MapReduce工作流程
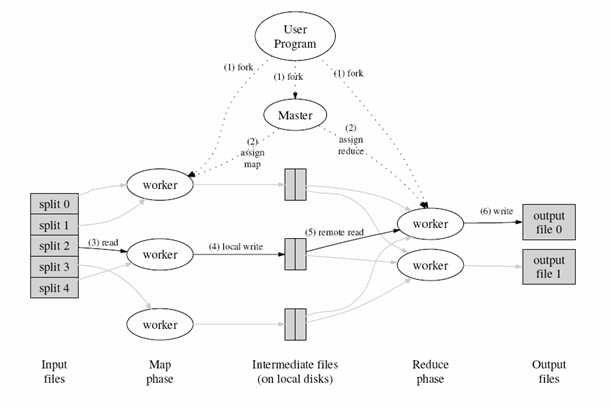
1.将输入源(Inputfiles)切割成不同的片段,每个片段的大小通常在16M-64M之间(可通过参数配置),然后启动云端程序。
2.MapReduce程序基于master/slaves方式部署,在云端机器中选中一台机器运行master程序,职责包括:调度任务分配给slaves,监听任务的执行情况。
3.在图形中,slave的体现形式为worker,当worker接到Map任务时,会读取输入源片段,从中解析出Key/Value键值对,并作为参数传递到用户自定义的Map功能函数之中,Map功能函数的输出值同样为Key/Value键值对,这些键值对会临时缓存在内存里面。
4.缓存之后,程序会定期将缓存的键值对写入本地硬盘(执行如图所示的local write操作),并且把存储地址传回给master,以便master记录它们的位置用以执行Reduce操作。
5.当worker被通知执行Reduce操作时,master会把相应的Map输出数据所存储的地址也发送给该worker,以便其通过远程调用来获取这些数据。得到这些数据之后,reduce worker会把具有相同Key值的记录组织到一起来达到排序的效果。
6.Reduce Worker会把排序后的数据作为参数传递到用户自定义的Reduce功能函数之中,而函数的输出结果会持久化存储到output file中去。
7.当所有的Map任务和Reduce任务结束之后,Master会重新唤醒用户主程序,至此,一次MapReduce操作调用完成。
2.2、HDFS组件结构
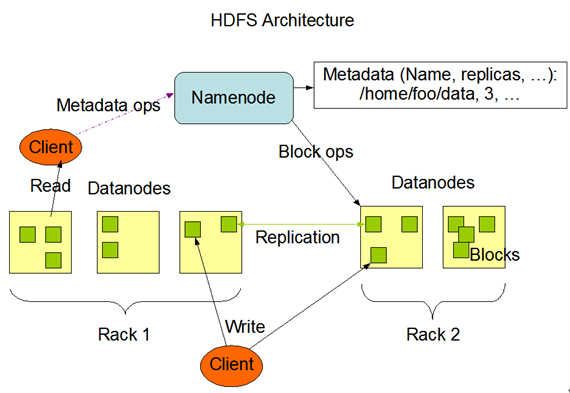
同MapReduce部署结构类似,HDFS同样具备master/slaves主仆结构
1.如图所示中,NameNode充当master角色,职责包括:管理文档系统的命名空间(namespace);调节客户端访问到需要的文件(存储在DateNode中的文件)
注:namespace—映射文件系统的目录结构
2.DataNodes充当slaves角色,通常情况下,一台机器只部署一个Datenode,用来存储MapReduce程序需要的数据
Namenode会定期从DataNodes那里收到Heartbeat和Blockreport反馈
Heartbeat反馈用来确保DataNode没有出现功能异常;
Blockreport包含DataNode所存储的Block集合
2.3、hadoop资源
1 http://wiki.apache.org/nutch/NutchHadoopTutorial基于Nutch和Hadoop完成分布式采集和分布式查询
http://wiki.apache.org/nutch/MapReduce
使用MapReduce进行排序
http://www.cnblogs.com/koalaer/archive/2012/04/16/MapReduce_Combiner.htmlMapReduce 算法设计
http://blog.csdn.net/cuirong1986/article/details/8443841MapReduce Design Patterns(chapter 1)(一)