FIlebeat 配置文件内容详解:
vi filebeat.yml
filebeat.prospectors:
#日志类型
- type: log
enabled: True
# 日志路径可以写多个,支持通配符
paths:
- /tmp/test.log
#设置字符集编码
encoding: utf-8
#文档类型
document_type: my-nginx-log
#每十秒扫描一次
scan_frequency: 10s
# 实际读取文件时,每次读取 16384 字节
harverster_buffer_size: 16384
#The maximum number of bytes that a single log message can have. All bytes after max_bytes are discarded and not sent. This setting is especially useful for multiline log messages, which can get large. The default is 10MB (10485760). 一次发生的log大小值;
max_bytes: 10485760
# 是否从文件末尾开始读取
tail_files: true
#给日志加上tags方便在logstash过滤日志的时候做判断
tags: ["nginx-access"]
#剔除以.gz 结尾的文件
exclude_files: [".gz$"]
#output 部分的配置文档
#配置输出为kafka,无论你是tar包还是rpm安装,目录里边会看到官方提供的filebeat.full.yml OR filebeat.reference.yml 这里边有filebeat 所有的input 方法和output 方法供你参考;
output.kafka:
enabled: true
#kafka 的server,可以配置集群,例子如下:
hosts:["ip:9092","ip2:9092","ip3:9092"]
#这个非常重要,filebeat作为provider,把数据输入到kafka里边,logstash 作为消费者去消费这些信息,logstash的input 中需要这个topic,不然logstash没有办法取到数据。
topic: elk-%{[type]}
# The number of concurrent load-balanced Kafka output workers. kafka 的并发运行进程
worker: 2
#当传输给kafka 有问题的时候,重试的次数;
max_retries: 3
#单个kafka请求里面的最大事件数,默认2048
bulk_max_size: 2048
#等待kafka broker响应的时间,默认30s
timeout: 30s
#kafka broker等待请求的最大时长,默认10s
broker_timeout: 10s
#每个kafka broker在输出管道中的消息缓存数,默认256
channel_buffer_size: 256
#网络连接的保活时间,默认为0,不开启保活机制
keep_alive: 60
#输出压缩码,可选项有none, snappy, lz4 and gzip,默认为gzip (kafka支持的压缩,数据会先被压缩,然后被生产者发送,并且在服务端也是保持压缩状态,只有在最终的消费者端才会被解压缩)
compression: gzip
#允许的最大json消息大小,默认为1000000,超出的会被丢弃,应该小于broker的 message.max.bytes(broker能接收消息的最大字节数)
max_message_bytes: 1000000
#kafka的响应返回值,0位无等待响应返回,继续发送下一条消息;1表示等待本地提交(leader broker已经成功写入,但follower未写入),-1表示等待所有副本的提交,默认为1
required_acks: 0
#The configurable ClientID used for logging, debugging, and auditing purposes. The default is "beats"。客户端ID 用于日志怕错,审计等,默认是beats。
client_id: beats
#测试配置文件:/opt/elk/filebeat/filebeat -c /opt/elk/filebeat/filebeat.yml test config
#如果配置文件没有问题的话,会出现config ok ,如果有问题会提示具体问题在哪里。
#启动filebeat
可以先通过 /opt/elk/filebeat-6.2.2-linux-x86_64/filebeat -c -e /opt/elk/filebeat-6.2.2-linux-x86_64/filebeat.yml 查看一下输入filebeat是否工作正常,会有很多信息打印到屏幕上;
nohup /opt/elk/filebeat-6.2.2-linux-x86_64/filebeat -c /opt/elk/filebeat-6.2.2-linux-x86_64/filebeat.yml >>/dev/null 2>&1& logstash 配置详解:
input {
#数据来源
kafka {
#这个对应filebeat的output 的index
topics_pattern => "elk-.*"
#kafka 的配置
bootstrap_servers => "IP1:9092,IP2:9092,IP3:9092"
kafka 中的group ID
group_id => "logstash-g1"
}
}
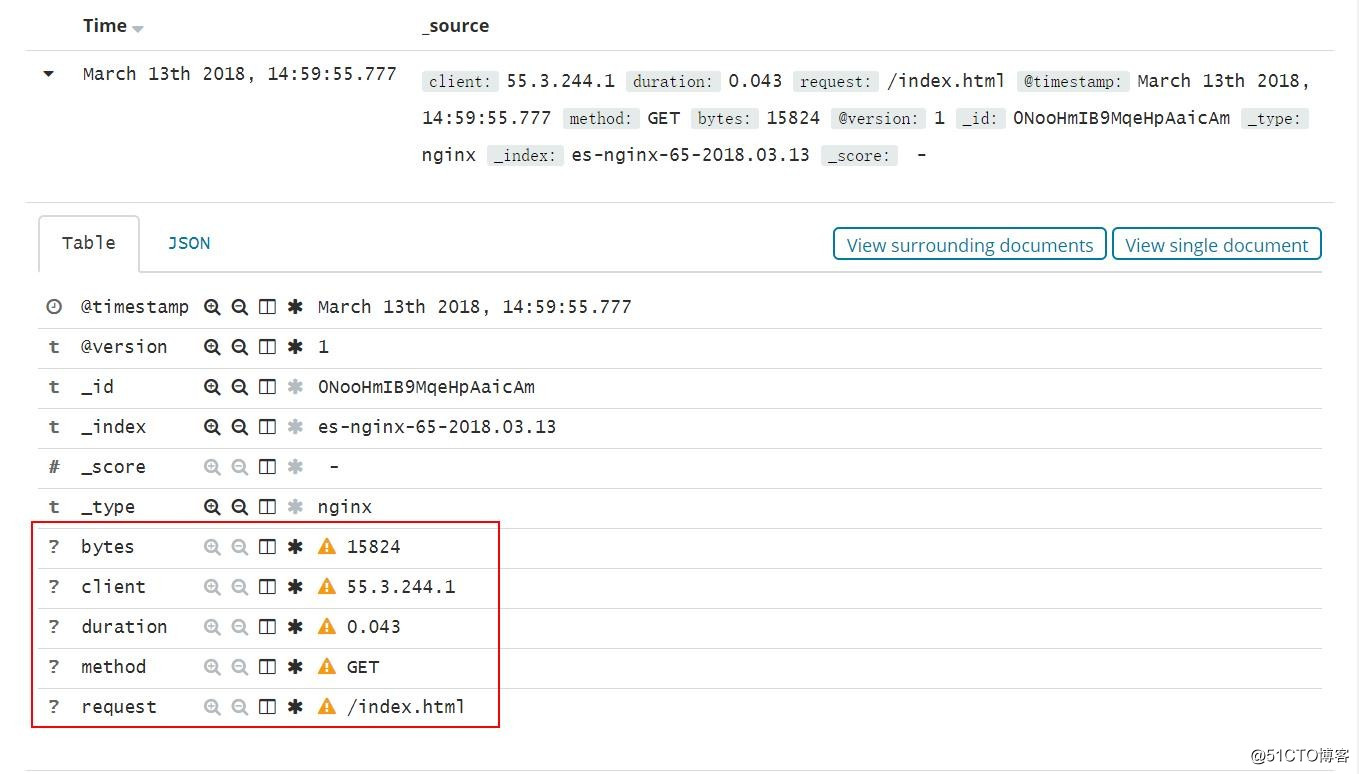
#过滤器,如果你想要日志按照你的需求输出的话,需要在logstash中过滤并且给与相应的key,比如以下的是nginx 日志,用的是logstash内置好的过滤器,%{IP:client} 这个里边包含了两个信息:ip地址,client 是在kibana 中显示的自定义键值,最终显示成这样,http://grokdebug.herokuapp.com/ 是在线调试logstash filter的工具,你可以在线调试你的过滤规则。
filter {
grok {
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}"}
#因为我们取出了字段,所以不需要原来这个message字段,这个字段里边包含之前beat 输入的所有字段。
remove_field => ["message"]
}
}
output {
elasticsearch {
hosts => ["IP:9200"]
#这个是在kibana上的index Patterns 的索引,建议什么服务就用干什么名字,因为beat 提供了些kibana的模板可以导入,导入的模板匹配的时候用的索引是对应服务的名称开头 。
index => "nginx-%{+YYYY.MM.dd}"
document_type => "nginx"
#每次20000 发送一次数据到elasticsearch
flush_size => 20000
如果不够20000,没10秒会发送一次数据;、
idle_flush_time =>10
}
}日志从filebeat 收集到Logstash输出的流程图:

Kibana 上边的日志通过logstash 过滤之后取出来在kibana上显示如下: