""和"下载链接"
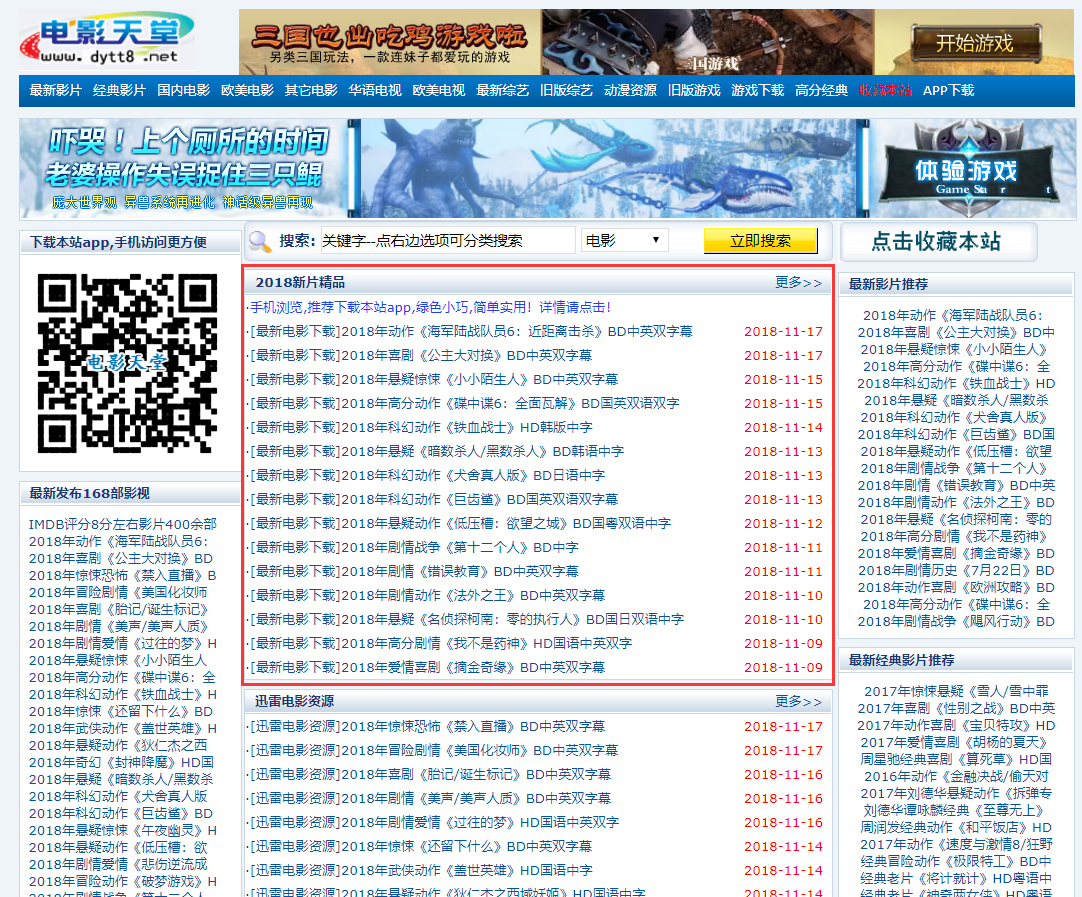
如下:
import re
import ssl
import json
from urllib.request import urlopen
ssl._create_default_https_context = ssl._create_unverified_context #干掉数字签名证书
# 获取首页的新片精品电影的url
url = "https://www.dytt8.net/" #电影天堂首页url
content = urlopen(url).read().decode("gbk")
pa = re.compile(r'<td width="85%" height="22" class="inddline">.*?最新电影下载</a>]<a href=\'(?P<wangye>.*?)\'>2018年',re.S)
xiazai = pa.finditer(content)
lst =[] #创建列表,装电影url
for el in xiazai:
shijiurl ="https://www.dytt8.net"+ el.group("wangye")
lst.append(shijiurl)
#获取电影名称
lst_name =[] #创建列表,装电影名字
pa3 = re.compile(r'<td width="85%" height="22" class="inddline">.*?最新电影下载</a>]<a href=\'.*?《(?P<movie>.*?)》',re.S)
name = pa3.finditer(content)
for el in name:
moviename = el.group("movie")
lst_name.append(moviename)
#获取电影下载地址
lst_url =[] #创建列表,装电影的下载url
for i in lst:
url2 = i
content2 = urlopen(url2).read().decode("gbk")
pa2 = re.compile(r'<td style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<xiazaiurl>.*?)">',re.S)
xiazai2 = pa2.search(content2)
lst_url.append(xiazai2.group('xiazaiurl'))
#存储为json字符串并写入movie.json文件中保存.
dic = {"电影":[],"下载地址":[]} #创建字典,装电影名和下载链接
f = open("movie.json", mode="w", encoding="utf-8")
for i in range(len(lst_name)):
dic["电影"] = lst_name[i]
dic["下载地址"] = lst_url[i]
j = json.dumps(dic, ensure_ascii=False)
f.write(j+"\n")
f.close()
最后效果图:
