MapReduce 的思想源于 PageRank(网页排名) 问题。
PageRank(网页排名)
现在有四个网页,它们之间的存在如下引用关系:
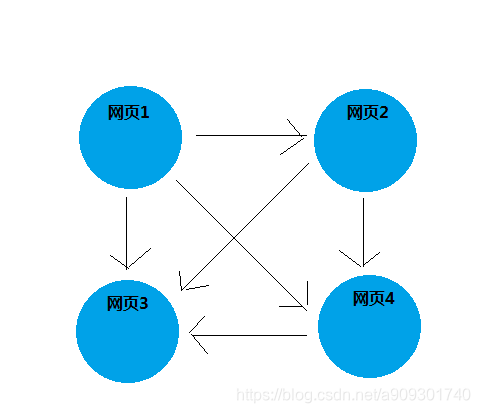
网页 1 有 3 个引用,分别指向网页 2,网页 3,网页 4。
网页 2 有 2 个引用,分别指向网页 3,网页 4。
网页 4 有 1 个引用,分别指向网页 3。
网页 3 没有引用。
Google 采用向量矩阵的方式来表示上面网页之间的引用关系:
| 网页1 | 网页2 | 网页3 | 网页4 | |
|---|---|---|---|---|
| 网页1 | 0 | 1 | 1 | 1 |
| 网页2 | 0 | 0 | 1 | 1 |
| 网页3 | 0 | 0 | 0 | 0 |
| 网页4 | 0 | 0 | 1 | 0 |
网页 1 与网页 2,3,4 都有引用关系,所以把对应的那一行上对应位置记为 1,没有引用关系的网页记为 0,以此类推。
最终我们可以得到一个 4 * 4 的矩阵,我们都知道矩阵在数学上是可以计算的,最终计算出网页 3 的权重最大,所以我们就把网页 3 排在页面的最前面。
但是,实际操作上会出现一些的问题:
实际上的网页的数量很大,以 1 亿为例,就会产生一个 1 亿 * 1 亿的矩阵,虽然从数学的角度来说是可以计算的,但是实际情况是到目前为止任何一台计算机都没有办法在短时间内独立计算出结果。
所以,Google 提出了一个 MapReduce 计算模型。
MapReduce
MapReduce 基本思想:先拆分,再合并。
拿上面的例子来说,就是把一个大矩阵拆分成多个小矩阵,每台机器负责计算其中的一个小矩阵的结果,计算完毕后再把结果合并。
再看一个累加求和的例子:
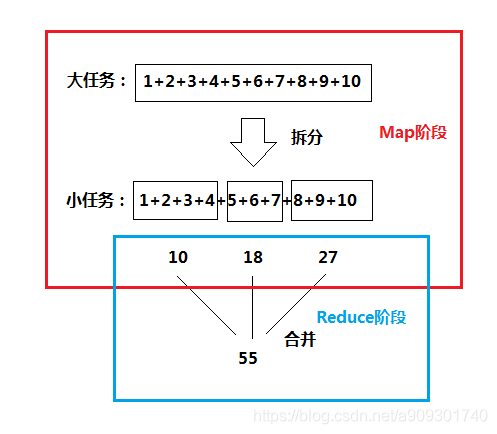
MapReduce 其实分为两个阶段:红色部分为 Map 阶段,蓝色部分为 Reduce 阶段。
MapReduce 编程模型
-
一个 MapReduce 任务 = map + reduce
也就是说一个完整的 MapReduce 程序由三个 Java 类组成。
-
Map 的输出是 Reduce 的输入。
10,18,27 是 Map 的输出,同时是 Reduce 的输入。
-
所有的输入输出都是 <key, value> 形式的。
-
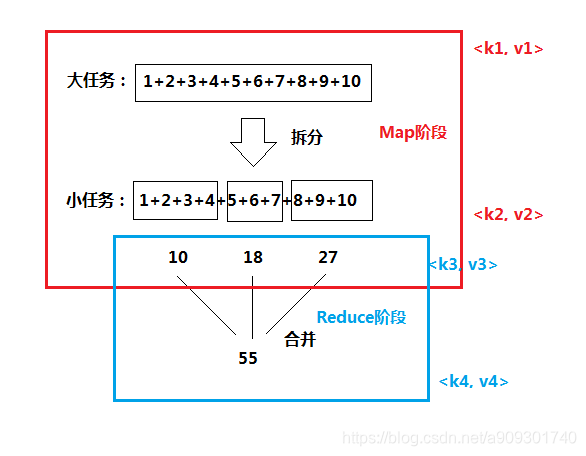
在整个 MapReduce 过程有 4 个 <key, value> 对。
<k1, v1> Map 的输入,<k2, v2> Map 的输出
<k3, v3> Reduce 的输入,<k4, v4> Reduce 的输出
-
k2 = k3,v3 是一个集合,该集合中的每个元素就是 v2。
-
所有的输入输出的数据类型必须是 Hadoop 自己的数据类型,不能是 Java 的数据类型。
ava 数据类型 Hadoop 数据类型 Integer IntWritable Long LongWritable String Text null NullWritable 原因:Hadoop 所有的数据类型都实现了 Hadoop 的序列化。
Java 类只要实现了 Serializable 接口,就实现了 Java 序列化,对应的对象就可以在 InputStream 和 OutputStream 上进行传输。
Java 类只要实现了 Writable 接口,就实现了 Hadoop 序列化,对应的对象就可以作为 Map 和 Reduce 程序的输入和输出。
-
MapReduce 处理的都是 HDFS 上的数据(或 HBase)。