1.Python版本以及库说明
Python3.7.1 Python版本urlencode 可将字符串以URL编码,用于编码处理bs4 解析html的利器re 正则表达式,用于查询页面的一些特定内容requests 得到网页html、jpg等资源的libos 创建文件夹需要用到系统操作libtime 时间模块,获取日期建立文件夹html5lib 解析模块lxml 解析模块multiprocessing 多线程模块
2.IDE
Pycharm
3.浏览器页面检查工具
QQ浏览器
4.爬虫抓取过程分析
4.1https请求的uesr_head参数设置
agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 ' \
'(KHTML, like Gecko) Chrome/63.0.3239.26 ' \
'Safari/537.36 Core/1.63.6721.400 QQBrowser/10.2.2243.400'
headers = {
'user-agent': agent4.2分析top100列表页面(利用ajax获得全部数据)
页面地址是https://bcy.net/coser/toppost100
进入页面发现只有前30名的图片,但当我们下拉可以发现,页面动态加载了全部的COS图,利用页面检查功能 我们分析这是一个ajax请求,我们可以通过构造ajax请求来获得全部图片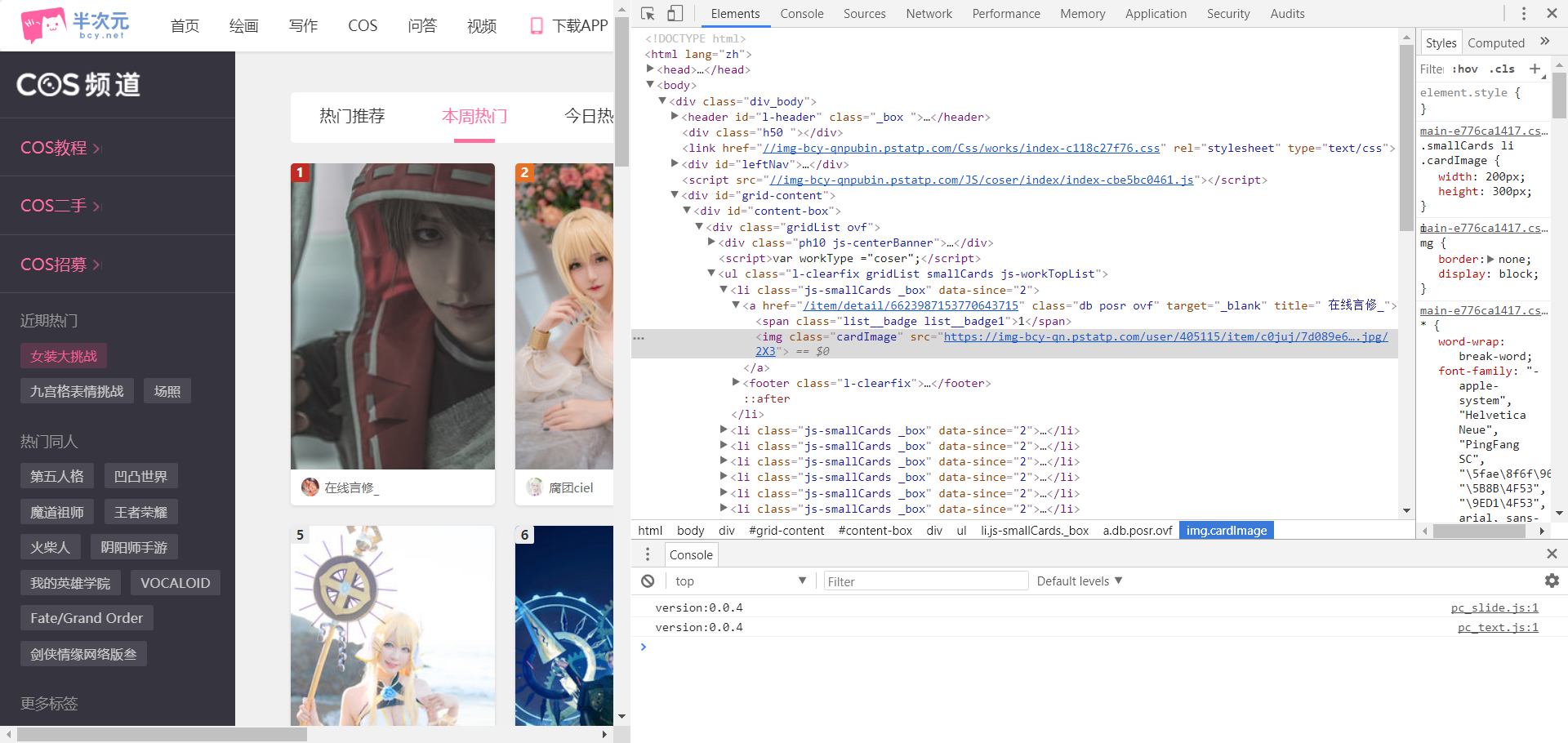
我们打开页面检查工具,选择Network,然后在选择XHR,也就是ajax的核心——XMLHttpRequest对象,我们看到初始页面仅有两个文件,下拉使会产生新的文件,我们查看新文件的Query String Parameters可以发现其发送了一组json数据
'p': 2,
'type': 'week',
'data': ''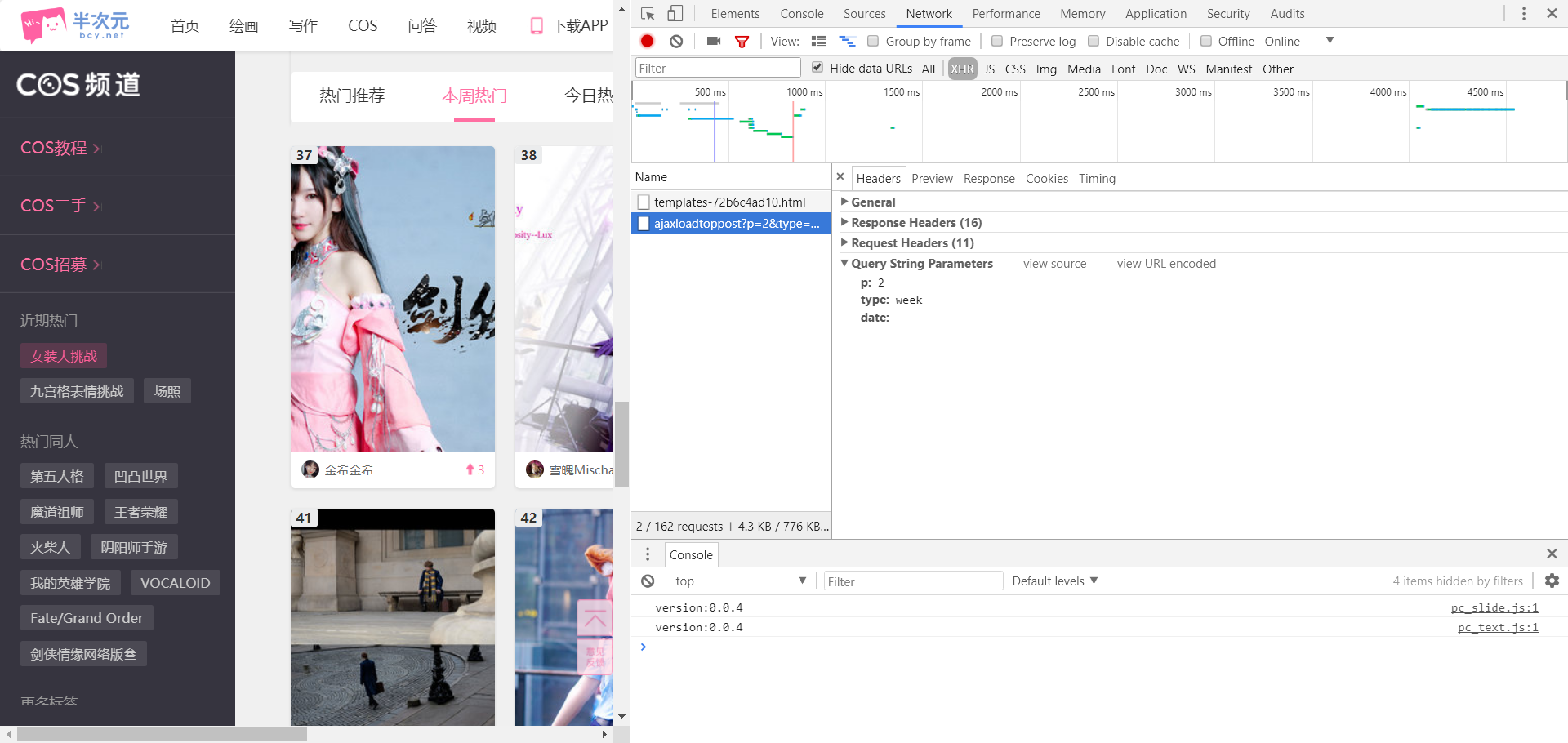
我们可以推断p应该代表页码,type应该代表这是本周热门的数据
我打算通过构造url直接获取数据时发现页面404,这也是我对与前端以及ajax不熟悉的原因吧
params = {
'p': page,
'type': 'week',
'data': ''
}
base_url = 'https://bcy.net/coser/toppost100'
url = base_url + urlencode(params)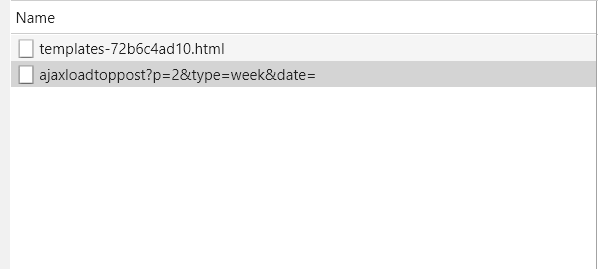
查了查资料,也不是很懂,最后我直接XHR产生的新文件,顿时醒悟,我来到了这样的页面
我们看到页面的url是https://bcy.net/coser/index/ajaxloadtoppost?p=2&type=week&date=
自己手动修改p=2中的值就可以获得图片的页面了
4.3soup对象查找源代码中的链接
首先查找li标签
all_li = soup.find_all('li', class_=re.compile('js-smallCards _box'))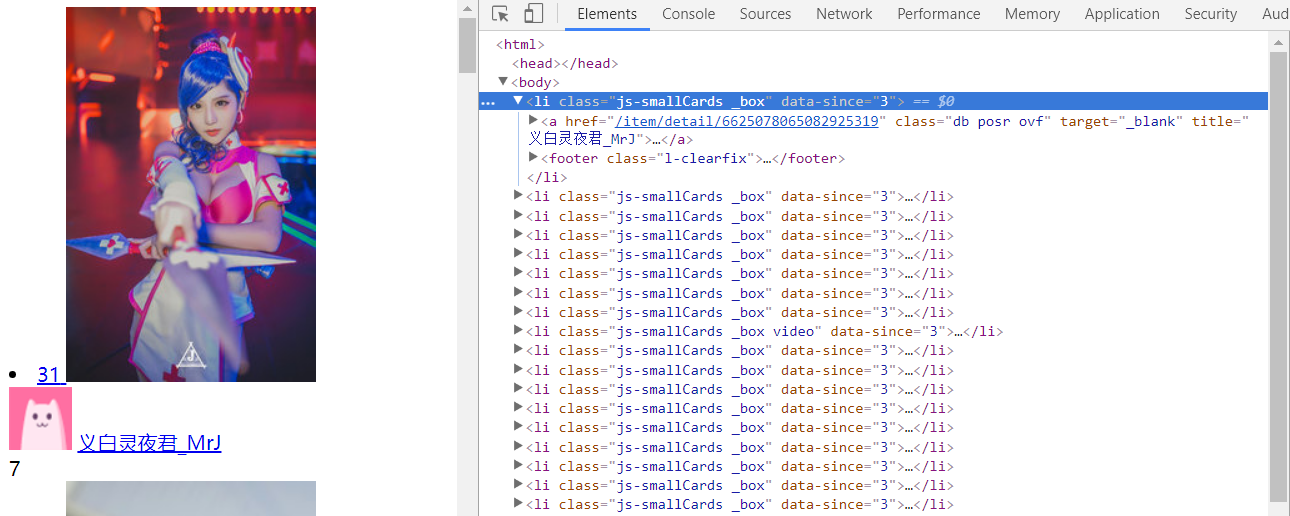
然后查找li的标签中的a标签 提取href
urls = []
for li in all_li:
a = li.find('a')
urls.append(a['href'])
return urls4.4进入页面链接,遍历读取所有图片
一开始还想继续利用soup进行解析,发现python读取页面后并没有找到那些标签,一度再次陷入困境,最后在js文件中发现了想要的数据
我们发现图片路径都是类似的
\"path\":\"https:\\u002F\\u002Fimg-bcy-qn.pstatp.com\\u002Fuser\\u002F2511464\\u002Fitem\\u002Fc0juk\\u002F0ed91266f72b4f73b5f4bfec1c0ebac0.jpg\\u002Fw650\"(这部分中应该有关于编码解码还有路径名的一些东西,但我还不是很熟悉)
我们可以利用re正则表达式模块提取path
设定头部path尾部w650
pattern = re.compile('"path(.*?)w650', re.S)
items = re.findall(pattern, content)对其中的\u002F进行替换,去掉尾部的\w650,得到正确的url
for i in range(len(items)):
items[i] = items[i].replace(r'\\u002F', '/')
items[i] = items[i][5:-1]其他步骤应该就没有什么问题了
4.5建立文件夹分类下载存储图片
获取标题,以标题为名建立文件夹,需要去掉非法的一些符号
soup = BeautifulSoup(content, 'html5lib')
title = soup.title.string
unvalid_str = '<>,\/|,:,"",*,?'
for ch in unvalid_str:
title = title.replace(ch, '')4.6尝试多线程进行爬取提高速度
pool = Pool()
# 一共6组ajax请求
groups = ([x+1 for x in range(6)])
# map()实现多线程下载
pool.map(main, groups)
# 关闭
pool.close()
# 如果主线程阻塞后,让子进程继续运行完成之后,在关闭所有的主进程
pool.join()4.7最终结果展示
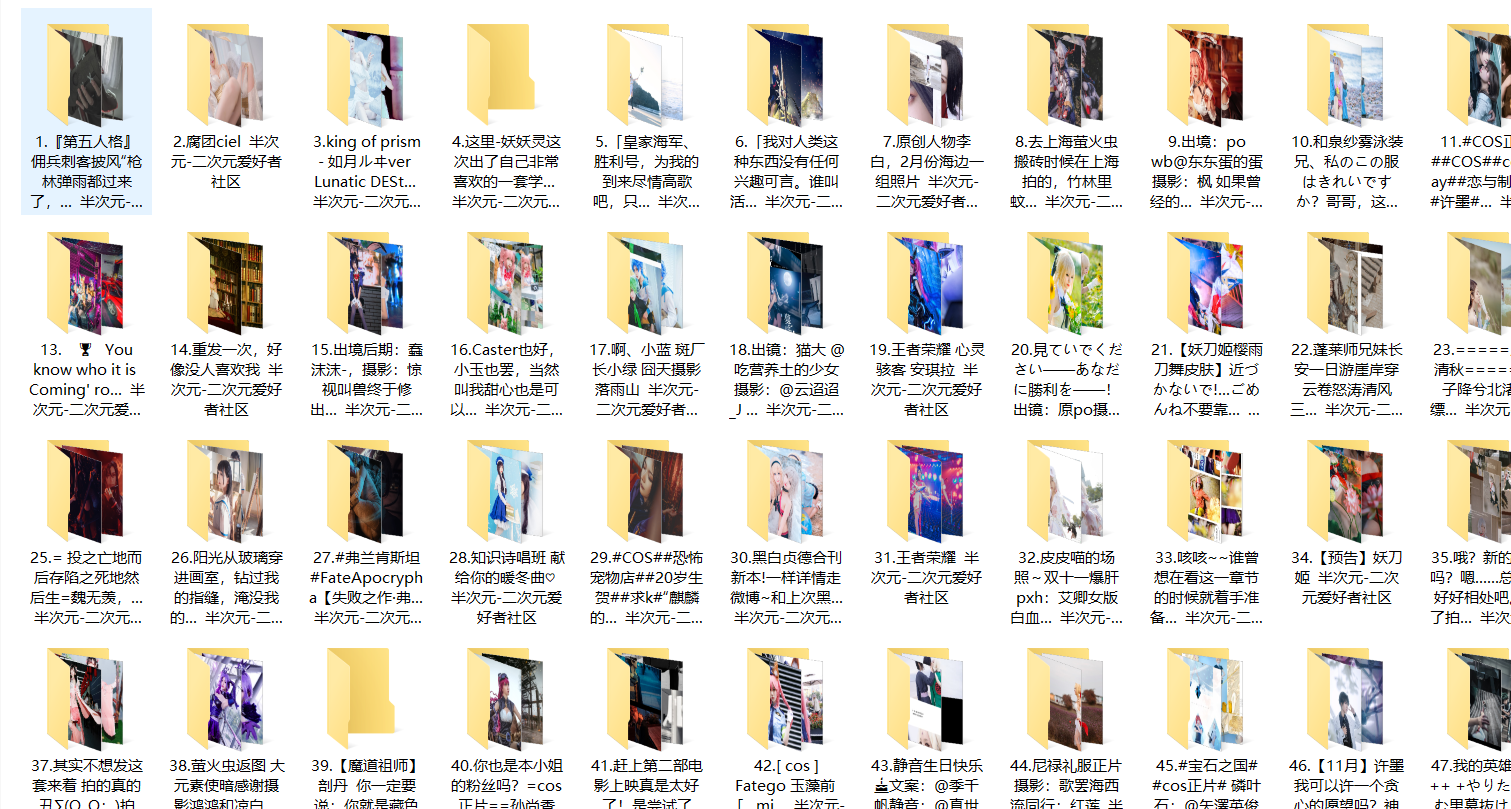
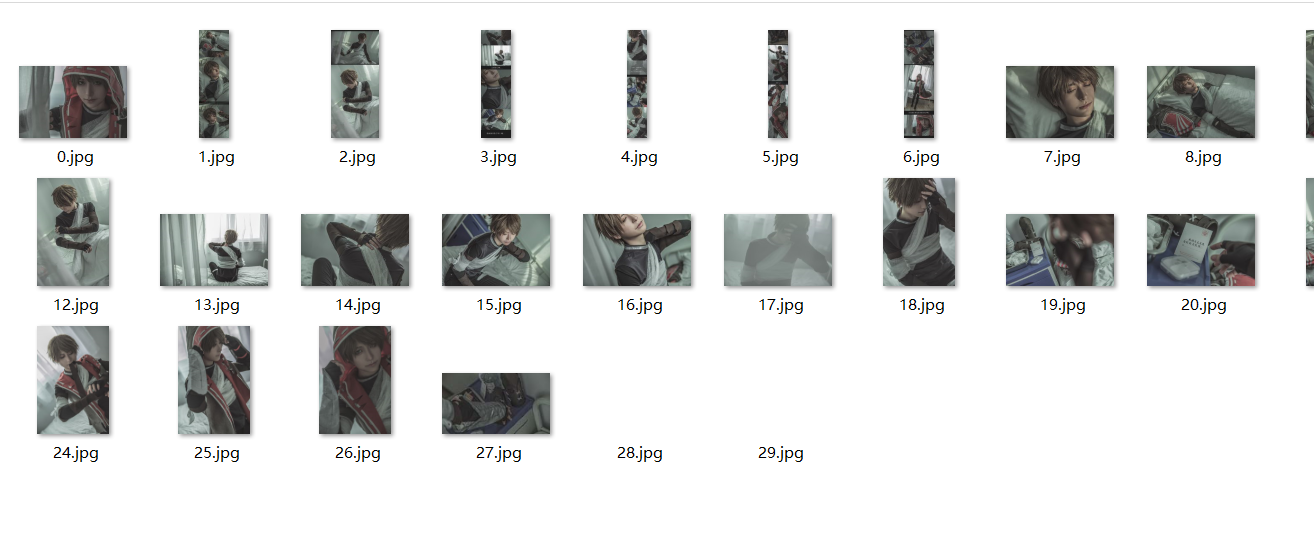

5.Github项目地址
https://github.com/hlcoxndgw/BanciyuanBcyTopCosplaySpider
欢迎大家star
6.总结
- 半次元网站应该没有什么反爬虫的措施,所有在代码也没有进行IP代理或者抓取等待的设置
- COS原图文件还是很大的,爬取TOP100的所有图片应该需要很多的流量(我爬取完成发现文件夹大小是6GB。。。)
- 一些COSer设置了仅对粉丝可见,没有对这种情况进行处理,所有这种情况会得到一个空文件夹
- 网站页面内容随时可能变化,导致代码无法运行,但爬取的原理基本不会变化
- 第一次写博客,可能存在许多问题,有什么不足的地方或者有什么疑问都可以在评论区指出,谢谢大家