Hive概述、内部表、外部表、分区表的操作
一、Hive概述
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取、转化、加载(ETL Extract-Transform-Load ),这是一种可以存储、查询和分析存储在Hadoop 中的大规模数据的机制。
二、Hive的Hql
HQL - Hive通过类SQL的语法,来进行分布式的计算。HQL用起来和SQL非常的类似,Hive在执行的过程中会将HQL转换为MapReduce去执行,所以Hive其实是基于Hadoop的一种分布式计算框架,底层仍然是MapReduce,所以它本质上还是一种离线大数据分析工具。
三、数据库和数据仓库的区别
1.数据库是面向事务处理的,而数据仓库是面向数据分析处理的(面向主题设计的)。数据仓库存储的数据是有主题的,比如分析客户的数据,盈利数据等,即都是和决策分析有关的数据。
2.数据库存储的在线数据,而数据仓库存储的是离线数据(历史数据)
3.数据仓库的数据来源是异构的,有来自与数据库的数据,日志数据,网络数据,空间数据,事务数据等。
4.数据仓库是弱事务或没有事务概念。因为数据仓库一般都基于历史数据去分析,而不涉及到更改数据,所以不需要事务。
5.数据仓库的数据是时变的,即仓库里的数据一般都显示或隐式的包含时间元素。
四、OLTP系统和OLAP系统
OLTP:在线联机事务处理系统=》Mysql,oracle等关系型数库
OLAP:在线联机分析处理系统=》Hive
OLTP系统面向的用户和数据库操作人员。
OLAP系统面向的是知识工人(数据分析人员和决策人员)
OLAP系统里有个概念:数据立方体(Data cube)
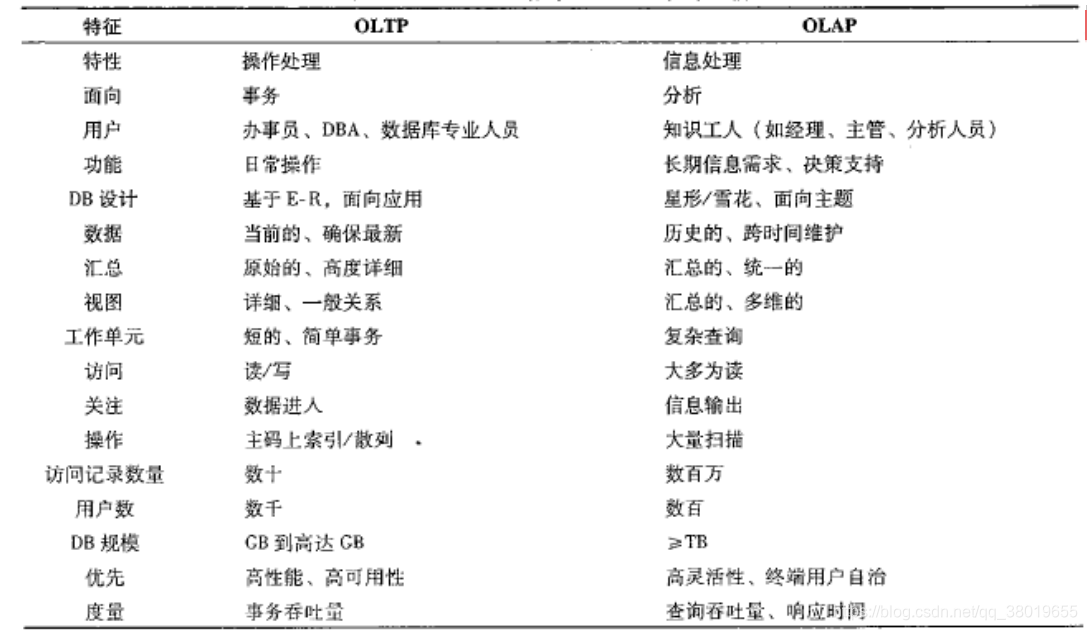
OLAP与OLTP对比:
五、适用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
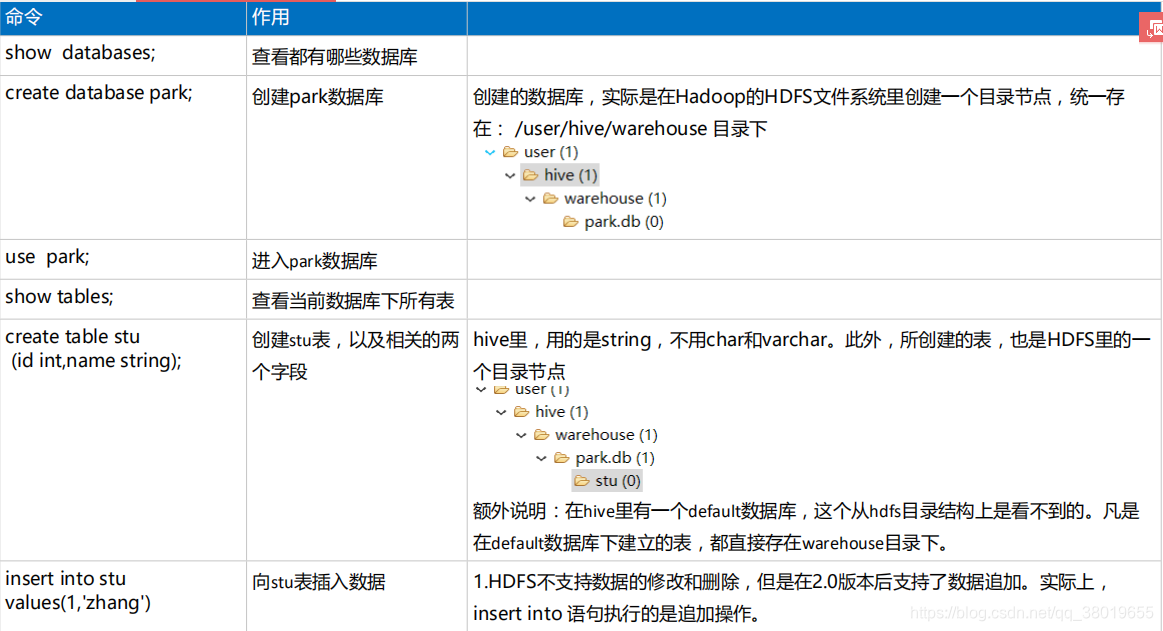
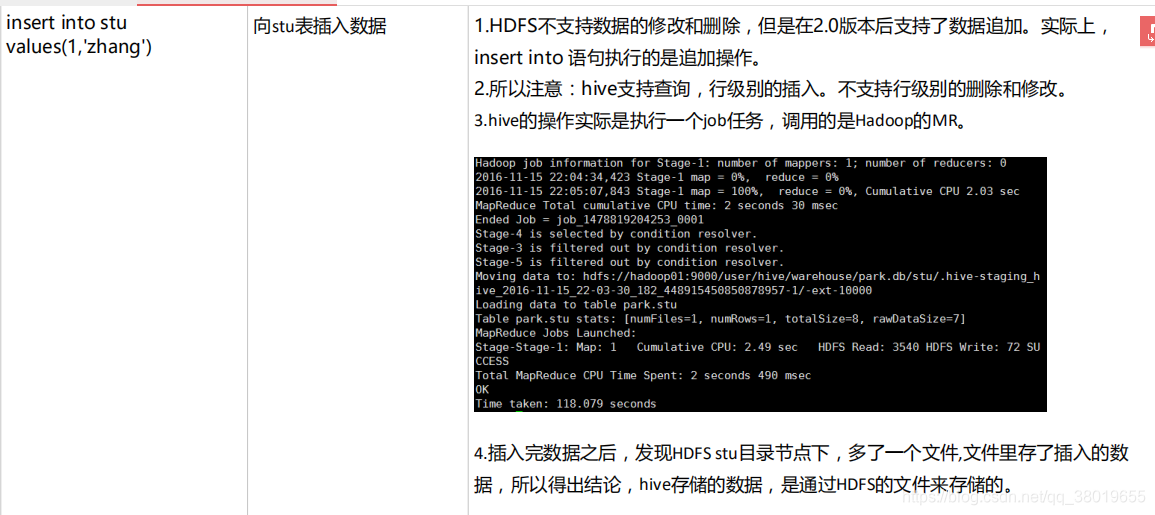
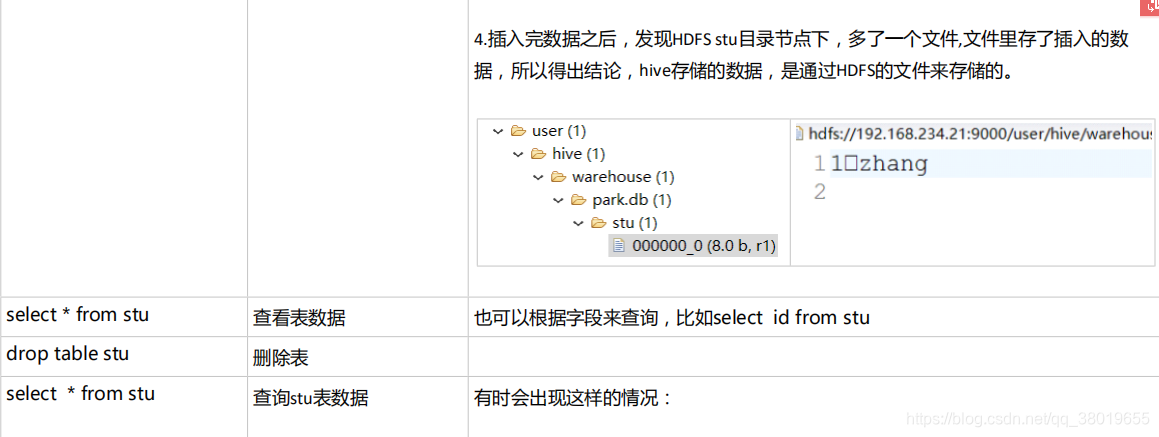
六、Hive基础指令
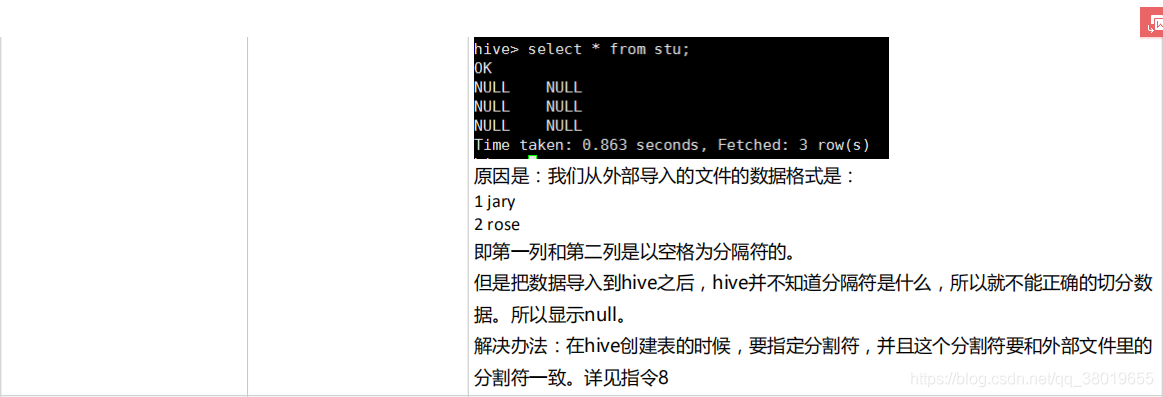
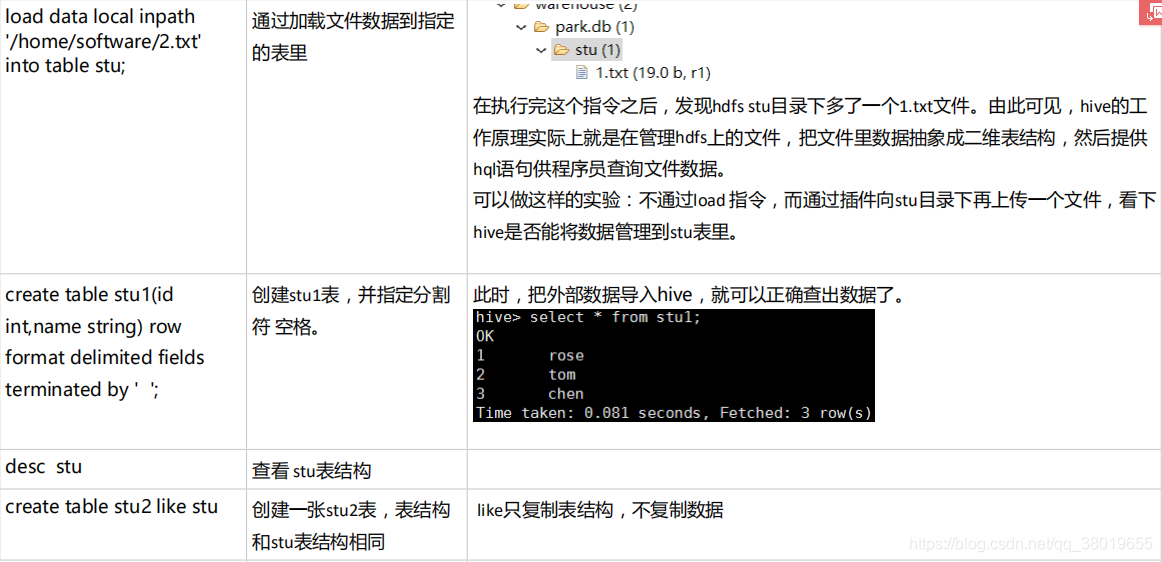


六、创建外部表
创建外部表的命令:create external table stu (id int,name string) row format delimited fields terminated by ’ ’ location ‘/data’
hive无论是内部表或外部表,当向HDFS对应的目录节点下追加文件时(只要格式符合),hive都可以把数据管理进来。
七、内部表和外部表的区别
通过hive执行:drop table stu 。这是删除表操作。如果stu是一个内部表,则HDFS对应的目录节点会被删除。
如果stu是一个外部表,HDFS对应的目录节点不会删除。
八、Hive分区表
hive也支持分区表,对数据进行分区可以提高查询时的效率。
普通表和分区表区别:有大量数据增加的需要建分区表
执行:create table book (id int, name string) partitioned by (category string )row format delimited fields terminated by ’ ';
注:在创建分区表时,partitioned字段可以不在字段列表中。生成的表中自动就会具有该字段。
category 是自定义的字段。
分区表加载数据
load data local inpath ‘./book_china.txt’ overwrite into table book partition (category=‘cn’);
load data local inpath ‘./book_english.txt’ overwrite into table book partition (category=‘en’);
经检查发现分区也是一个目录。
select * from book; 查询book目录下的所有数据
select * from book where category=‘cn’; 只查询 cn分区的数据
如果想先在HDFS的目录下,自己创建一个分区目录,然后在此目录下上传文件,此时手动创建目录是无法被hive使用的,因为元数据库中没有记录该分区。
如果需要将自己创建的分区也能被识别,需要执行:ALTER TABLE book add PARTITION (category = ‘jp’) location ‘/user/hive/warehouse/park.db/book/category=jp’;
这行命令的作用是在元数据Dock表里创建对应的元数据信息
九、分区命令
显示分区 show partitions book;
添加分区 alter table book add partition (category=‘jp’)location
‘/user/hive/warehouse/park.db/book/category=jp’; 或者:
msck repair table book;
删除分区 alter table book drop partition(category=‘cn’)
修改分区 alter table book partition(category=‘french’) rename to partition (category=‘hh’);