刚开始的时候打算使用java程序直接登陆网站在进行后续操作,后来发现有些网站的重定向太多不好操作,
所以改用已登录的cookie 来保持会话,
使用方式很简单,只需要在浏览器上登录你要操作的网站,然后获取cookie值,将cookie放到程序里就实现了保存会话的功能了,
1、添加maven 依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient-cache</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpmime</artifactId>
<version>4.1.2</version>
</dependency>2、登录网站,然后输入账号密码登录,按下F12功能键(或者在网页空白处右击->检查),
然后会弹出浏览器的调试页面--> 网络 --> 消息头 --> 下面的cookie一栏就是我们要的值了,先把它复制
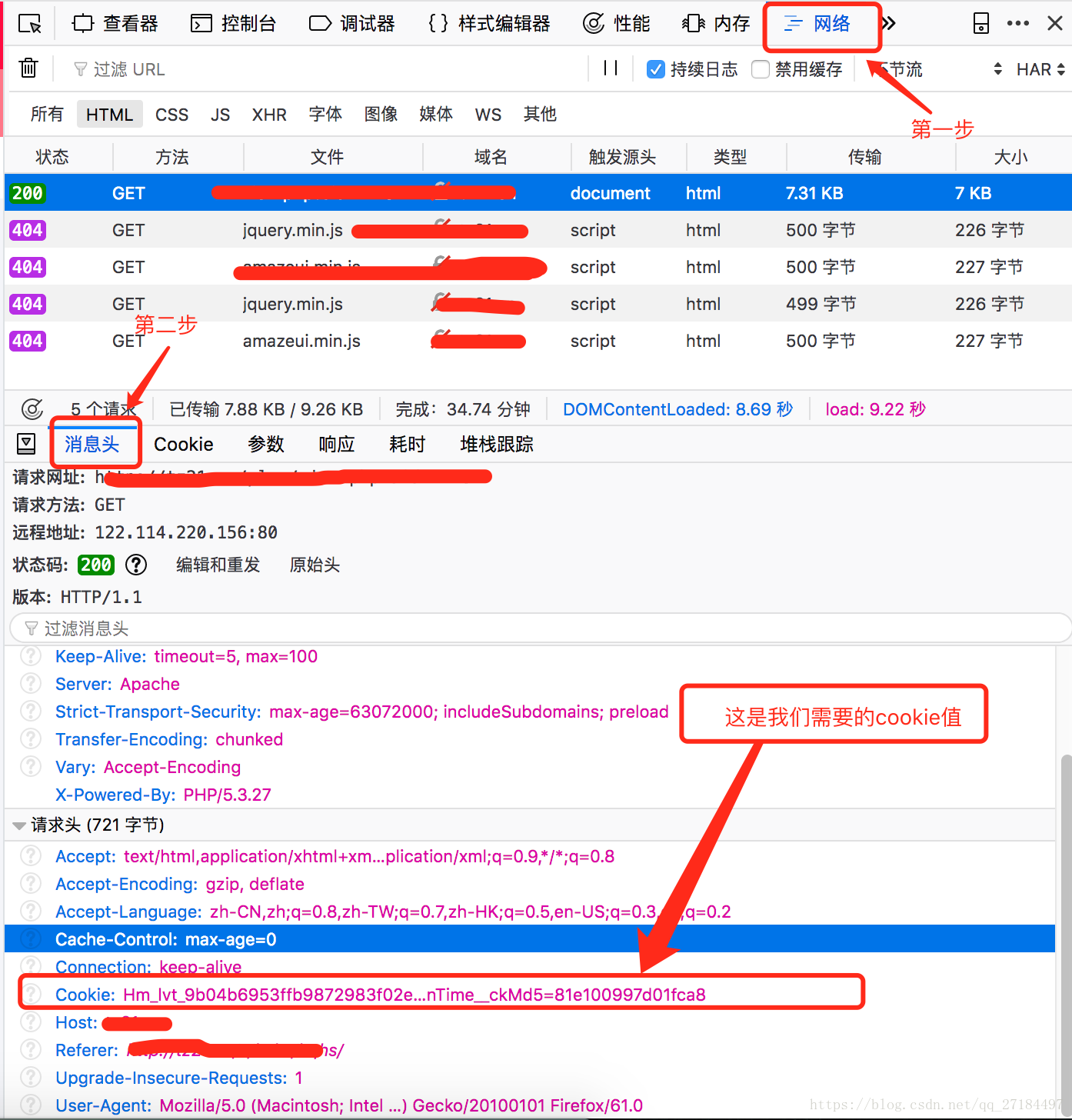
3、上代码,header添加刚才复制的cookie值
package com.html;
import java.util.HashMap;
import java.util.Map;
import org.apache.http.Header;
import org.apache.http.HttpEntity;
import org.apache.http.HttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.message.BasicHeader;
import org.apache.http.util.EntityUtils;
public class HtmlRequest {
public static void main(String[] args) {
//需要爬数据的网页url
String url = "http://www.baidu.com";
Map<String, String> header = new HashMap<String, String>();
//将浏览器的cookie复制到这里
header.put("Cookie", "Hm_lvt_9b04b6953ffb9872983f02eee2929d23=1536065531; Hm_lpvt_9b04b6953ffb9872983f02eee2929d23=1536066013; PHPSESSID=eemc0vbbmbr57d6s9rhvh6rav7; DedeUserID=6745; DedeUserID__ckMd5=ac9f8bd4bd2227be; DedeLoginTime=1536068126; DedeLoginTime__ckMd5=81e100997d01fca8");
System.out.println(httpGet(url, null, header));
}
/**
* 发送 get 请求
*
* @param url
* @param encode
* @param headers
* @return
*/
public static String httpGet(String url, String encode, Map<String, String> headers) {
if (encode == null) {
encode = "utf-8";
}
String content = null;
DefaultHttpClient httpclient = new DefaultHttpClient();
HttpGet httpGet = new HttpGet(url);
// 设置 header
Header headerss[] = buildHeader(headers);
if (headerss != null && headerss.length > 0) {
httpGet.setHeaders(headerss);
}
HttpResponse http_response;
try {
http_response = httpclient.execute(httpGet);
HttpEntity entity = http_response.getEntity();
content = EntityUtils.toString(entity, encode);
} catch (Exception e) {
e.printStackTrace();
} finally {
//断开连接
// httpGet.releaseConnection();
}
return content;
}
/**
* 组装请求头
*
* @param params
* @return
*/
public static Header[] buildHeader(Map<String, String> params) {
Header[] headers = null;
if (params != null && params.size() > 0) {
headers = new BasicHeader[params.size()];
int i = 0;
for (Map.Entry<String, String> entry : params.entrySet()) {
headers[i] = new BasicHeader(entry.getKey(), entry.getValue());
i++;
}
}
return headers;
}
}4、然后直接运行main方法,打印出已登录网站的html页面数据,

总结:使用java实现自动登录并且进行后续操作的功能目前还在研究中,一天进步一点点,rmb在向你招手,
宣传下个人网站:www.huashuku.top