AWK 是该编程语言本身的名称,它编写于 1977 年。其名称是三个主要作者的姓的首字母缩写:Drs. A. Aho、P. Weinberger 和 B. Kernighan。
因为 AWK 是一种文本处理和模式匹配语言,所以它通常称为数据驱动的语言,程序语句描述需要进行匹配和处理的输入数据,而不是程序操作步骤的序列,在许多语言中都是这样的。AWK 程序在其输入数据中搜索包含模式的记录、对该记录执行指定的操作,直到程序到达输入的末尾。
AWK 语言是一种 UNIX 备用工具,它是一种功能强大的文本操作和模式匹配语言,特别适用于进行信息检索,这使得它非常适合用于当今的数据库驱动的应用程序。
虽然基本在linux的发行版中都没有默认安装gawk程序,但是我用的腾讯云的机器上是已经安装了,腾讯云默认安装了很多软件。

我还是比较喜欢用ubuntu的,可以使用apt-get install 安装,在mac中可以用 brew install,或者你可以下载了编译安装!
gawk程序让流编辑迈上了一个新的台阶,它 提供了一种编程语言而不只是编辑器命令。常用来从大文本文件中提取数据元素,并将它们格式化成可读的 报告。在gawk编程语言中,你可以做下面的事情:
- 定义变量来保存数据;
- 使用算术和字符串操作符来处理数据;
- 使用结构化编程概念(比如if-then语句和循环)来为数据处理增加处理逻辑;
- 通过提取数据文件中的数据元素,将其重新排列或格式化,生成格式化报告
在上面的截图中,已经展示了gawk的用法,和一些功能参数。

gawk会将如下变量分配给它在文本行中发现的数据字段,$0代表整个文本行;$1代表文本行中的第1个数据字段; $2代表文本行中的第2个数据字段; $n代表文本行中的第n个数据字段。awk中默认的字段分隔符是任意的空白字符。

AWK 程序由规则 组成,它们是一些模式,后面跟着由换行分隔的操作。当 AWK 执行一条规则时,它在输入记录中搜索给定模式的匹配项,然后对这些记录执行给定的操作。
比如我用上次那个文本 testfile
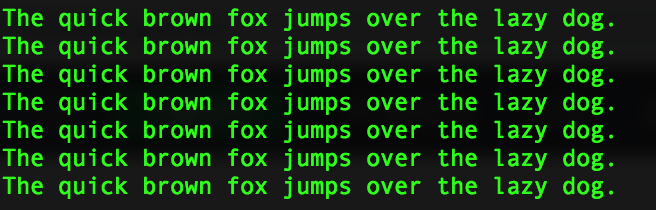
使用gawk '{print $4}' testfile

除了print操作,我们还可以使用其他的操作

如果你对分隔符有特殊的要求,那么你还可以使用 -F后面接分隔符,比如gawk -F: '{print $1}' /etc/passwd
你也可以组合使用命令行,比如echo "My name is Rich" | gawk '{$4="Christine"; print $0}'
第一条命令会给字段变量$4赋值。第二条命令会打印整个数据字段。
gawk可以使用BEGIN在处理数据前或者处理后END执行脚本。

在 GAWK 中,其模式匹配机制类似于 egrep 命令的模式匹配机制。要仅输出那些匹配模式的记录,可以在规则中指定该模式,使用斜杠字符括起来。
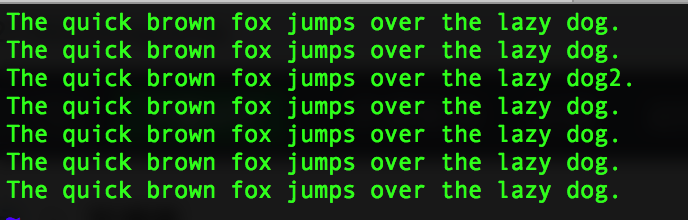
awk '/dog2/ { print }' testfile 去匹配下面的记录
可以写成下面的多个匹配 awk '/dog2/ && /fox/ { print }' testfile
虽然awk和gawk有着强大的功能,但是用的不是很多,暂时就先写这么多吧!
参考:
http://www.runoob.com/linux/linux-comm-awk.html
https://www.cnblogs.com/xudong-bupt/p/3721210.html