MapReduce 是什么?
MapReduce 是一个 软件框架,可以采用并行、分布式处理GB、TB,甚至PB级的大数据集,同时它也是一个在商用服务器集群之上完成大规模数据处理的执行框架。
MapReduce 是一种 编程范式,可以利用集群环境的成百上千台服务器实现强大的可伸缩性。
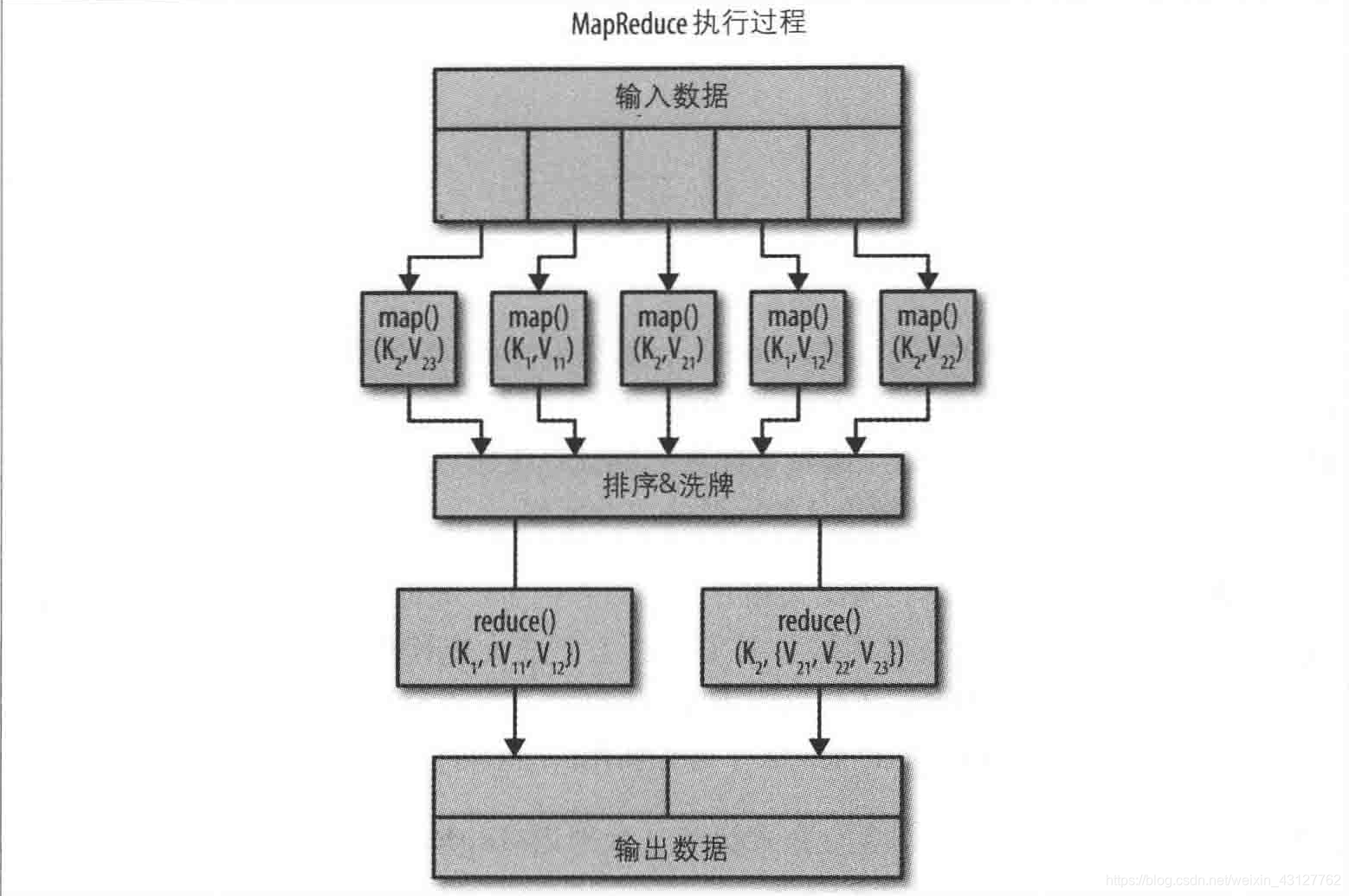
上图给出了MapReduce执行过程的视图。简单来说,MapReduce的目标就是实现可伸缩性。使用MapReduce范式时,重点是编写两个函数:
map()
过滤和聚集数据
reduce()
根据map()生成的键完成归约、分组和总结
定义如下:
map() 函数:
主节点得到输入,将输入划分为较小的数据块,再将这些小数据块分布到工作节点(从节点)。工作节点对各个数据块应用相同的转换函数,然后将结果传回主节点。在MapReduce中,程序员要定义一个映射器(mapper),如下:
map():(key1, Value) —— [ (key2, Value2) ]
reduce() 函数:
主节点根据唯一的键-值 对将接收到的结果进行洗牌和聚集,然后再一次重新分布到工作节点/从节点,通过另一类转换函数组合这些值。在MapReduce中,程序员要定义一个归约器(reducer),如下:
reduce():(key2, [Value2]) —— [(key3, Value3)]
映射器的输出:

归约器的输入:

一旦所有映射器的工作完成,归约器就会开始它们的执行过程。每个归约器创建的输出可以包含任意数目的新键-值对(可以是0个,也可以是多个)。
MapReduce 的核心概念是:将输入数据集映射到一个键-值对集合,然后对所有包含相同键的键-值对完成归约。尽管基本概念很简单,不过如果考虑一下方面,可以看到这个概念确实很强大、很有效:
几乎所有数据都可以映射到键-值对。
键和值可以是任意类型:String、Integer、FASTQ(用于DNA测序)、用户自定义的定制类型,当然,也可以是键-值对本身。
MapReduce的主要优点之一就是 它的 “不共享”(shared-nothing)数据处理平台。这意味着所有映射器可以独立的工作,而且映射器完成他们的任务时,归约器也能独立的开始工作(映射器或归约器之间不共享任何数据或临界区。如果有临界区,这会减慢分布式计算的速度)。基于这种“不共享“范式,我们可以很容易的编写map()函数和reduce()函数,而且能轻松、有效的提高并行性。
MapReduce 的简单解释
假设我们想要统计一个图书馆的藏书数量,这个图书馆拥有1000个书架,我们要把最后的结果报告给图书管理员。下面给出两种可能的MapReduce解决方案:
方案一:(使用map()和reduce())
——map():聘请1000个工人,每个工人统计一个书架的藏书数量
——reduce():所有工人集合在一起,把他们各自的统计结果汇总起来(向管理员报告他们的统计结果)
方案二:(使用map(),combine()和reduce())
——map():聘请1110个员工(1000名工人,100位经理,10位主管(每位主管负责管理10个经理,每个经理要管理10名工人)),每个工人负责统计一个书架,将结果报告给他的经理。
——combine():每个主管负责的10个经理将各自的统计结果汇总报告给这位主管。
——reduce():所有主管集合起来,把他们各自的统计结果汇总起来(向管理员 报告他们的统计结果)。
不适合使用MapReduce的情况:
一个值的计算依赖于之前计算的值。比如:斐波那契数列 就是一个很好的例子,其中每个值都是前两个值之和:
F( k + 2 ) = F( k + 1) + F( k )
数据集很小,完全可以在一台机器上计算。这种情况下,最好 作为一个reduce(map(data))操作来完成,而不需要经过整个MapReduce执行过程。
需要同步来处理共享数据。
所有输入数据都可以放在内存中。
一个操作依赖其他操作。
基本计算是处理器敏感型操作。
不过很多情况下MapReduce都很适用:
必须处理大量输入数据(如:对大量数据完成聚集或计算统计结果)。
需要利用并行分布式计算、数据存储和数据本地化。
可以独立的完成很多任务而无需同步。
可以利用排序和洗牌。
需要容错性,不能接受作业失败。
MapReduce是实现分布式计算的一项开创性技术:
MapReduce不是一个编程语言,而是一个框架,可以使用Java、Scala和其他编程语言在这个框架上开发分布式应用。
MapReduce的分布式文件系统不能取代关系型数据库管理系统(如 MySQL或Oracle)。一般的,MapReduce的输入是纯文本文件(一个映射器输入记录可以有一行或多行)。
MapReduce框架主要涉及用于批处理,所以不要期望能够在几秒钟内迅速得到结果。不过,如果适当的使用集群,确实可以得到近实时的响应。
并不能把MapReduce作为所有软件问题的解决方案。
基本说来,MapReduce提供了以下优点:
编程模型 + 基础架构
能够编写在数百甚至上千台机器上运行的程序
自动并行化和分布
容错性(如果一台服务器宕机,作业可以由其他服务器来完成)
程序/作业调度、状态检查和监控