文章目录
海量数据分流处理技术
MapReduce它是属于并发计算,那么可以认为MapReduce是一个海量数据分流处理技术。
因为它自身是基于Hadoop平台的,在hadoop生态里面它承担着一个集成框架这么核心的角色,那么它自身是可以处理大数据的。
划分方法 — — 最基本的海量技术思想

传统的处理海量数据划分的技术
传统hash哈希方法
找到合适的key,hash(key) mod N,结果是多少就hash到对应的机器
例如取模3,不管任何数,都会有0,1,2可能的余数,分配到三台机器
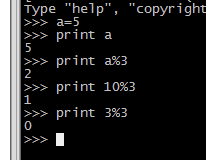

应用:流量分发
为了解决传统hash的问题,热点问题,使用一致性hash的方法


随机生成的内容,会到这个闭环的圆环上的一个数字点,向顺时针或逆时针找下面的一台机器,机器坏了,就摘除这台机器
面对海量的问题时候,一般把这个问题会分成三类:
一个是大数据量,一个是大流量,一个是面对大计算
那什么是大数据量呢?大数据量刚才我们已经说过了,就是相当于刚才说的那个对于mysql去分表这个一个思想,那一个表呢存不下那么多数据,那这时候我们需要用创建多个小表来共同承担,所以大数据量呢就可以通过刚才这种哈希的方式可以来解决这个方案。
大流量其实也是哈希方式,这个大流量相当于刚才我们举得那个新浪的,用户去请求它的首页一样,它是按照流量去划分,对流量进行一个哈希分流也可以用刚才说的一致性哈希。
大计算是一个最后的一个情况,而这个情况跟刚才我们说的那两种很简单的哈希方法是没有太大的关系的,那面对这种情况下,大数据怎么搞呢?大计算就需要用到MapReduce来去解决,那由此呢我们就引出了一个MapReduce这么一个概念。

分布式集群来说要考虑一些问题,特别是这个稳定性和这个容错能力,还有一个就是数据一致性怎么去保证
强一致性,每次新增后,都同步到其他机器上,保证全部完全一样
弱一致性,每次新增后,这台最新数据的机器就可以提供服务,这种弱一致性它可以快速的提供服务

MapReduce基础
MapReduce其实就是一个处理海量数据的分布式框架,就是有多个机器共同组成了一个集群来提供服务
这个框架解决了:
数据分布式存储,作业调度,容错,机器间复杂通信等问题

Hadoop自身是不存储数据,数据都是存储到HDFS上
Hadoop生态的底层是HDFS然后再往上走就是一个MapReduce,MapReduce不存数据只负责计算,它的数据都存储在HDFS上

一个集群里面,有master,slave和client三种角色
在hadoop里面的最基本的数据单位是block。
在block你会发现C1在第一台机器上有,在第二台机器上也有,这什么意思呢?也就是说有一个数据它可以帮你备份出多个数据,就是副本
MapReduce 分而治之的思想

解决数据可以切割的应用
分为数钱的人和汇总的人,数钱的人,只负责自己前面的一堆钞票(每个map也只处理自己的数据),数完后根据从大到小排序
最后汇总的人,再每个都合并,然后排序

计算移动,数据不移动

采用map-reduce的方式:
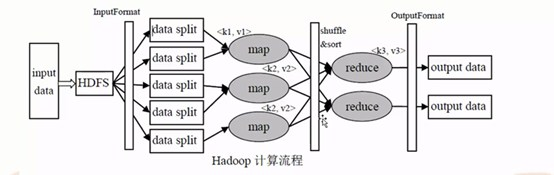

在这个HDFS上(如图所示),通过 InputFormat这么一个数据接口会把HDFS里面的大的数据会切分成5个split(就是5个分片)
这个时候切分完的这个每一个子的数据作为后续真正Map这么一个算子要读入的数据源,假设说在这里面分配了3个Map,这个时候可能第一个Map它的输入是来自两个split的,第二个Map它也是输入来自两个的split的,最后一个Map来自一个split。

然后这个Map读完这个数据处理之后,开始做一些个逻辑处理,那这个逻辑处理相当于开始把你的钱进行分门别类
分门别类之后相当于这时候Map输出就是都是已经整理好的一个结构,然后这个时候分配了两个Reduce(如下图四所示)
那这个时候Map就把数据传给reduce,那么哪些数据传给reduce呢?
比如当前这个面值,这个面值是key,然后按照这个key做一个哈希算法,然后分配到这个reduce上
然后这个reduce会去读这个数据然后做一些计算相当于后续在整个Mapreduce第二阶段主要找三个人,这三个人分别来去数数的,对这个所有每一个面值的钞票进行一个加法计算,比如说第一个reduce是数100元面值的钞票,那相当于它是把所有的Map节点输出关于100面值的数据全都汇总到第一个reduce里面去,然后reduce计算完以后直接输出,输出到output data大概是这么一个流程。
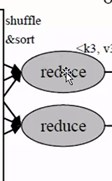
shuffle 和 sort
shuffle是随机分配,就是把map的那个key做一个哈希
因为后面有两个reduce,所以取模就取模了2,那取模了2就是得到了0和1
最后得到你当前的这个key取出的那个模然后把这个数据分配到对应的reduce上去。
而这个sort排序是什么意思呢?
会发现如果说一堆钱,钱里面有100元的,有50元的,有10元的,发现如果按照这个key排序之后,你会发现100元的会统一的跑到一个区间里面去,50元的跑到一个区间,10元的跑到一个区间。

在这个map阶段,一个map其实就是对应着一个split分片
因为map是一个程序,他在这个计算机上这个系统里面是启动了一个进程,那么启动了一个进程,维护了一个进程空间,把这个split数据读进来之后把这个数据直接存到了内存(buffer in memory)上,然后就开始往这个内存去写数据
这个内存它也是有大小的,默认的内存大小是100M,但是100M很容易就满了,那么这个时候当它写到80M的时候,也就是它已经写到了整个内存的百分之80的时候就不能动了,只能往百分之20上去写,那把这个百分之80已经写好的区域锁住,然后把这百分之80里面的数据开始统一的往磁盘上写并且清空那原先锁住的百分之80的内存数据
但是这个转储的过程中不仅是简简单单的把数据内存直接存到了磁盘上,但是在这个存储的过程中还需要中间涉及到了一次sort排序,会发现这个数据不断的引入,那这个内存(buffer in memory)就会慢慢的产生很多的小的数据,然后每一个数据都是有不同的一个区域,然后这个partition小的数据,然后把内存的数据往这个磁盘上去写的时候它会做排序
比如说我在这个内存里面都是一些100元钞票的数据,50元钞票的数据,10元钞票的数据,那开始拿这个数据的时候它是一个杂乱的数据,那么通过一次排序之后会发现100元的会排到一块,50元排到一块,10元排到一块,无论是从大到小排还是从小到大排最后这个key肯定是排到一块很整齐的队列。
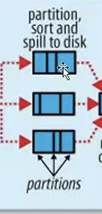
这最上面第一个三个长方形是一个小的数据,这小的数据里面又切成了三个部分(如上图8所示)那这三个部分都代表着100元钞票和50元钞票和10元钞票的数据
每一个小的数据里面都分三个区域。随着数据不断的引入你会发现从这个Map里面会产生出很多很多的这样的小数据文件。那么这个时候发现磁盘上已经有很多这样小的文件了,那应该把这些小的文件进行合并,怎么合并呢?
就是用了一次归并排序。
归并排序:开始把指针都指向各自文件的文件头上,然后开始互相之间比较,就是比如三个文件,每一个文件都有一个指针,然后相当于每一个指针都相当于按照从大到小已经排序好的,那么这个时候去往这个大的数据上开始合并。
相当于,三个都是100,50,30的,每个文件都有指针,比较,把最大的指针的数据写入
归并排序的前提是你指的每一个数据的都是先排好序的,这就是归并排序。然后做好归并排序之后产生大的文件也是排好序的。

比如这个reduce只处理一个100元面值的金额的钞票,把每个map上属于100元的区域的数据全部归纳到reduce里面的merge节点机器上,就是把数据硬拷贝过去reduce里面,那么这时候reduce这机器上面发现可以拷贝出多个数据(merge),那这个数据量也是很大的,因为数据小的文件比较多,这时候就会慢慢的再去做合并(merge),通过不断的合并慢慢的就合并成大的数据,然后再统一的扔给reduce,然后reduce再进行数据计数工作最后输出,这么一个过程。
当然reduce读的过程中,它也是把这个数据读到了reduce机器的内存中,然后在内存里面也会有相应的排序。
一个reduce可以处理不同的数据也可以处理一种面值的数据或者是一个reduce可以处理多个面值钞票。
reduce也是有缓存的。

如图,数据(InputSplit)进来一个map进程(Mapper),然后把这个数据直接输出到了一个缓冲内存区里面,在这个内存区里面做排序,在这内存区域里面在往磁盘上写数据的时候,这个过程是经历一个排序的,那么排序根据key排序
那么谁是key呢?
就是你这个数据在缓冲区里面的会有两列数据一列是一百元钞票,第二列是代表一个1。
为什么会有排序呢?
把这个缓冲区的数据不经过排序直接存到磁盘上会发现这个数据是乱的,目的是把相同的key排到一块,然后把缓冲区排序好的数据输出到磁盘上,每次输出都产生了很多小的文件数据(Spill.n)。
接下来有很多的这样一个小的文件数据(Spill.n,n表示数字)


MapReduce的开发也是很简单,只需要考虑两个函数就可以了,那这两个函数分别是一个map函数和一个reduce函数
 shuffing 这个部分
shuffing 这个部分
MapReduce集成框架有两个很重要的进程
第一个进程是JobTracker,第二个进程是TaskTracker,
JobTracker是主进程,TaskTracker是从进程。
JobTracker主进程是用来接收客户的请求并且做任务调度,然后把这个任务分配到从节点。
而TaskTracker从进程是由JobTracker来派任务的,并且在本地开始进行工作,然后每隔3秒钟会向主进程做一次工作的汇报。
JobTracker不仅是分派任务的也是做监控的,监控从进程的状态是否良好,如果有一台从进程出现故障,那么JobTracker主进程会把任务分派给其他的从进程当中去
 这个是MapReduce执行的流程。
这个是MapReduce执行的流程。
首先用户是作为我们工程师,然后提交作业,这个作业是在我们机器上提交,这个机器就是客户端(JobClient)
我们JobClient在请求一次任务的时候需要跟JobTracker打交道,首先得跟老板建立关系,然后老板就会按照JobClient所给的要求制定方案,然后会寻找空闲的机器进行工作。
这个时候会反馈给这个JobClient一个id号,这个id代表着你的这个任务,这个时候JobClient拿到了这个id可以在HDFS分布式文件系统上创建一个目录,这个目录名字就叫job ID,那么在这个目录里面把客户写的代码要求写的程序要求(就像需求一样)从本地进行拷贝到HDFS上
接下来JobTracker收到了需求以后就开始去工作了,然后这个JobTracker接收了这个客户需求以后开始初始化,然后分配工作把HDFS上的需求数据进一些个分发,分发给TaskTracker从进程进行处理,然后TaskTracker在工作处理过程中也是不断的去汇报给JobTracker当前的工作一个状态。
MR作业的调度:FIFO默认是先进先出队列
MapReduce有五种优先级,每一个优先级代表着每一个用户它提交作业的时候,都会分配一个优先级,如果说当有一个用户特别着急,这个任务很急着要做,那么就可以跨越那些低优先级的,然后可以提前做。




• JobTracker一直在等待JobClient提交作业
• TaskTracker每隔3秒向JobTracker发送心跳询问有没有任务可做,如果有,让
其派发任务给它执行
• Slave主动向master拉生意

wordcount代码实践:

