决策树是一个类似于流程图的树结构,每一个节点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶节点代表类或类分布,树的最顶层是根节点。
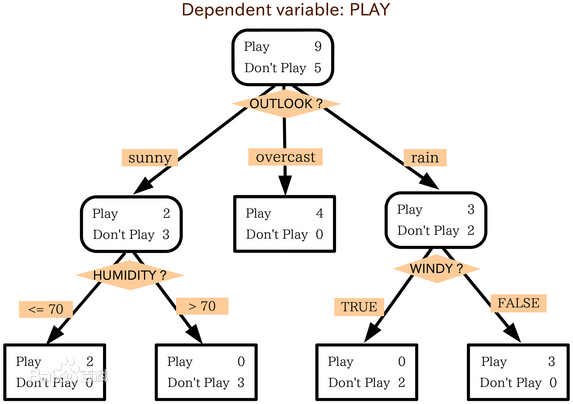
一个例子如图,对一组情况下出不出去玩play进行判断分类,根节点测试属性’天气’,假如为阴天overcast那么出去玩,假如晴天,再判断湿度条件,假如雨天判断当天有没有风等对是否出去玩进行判断。这样只要给出天气,湿度,风的信息就能直接对这种情况下是否出去玩进行判断分类。这就是决策树。
构造决策树的算法有很多,不同的算法之间区别在于选取哪一个属性先进行判断,哪个属性后进行判断,也就是属性判断节点的确立。这里以ID3算法为例进行介绍。
要介绍ID3算法,首先要说明一个概念——信息熵。信息熵是香农于1948年提出的,用于衡量信息量的大小。计算方式是
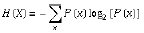
也就是不同结果出现概率乘上概率的负对数的和。结果单位是bit
ID3算法就是通过信息熵计算信息获取量(Information Gain)来进行属性选取。
信息获取量的计算方式是Gain(A) = info(D)-info_A(D),原始的信息量-代入属性A后的信息量。
举个例子 ,还是上图的例子,如图我们可以看出,一共14种情况,9种出去玩,5种不出去玩。
根据信息熵的公式,info(D) = -(9/14)*log2(9/14)-(5/14)*log2(5/14)=0.94bits
选择属性A为天气,A有3种情况晴,阴,雨则
info_A(D)=5/14*(-2/5*log2(2/5)-3/5*log2(3/5))+
4/14*(-1*log2(1)-0*log2(0))+5/14*(-3/5*log2(3/5)-2/5*log2(3/5))= 0.694bits
所以Gain(A) = 0.94 - 0.694 = 0.246bits 这就是天气属性的信息获取量,可以用同样的方法算出其它湿度和风的信息获取量,这里略过,结果上天气信息获取量的值是最大的,故将天气作为根节点进行判断,这就是ID3的算法。
另外决策树的属性都是分类的,即离散值,连续的属性必须离散化。比如年龄属性有很多数字1到100岁,必须把它离散化划分,比如18岁以下的一块,40岁以上的一块这样。
下一篇是用Python中scikit-learn库对ID3算法的应用实践。
本系列文章是对麦子学院彭亮老师机器学习课程学习过程的笔记,用于复习总结。