确保5台linux系统节点已准备
|主机名| 内存|cpu
|nna|2G|2核
|nns|2G|2核
|dn1|1G|1核
|dn2|1G|1核
dn3|1G|1核
1、给系统设置静态IP,可以参照我之前的hadoop 集群部署中静态ip设置
https://mp.csdn.net/mdeditor/84073712#
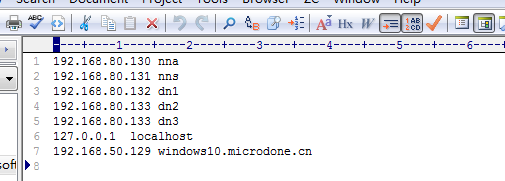
2、所有linux系统配置hosts系统文件。添加ip映射,
vi /etc/hosts

3、创建hadoop 账号,用来专门管理集群环境
useradd hadoop
passwd hadoop
//创建后再sudoers文件添加hadoop
3.1 添加 sudoers 写权限
chmod +w /etc/sudoers
3.2 vi在末尾添加:hadoop ALL=(root)NOPASSWD:ALL
3.3 关闭写权限
chmod -w /etc/sudoers
4.SSH 免密登录
4.1 在nna 节点下 生成该节点的私钥和公钥
ssh-keygen -t rsa
4.2 认证授权,将id-rsa.pub 文件内容追加到authorized_keys 文件中,如果在、~/.ssh 目录下没有authorized_keys 文件,自己手动添加即可。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/suthorized_keys
4.3 文件授权,赋予600权限
chmod 600 ~/.ssh/authorized_keys
4.4 其他节点通过使用hadoop 账号授权,然后将各个节点的id_rsa.pub 追加到nna 节点的authorized_keys 中
,生成公钥后,使用 ssh-copy-id nna,即可

4.5 在完成所有节点公钥追加之后,将nna节点下的authorized_keys 文件通过scp,分发到其他节点的hadoop ~/.ssh 目录下。

5 、关闭防火墙
所有linux系统都执行下面语句关闭防火墙,当然我的是centos7,不同版本关闭防火墙命令不同,自行百度。
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动**
6修改时区。确保hadoop集群各个节点时间同步。
能与当前网络的时间有误差。下面介绍一下与时间服务器上的时间同步的方法
6.1. 安装ntpdate工具
yum -y install ntp ntpdate
(如果安装不了,请在/etc/sysconfig/network_scripts 下面的ifcfg-ens33, 添加域名)

6.2. 设置系统时间与网络时间同步
ntpdate cn.pool.ntp.org
6.3. 将系统时间写入硬件时间
hwclock --systohc
7,zookeeper 部署
zookeeper 3.4.10 下载地址
http://mirrors.shu.edu.cn/apache/zookeeper/zookeeper-3.4.10/
7.1 解压,
tar -zxvf zookeeper-3.4.10.tar.gz
//重命名
mv zookeeper-3.4.10 zookeeper
{kind=link}
mkdir data
7.2配置zoo.cfg 文件


在data 文件下面创建myid 文件,在该文件下入一个0-255之间的整数,每个节点这个数字都是唯一的,本书的这些数字从1开始。
比如server.1=dn1:2888:3888,那么在节点dn1,就应该填数字1.
然后scp同步dn1节点上的zookeeper文件到其他节点

7.3 安装jdk ,可以参照下面文章中的jdk 环境变量配置
https://mp.csdn.net/mdeditor/84073712#
7.4 配置zookeeper 环境变量:dn1,dn2,dn3 节点都需要
在 /etc/profile 下添加
export ZK_HOME=/home/hadoop/zookeeper
export PATH=$ PATH:$ZK_HOME/bin

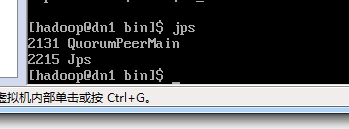
7.5 验证 ,在dn1,dn2,dn3终端输入jps命令:如下图,有了QuorumPeerMian
8、部署安装hadoop
下载hadoop 安装包,并解压到/home/hadoop 目录下
,配置环境变量:
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
exprot PATH=$PATH:$HADOOP_HOME
8.2 配置 core-site.xml
<configuration>
<!--指定分布式系统文件存储的nameservice 为cluster1-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster1</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.7.7/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!-- 所有账户都可以访问 -->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<!-- 所有IP都可以访问 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
</configuration>
配置 yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!-- RM(Resource Manager)失联后重新链接的时间 -->
<property>
<name>yarn.resourcemanager.connect.retry-interval.ms</name>
<value>2000</value>
</property>
<!-- 开启Resource Manager HA,默认为false -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 配置Resource Manager -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!-- 开启故障自动切换 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- rm1配置开始 -->
<!-- 配置Resource Manager主机别名rm1角色为NameNode Active-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nna</value>
</property>
<!-- 配置Resource Manager主机别名rm1角色为NameNode Standby-->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nns</value>
</property>
<!-- 在nna上配置rm1,在nns上配置rm2,将配置好的文件远程复制到其它机器上,但在yarn的另一个机器上一定要修改-->
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<!-- 开启自动恢复功能 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 配置与zookeeper的连接地址 -->
<property>
<name>yarn.resourcemanager.zk-state-store.address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!--用于持久化RM(Resource Manager简称)状态存储,基于Zookeeper实现 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- Zookeeper地址用于RM(Resource Manager)实现状态存储,以及HA的设置-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
<!-- 集群ID标识 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1-yarn</value>
</property>
<!-- schelduler失联等待连接时间 -->
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>
<!-- 配置rm1,其应用访问管理接口 -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nna:8132</value>
</property>
<!-- 调度接口地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nna:8130</value>
</property>
<!-- RM的Web访问地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nna:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>nna:8131</value>
</property>
<!-- RM管理员接口地址 -->
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nna:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm1</name>
<value>nna:23142</value>
</property>
<!-- rm1配置结束 -->
<!-- rm2配置开始 -->
<!-- 配置rm2,与rm1配置一致,只是将nna节点名称换成nns节点名称 -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nns:8132</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nns:8130</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nns:8188</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nns:8131</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nns:8033</value>
</property>
<property>
<name>yarn.resourcemanager.ha.admin.address.rm2</name>
<value>nns:23142</value>
</property>
<!-- rm2配置结束 -->
<!-- NM(NodeManager得简称)的附属服务,需要设置成mapreduce_shuffle才能运行MapReduce任务 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 配置shuffle处理类 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- NM(NodeManager得简称)本地文件路径 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/hadoop-2.7.7/yarn/local</value>
</property>
<!-- NM(NodeManager得简称)日志存放路径 -->
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/home/hadoop/hadoop-2.7.7/yarn/log</value>
</property>
<!-- ShuffleHandler运行服务端口,用于Map结果输出到请求Reducer -->
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!-- 故障处理类 -->
<property>
<name>yarn.client.failover-proxy-provider</name>
<value>org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider</value>
</property>
<!-- 故障自动转移的zookeeper路径地址 -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.zk-base-path</name>
<value>/yarn-leader-election</value>
</property>
<property>
<name>mapreduce.jobtracker.address</name>
<value>http://nna:9001</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>259200</value>
</property>
<property>
<name>yarn.log-aggregation.retain-check-interval-seconds</name>
<value>3600</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>nna:8090</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<property>
<name>yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/data/soft/new/hadoop/etc/hadoop/fair-scheduler.xml</value>
</property>
-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>4.2</value>
</property>
</configuration>
配置mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>0.0.0.0:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>0.0.0.0:19888</value>
</property>
</configuration>
配置hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为...,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>cluster1</value>
</property>
<!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster1</name>
<value>nna,nns</value>
</property>
<!-- nna的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nna</name>
<value>nna:9000</value>
</property>
<!-- nna的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nna</name>
<value>nna:50070</value>
</property>
<!-- nns的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.cluster1.nns</name>
<value>nns:9000</value>
</property>
<!-- nns的http通信地址 -->
<property>
<name>dfs.namenode.http-address.cluster1.nns</name>
<value>hostbb:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://dn1:8485;dn2:8485;dn3:8485/cluster1</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoop-2.7.7/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<!-- 指定元数据冗余分数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定datanode 数据存储地址 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-2.7.7/nodedata</value>
</property>
<!-- 指定web 访问hdfs目录 -->
<property>
<name>dfs.webhdfs.enable</name>
<value>true</value>
</property>
<!-- 实现自动故障切换 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>dn1:2181,dn2:2181,dn3:2181</value>
</property>
</configuration>
8.3 启动journalnode
8.3.1 在任意一台namdnode节点上启动Journalnode
sbin/hadoop-daemon.sh start journalnode
8.3.2 输入jps
查看终端是否 显示对应线程(journalNode)

8.4,启动hadoop
初次启动集群时,需要格式化namenode节点,
bin/hdfs namenode -format
8.5 向zookeeper 注册
bin/hdfs zkfc -formatZK
8.6启动集群
bin/hdfs start-all.sh
hadoop访问地址:
http://nna:50070
http://nna:8188
我的是在windows 系统下访问,记得修改win的hosts 地址映射,
加上