一、回顾
上面三篇,主要介绍了相关的理论知识,其中构建决策树的过程可以很好地帮助我们理解决策树的分裂属性的选择。
本篇所有源代码:Github
二、决策树的Python实现
假设我们有数据集:
dataSet = [
[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']
]
labels = ['第一个特征', '第二个特征']
我们用第二篇中介绍的信息增益的方法,来构造决策树,然后再用python代码实现:
1. 信息熵
0 表示’no’,1 表示’yes’,P(0) 表示标签为 ‘no’ 的概率
2. 信息增益
由于第一个特征的信息增益大于第二个特征的信息增益,选择第一个特征作为根节点
此时就剩一个特征了,可以直接画,使用 多数表决法 决定叶子节点所属类别;如果还有其他特征,可以重复以上操作,直到达到决策树停止条件。
- 使用 多数表决法 构成分类决策树
- 如果决策规则不是使用多数表决法,而是使用 均方误差(MSE)或平均绝对误差(MAE) ,就可以构成回归决策树
3. 画出决策树
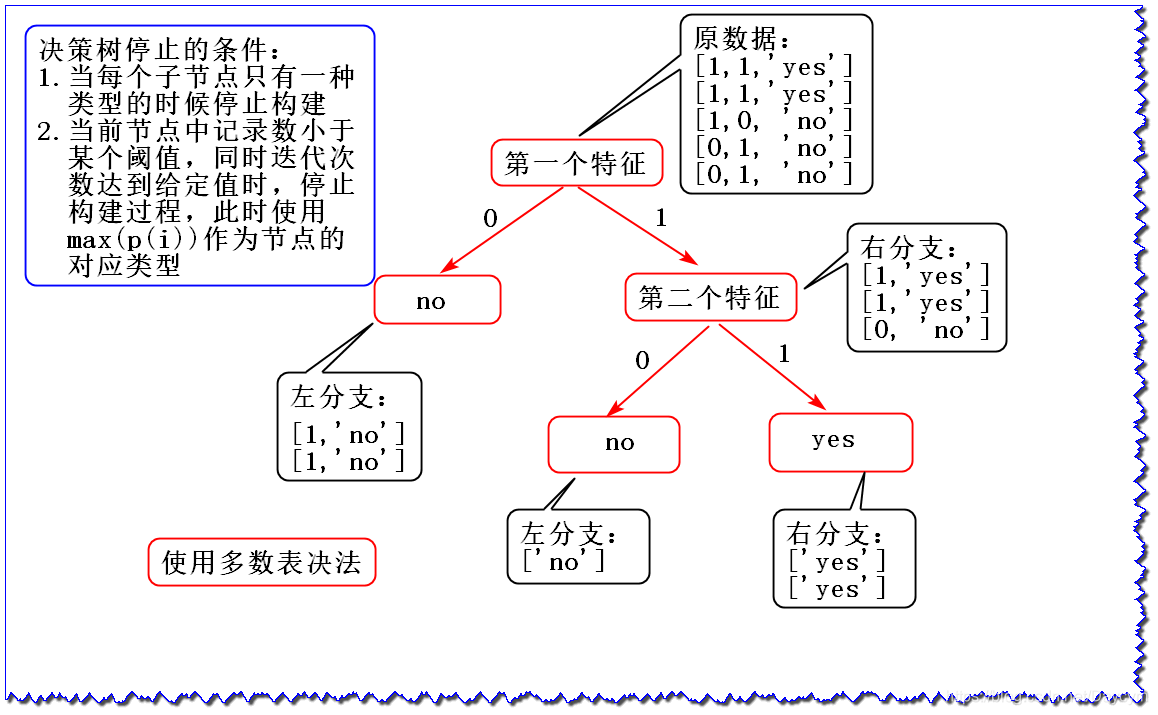
上图便是最终的决策树结构
4. 代码实现
代码可见:01_决策树的实现.py
运行结果为:
myTree: {'第一个特征': {0: 'no', 1: {'第二个特征': {0: 'no', 1: 'yes'}}}}
可见,运行结果和上图是一样,首先按第一个特征作为分裂属性,然后再按第二个属性
三、分类决策树案例
1. 鸢尾花数据分类
本案例主要看看使用决策树模型的一般步骤。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集)
- 数据预处理(数据归一化、特征选择、降维)
- 模型构建及训练
- 模型预测
- 模型评估
- 画图
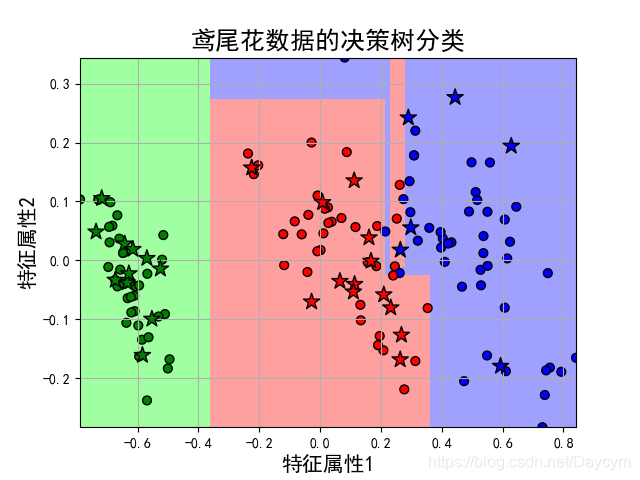
可得到如下结果:
Score: 0.9666666666666667
Classes: [0 1 2]
获取各个特征的权重:[0.91754496 0.08245504]
由结果可见,正确率达到了96.7%
本案例通过特征选择选择了3个特征,当三维不好画图;
然后通过降维处理,降为二维,得到以上结果
代码可见:02_鸢尾花数据分类.py
2. 鸢尾花数据分类(参数优化)
本案例主要是选择出最优的模型参数(超参数),以使模型达到最优。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集):至此和三个案例一样
- 参数优化(通过管道设置模型及参数)
- 模型构建及训练
- 模型评估
- 应用以上得到的最优参数查看效果
最优参数列表: {'decision__criterion': 'gini', 'decision__max_depth': 4, 'pca__n_components': 0.99, 'skb__k': 3}
score值: 0.95
最优模型:Pipeline(memory=None,steps=[('mms', MinMaxScaler(copy=True, feature_range=(0, 1))),
('skb', SelectKBest(k=3, score_func=<function chi2 at 0x0000010FDCA9A0D0>)),
('pca', PCA(copy=True, iterated_power='auto', n_components=0.99, random_state=None, svd_solver='auto', tol=0.0, whiten=False)),
('decision', DecisionTreeClass... min_weight_fraction_leaf=0.0, presort=False, random_state=0, splitter='best'))])
代码可见:03_鸢尾花数据分类_参数优化.py
3.鸢尾花数据分类(决策树深度不同)
本案例主要为了测试决策树不同深度给模型带来的效果。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集):至此和三个案例一样
- 模型训练(基于不同深度依次训练,此处省略了数据预处理),并记录每个深度下的正确率
- 画出正确率变化图
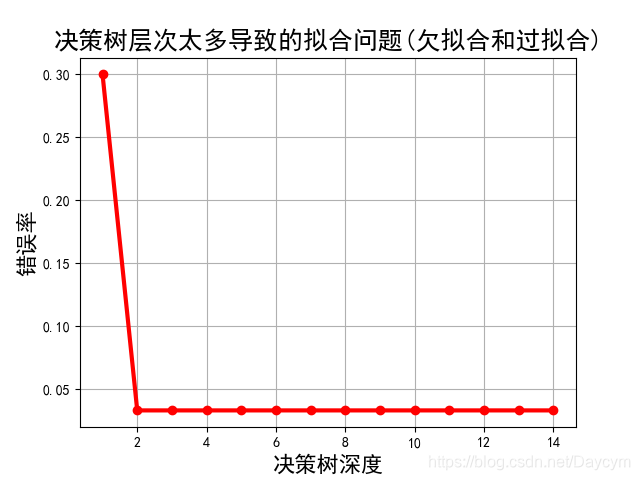
运行结果可能不一样,大体可以看出:
- 当决策树深度为1时,错误率比较大,此时模型欠拟合;
- 当决策树深度为2时,错误率达到最低;
- 之后,错误率基本没变化,说明此时的模型以及开始过拟合了;
代码可见:04_鸢尾花数据分类_决策树深度不同.py
4.鸢尾花数据分类(特征属性比较)
本案例主要是使用2个特征来训练模型,并且这两个特征为任意组合,最后查看每个模型的效果。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集):至此和三个案例一样
- 特征比较(每组特征模型训练,画图)
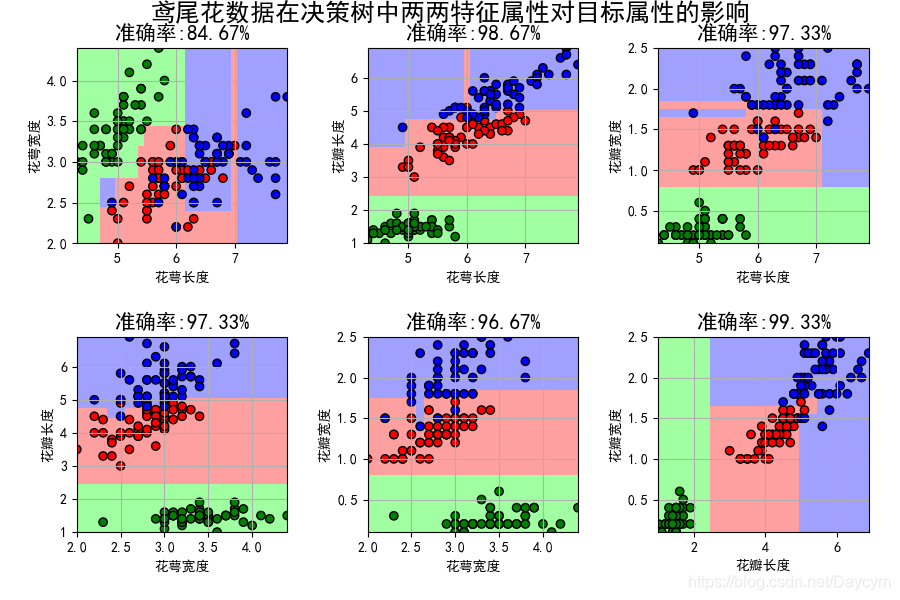
由图可看出,使用花瓣长度和花瓣宽度特征,模型正确率达到了99.33%,可以推断这两个特征对于分类决策的效果最好。
也就是这三类花在花瓣长度和花瓣宽度有不同的大小
代码可见:05_鸢尾花数据分类_特征比较.py
四、回归决策树案例
1. 波士顿房屋租赁价格预测
本案例使用回归决策树进行房屋租赁价格预测,并与之前在回归算法中使用线性回归、Lasso回归、Ridge回归进行比较。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集):这些步骤和前面的案例类似
- 数据处理(数据归一化)
- 模型构建,并训练,预测,评估(决策树、线性回归、Lasso回归、Ridge回归)
- 画图
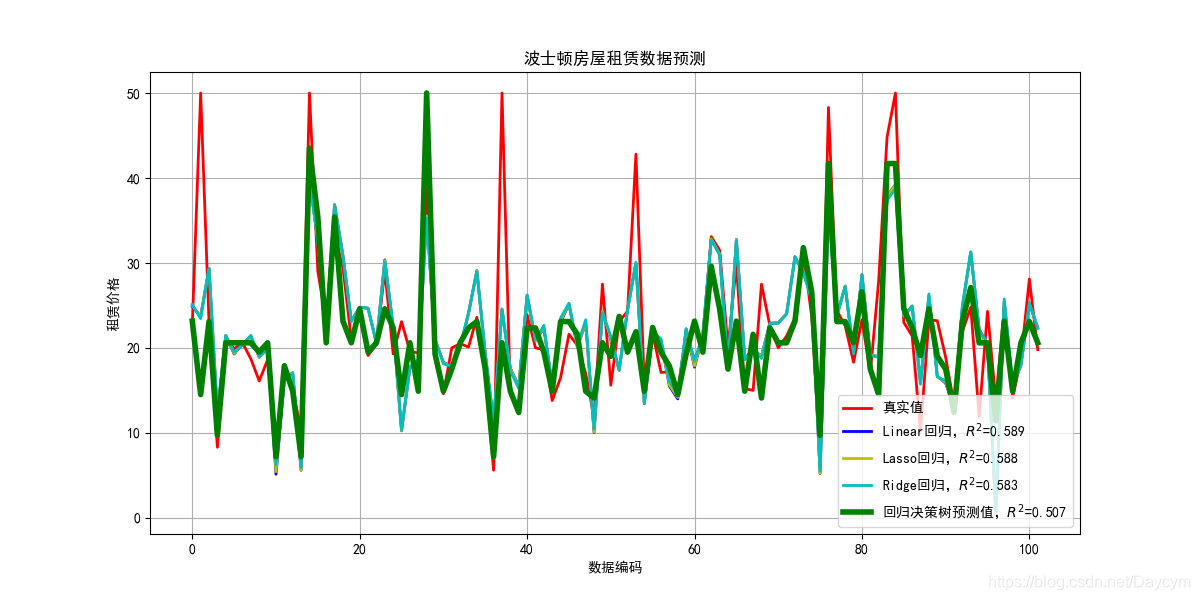
由图可知,回归决策树的效果其他方法的效果都好
代码可见:06_波士顿房屋租赁价格预测.py
2. 波士顿房屋租赁价格预测(参数优化)
本案例是主要是选择出最佳模型的参数。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集)
- 参数优化(通过管道设置模型及参数)
- 模型构建及训练
- 应用以上得到的最优参数查看效果
运行结果为:
0 score值: 0.4001529052721232 最优参数列表: {'decision__max_depth': 7, 'pca__n_components': 0.75}
1 score值: 0.7569661898236847 最优参数列表: {'decision__max_depth': 4}
2 score值: 0.7565404744169743 最优参数列表: {'decision__max_depth': 4}
正确率: 0.8435980902870441
此程序每次运行得到的最优模型的参数有些不一样 ,不过最后的正确率都差不多
代码可见:07_波士顿房屋租赁价格预测_参数优化.py
3. 波士顿房屋租赁价格预测(决策树不同深度)
本案例主要为了测试决策树不同深度给模型带来的效果。
实现步骤:
- 读取数据
- 划分数据(特征数据与标签数据分开)
- 数据分割(训练集和测试集):至此和三个案例一样
- 模型训练(基于不同深度依次训练,此处省略了数据预处理),并记录每个深度下的正确率
- 画出正确率变化图
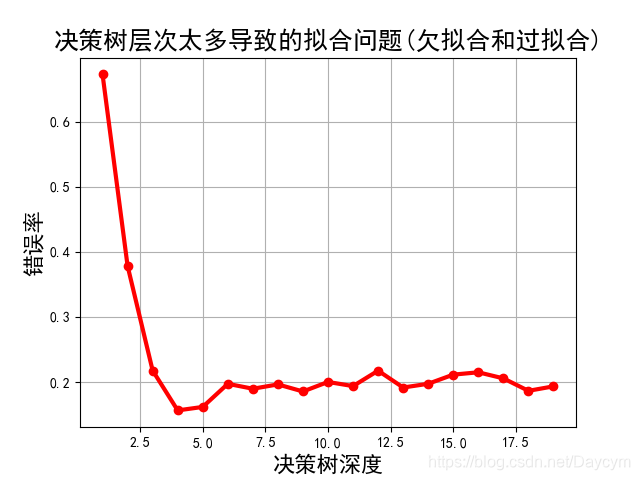
由上图可知:
- 当深度比较小的时候,错误率比较高,模型欠拟合;
- 当深度为4的时候,错误率达到了最低,模型最佳;
- 再增加模型深度,错误率一直在波动,说明说明模型开始过拟合了
代码可见:08_波士顿房屋租赁价格预测_决策树深度不同.py
五、回归决策树过欠拟合与过拟合
本案例主要是通过随机数据,看决策树深度对模型拟合程度的影响。
实现步骤:
- 数据准备(随机构造数据,此处构造的是sin(x),加上随机噪声)
- 模型构造(构造深度不一样的)
- 模型训练
- 模型预测(随机产生测试数据)
- 画图展示
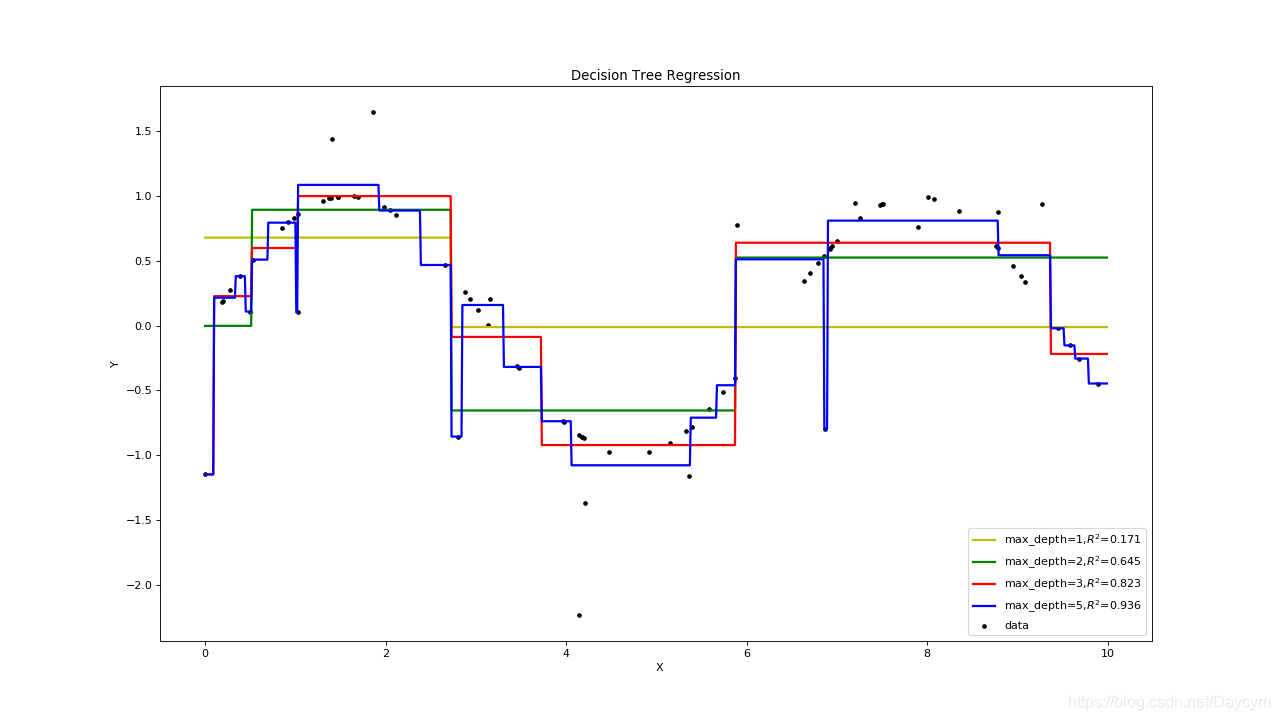
由上图可知:
- 当深度为1,2的时候,图中黄色,、绿色的线,明显出现了欠拟合;
- 当深度为5的时候,模型是和大多数数据吻合,但也把噪声也拟合的很好,出现了过拟合;
- 当深度为3的时候,模型对数据比较拟合,当然也不一定是最优的。
代码可见:09_决策树欠拟合与过拟合.py
注:
- 如果使用线性回归算法,那么拟合的线应该是曲线,当用回归决策树来拟合时,会呈一段一段的;
- 因为,回归决策树和分类决策树的区别就在于决策规则,回归决策树使用的是均方误差之类的,是根据样本求得的,所以只会是一些点,不会连成曲线
总结
-
决策树过拟合一般情况是由于节点太多导致的,剪枝优化对决策树的正确率影响是比较大的,也是最常用的一种优化方式。可见:剪枝处理
-
此外,随机森林(Random Forest)也是常用的优化方式,利用训练数据随机产生多个决策树,形成一个森林。然后使用这个森林对数据进行预测,选取最多结果作为预测结果。