AWK是一种解释性编程语言,主要用于文本处理。之所以叫AWK是因为其取了三位创始人Alfred Aho,Peter Weinberger,和Brian Kernighan的Family Name的首字符。
GNU/Linux发布的AWK目前由自由软件基金会(FSF)进行开发和维护,通常也称它为GNU AWK。
AWK的几个变体:(1).AWK:原先来源于AT&T实验室的的AWK;(2).NAWK:AT&T实验室的AWK的升级版;(3).GAWK:这就是GNU AWK;(4).MAWK:快速的AWK实现。
在Ubuntu 14.04上默认安装的是mawk,安装gawk既可以通过源码安装也可以通过命令安装,通过命令安装直接执行:
$ sudo apt-get install gawkAWK遵循了非常简单的工作流:读取,执行和重复,如下图:
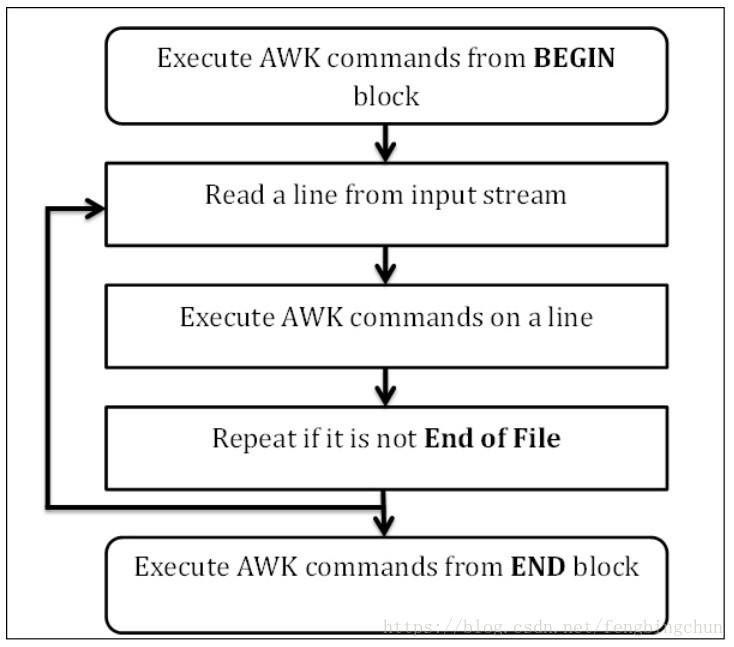
(1). Read:AWK从输入流(文件,管道或者标准输入)中读取一行,然后存储到内存中。
(2). Execute:所有的AWK命令都依次在输入上执行。默认情况下,AWK会对每一行执行命令,我们可以通过提供模式限制这种行为。
(3). Repeat:处理过程不断重复,直到到达文件结尾。
AWK程序结构:
(1). BEGIN语句块:在程序开始时执行,它只执行一次,在这里可以初始化变量.BEGIN是AWK的关键字,因此它必须为大写,注意,这个语句块是可选的。
(2). BODY语句块:此块中的命令会对输入的每一行执行,我们也可以通过提供模式来控制这种行为。注意,BODY语句块没有关键字。
(3). END语句块:在程序的最后执行,END是AWK的关键字,因此必须为大写,它也是可选的。
正则表达式:AWK在处理正则表达式方面是非常强大的。
数组:AWK支持关联数组,也就是说,不仅可以使用数字索引的数组,还可以使用字符串作为索引,而且数字索引也不要求是连续的。数组不需要声明可以直接使用。
流程控制:与大多数语言一样:if; if ... else if ... else
循环操作:与C语言一样,主要包括 for,while,do...while,break,continue语句,还有一个exit语句用于退出脚本执行。
函数:
(1). 内建函数:AWK提供了很多方便的内建函数供编程人员使用:数学函数包括atan2、cos、exp、int、log、rand、sin、sqrt、srand;字符串函数包括:asort、asorti、gsub、index、length、match、split、sprintf、strtonum、sub、substr、tolower、toupper;时间函数包括:systime、mttime、strftime;字节操作函数包括:and、compl、lshift、rshift、or、xor;
其它函数包括:close、delete、exit、fflush、getline、next、nextfile、return、system.
(2). 用户自定义函数:function function_name(argument1, argument2, ...) { function body }
输出重定向:
(1). 与shell中的用法基本一致:>用于将输出写入到指定的文件中,如果文件中有内容则覆盖,而>>则为追加模式写入
(2). 管道:除了将输出重定向到文件之外,我们还可以将输出重定向到其它程序,与shell中一样,我们可以使用管道操作符|。AWK中可以使用|&进行双向连接。
格式化输出:print和printf,printf的用法基本和C语言一致。
执行shell命令:在AWK中执行shell命令有两种方式:使用system函数和使用管道。
以下是测试代码:
marks.txt:
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89marks.sh:
#! /usr/bin/awk
{
print
}functions.awk:
#! /usr/bin/awk
# 自定义函数的使用
# Returns minimum number
function find_min(num1, num2) {
if (num1 < num2)
return num1
return num2
}
# Returns maximum number
function find_max(num1, num2) {
if (num1 > num2)
return num1
return num2
}
# Main function
function main(num1, num2) {
# Find minimum number
result = find_min(10, 20)
print "Minimum =", result
# Find maximum number
result = find_max(10, 20)
print "Maximum =", result
}
# Script execution starts here
BEGIN {
main(10, 20)
}marks.sh:
#! /bin/bash
echo "我们可以直接在命令行中执行AWK的命令,也可以从包含AWK命令的文本文件中执行:"
echo "(1). 我们可以使用单引号在命令行中指定AWK命令,注意,其只能被单引号包含,如显示marks.txt文件的完整内容,则执行:"
awk '{print}' marks.txt
echo "(2). 我们也可以使用脚本文件提供AWK命令,如显示marks.txt文件的完整内容,则执行:"
awk -f marks.awk marks.txt
echo; echo "AWK标准选项:"
echo "(1). -v: 该选项将一个值赋予一个变量,它会在程序开始之前进行赋值,例如:"
awk -v name=Jerry 'BEGIN{printf "Name = %s\n", name}'
echo "(2). --dump-variable: 该选项会输出排好序的全局变量列表和它们最终的值到文件中,默认的文件是awkvars.out,执行:"
awk --dump-variables ''; cat awkvars.out
echo "(3). --help: 打印帮助信息,执行:"
awk --help
echo "(4). --lint: 该选项允许检查程序的不兼容性或者模棱两可的代码,当提供参数 fatal的时候,它会对待Warning消息作为Error,如执行:"
#awk --lint '' /bin/ls; awk --lint 'fatal' /bin/ls
echo "(5). --posix: 该选项开启严格的POSIX兼容."
echo "(6). --profile: 该选项会输出一份格式化之后的程序到文件中,默认文件是 awkprof.out,如执行:"
awk --profile 'BEGIN { printf"---|Header|--\n" } { print } END { printf"---|Footer|---\n" }' marks.txt > /dev/null; cat awkprof.out
echo "(7). --traditional: 该选项会禁止所有的gawk规范的扩展."
echo "(8). --version: 输出版本号,执行:"
awk --version
echo; echo "内建变量:"
echo "(1). ARGC: 命令行参数个数,如执行:"
awk 'BEGIN {print "Arguments =", ARGC}' One Two Three Four
echo "(2). ARGV: 命令行参数数组,,索引范围从0至(ARGC-1),如执行:"
awk 'BEGIN {for (i = 0; i < ARGC; ++i) { printf "ARGV[%d] = %s\n", i, ARGV[i] }}' one two three four
echo "(3). CONVFMT: 代表了数字的约定格式,默认值是%.6g,执行:"
awk 'BEGIN { print "Conversion Format =", CONVFMT }'
echo "(4). ENVIRON: 环境变量的关联数组,如执行:"
awk 'BEGIN { print ENVIRON["USER"] }'
echo "(5). FILENAME: 当前文件名,如执行:"
awk 'END {print FILENAME}' marks.txt
echo "(6). FS: 代表了输入字段的分隔符,默认值为空格,可以通过-F选项在命令行选项中修改它,如执行:"
awk 'BEGIN {print "FS = " FS}' | cat -vte; awk -F , 'BEGIN {print "FS = " FS}' | cat -vte
echo "(7). NF: 代表了当前行中的字段数目,例如下面例子打印出了包含大于两个字段的行,执行:"
echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NF > 2'
echo "(8). NR: 行号,如执行:"
echo -e "One Two\nOne Two Three\nOne Two Three Four" | awk 'NR < 3'
echo "(9). FNR: 与NR相似,不过在处理多文件时更有用,获取的行号相对于当前文件."
echo "(10). OFMT: 输出格式数字,默认值为%.6g,执行:"
awk 'BEGIN {print "OFMT = " OFMT}'
echo "(11). OFS: 输出字段分隔符,默认为空格,执行:"
awk 'BEGIN {print "OFS = " OFS}' | cat -vte
echo "(12). ORS: 输出行分隔符,默认值为换行符,执行:"
awk 'BEGIN {print "ORS = " ORS}' | cat -vte
echo "(13). RLENGTH: 代表了match函数匹配的字符串长度,如执行:"
awk 'BEGIN { if (match("One Two Three", "re")) { print RLENGTH } }'
echo "(14). RS: 输入记录分隔符,默认值为换行符,如执行:"
awk 'BEGIN {print "RS = " RS}' | cat -vte
echo "(15). RSTART: match函数匹配的第一次出现位置,如执行:"
awk 'BEGIN { if (match("One Two Three", "Thre")) { print RSTART } }'
echo "(16). SUBSEP: 数组子脚本的分隔符,默认为^\,如执行:"
awk 'BEGIN { print "SUBSEP = " SUBSEP }' | cat -vte
echo "(17). $0: 代表了当前行,如执行:"
awk '{print $0}' marks.txt
echo "(18). $n: 当前行中的第n个字段,字段间由FS分隔,如执行:"
awk '{print $3 "\t" $4}' marks.txt
echo; echo "GNU AWK的变量:"
echo "(1). ARGIND: 当前被处理的ARGV的索引"
echo "(2). BINMODE: 在非POSIX系统上指定对所有的文件I/O采用二进制模式"
echo "(3). ERRNO: 一个代表了getline跳转失败或者是close调用失败的错误的字符串,如执行:"
awk 'BEGIN { ret = getline < "junk.txt"; if (ret == -1) print "Error:", ERRNO }'
echo "(4). FIELDWIDTHS: 设置了空格分隔的字段宽度变量列表的话,GAWK会将输入解析为固定宽度的字段,而不是使用FS进行分隔"
echo "(5). IGNORECASE: 设置了这个变量的话,AWK会忽略大小写,如执行:"
awk 'BEGIN {IGNORECASE = 1} /amit/' marks.txt
echo "(6). LINT: 提供了对"--lint"选项的动态控制,如执行:"
awk 'BEGIN {LINT = 1; a}'
echo "(7). PROCINFO: 包含进程信息的关联数组,例如UID,进程ID等,如执行:"
awk 'BEGIN { print PROCINFO["pid"] }'
echo "(8). TEXTDOMAIN代表了AWK的文本域,用于查找字符串的本地化翻译,如执行:"
awk 'BEGIN { print TEXTDOMAIN }'
echo; echo "显示marks.txt文件内容,并且添加每一列的标题:"
awk 'BEGIN {printf "Sr No\tName\tSub\tMarks\n"} {print}' marks.txt
echo; echo "打印marks.txt文件中的第3列和第4列,\$3和\$4代表输入记录中的第三个和第四个字段:"
awk '{print $3 "\t" $4}' marks.txt
echo; echo "判断每一行中是否包含a,如果包含则打印该行,如果BODY部分缺失则默认会执行打印,因此和以下命令等价:$ awk '/a' marks.txt :"
awk '/a/ {print $0}' marks.txt
echo; echo "仅打印第3列和第4列中包含a的列:"
awk '/a/ {print $3 "\t" $4}' marks.txt
echo; echo "任意顺序打印列:"
awk '/a/ {print $4 "\t" $3}' marks.txt
echo; echo "统计匹配模式的行数:"
awk '/a/{++cnt} END {print "Count = ", cnt}' marks.txt
echo; echo "打印超过18个字符的行:"
awk 'length($0) > 18' marks.txt
echo -e "支持的操作符:"
echo -e "\n算数操作符: a = 50, b = 20"
awk 'BEGIN { a = 50; b = 20; print "(a + b) = ", (a + b) }'
awk 'BEGIN { a = 50; b = 20; print "(a - b) = ", (a - b) }'
awk 'BEGIN { a = 50; b = 20; print "(a * b) = ", (a * b) }'
awk 'BEGIN { a = 50; b = 20; print "(a / b) = ", (a / b) }'
awk 'BEGIN { a = 50; b = 20; print "(a % b) = ", (a % b) }'
echo -e "\n增减运算符: a = 10"
awk 'BEGIN { a = 10; b = ++a; printf "a = %d, b = %d\n", a, b }'
awk 'BEGIN { a = 10; b = --a; printf "a = %d, b = %d\n", a, b }'
awk 'BEGIN { a = 10; b = a++; printf "a = %d, b = %d\n", a, b }'
awk 'BEGIN { a = 10; b = a--; printf "a = %d, b = %d\n", a, b }'
echo -e "\n赋值操作符:"
awk 'BEGIN { name = "Jerry"; print "My name is", name }'
awk 'BEGIN { cnt = 10; cnt += 10; print "Counter =", cnt }'
awk 'BEGIN { cnt = 100; cnt -= 10; print "Counter =", cnt }'
awk 'BEGIN { cnt = 10; cnt *= 10; print "Counter =", cnt }'
awk 'BEGIN { cnt = 100; cnt /= 5; print "Counter =", cnt }'
awk 'BEGIN { cnt = 100; cnt %= 8; print "Counter =", cnt }'
awk 'BEGIN { cnt = 2; cnt ^= 4; print "Counter =", cnt }'
awk 'BEGIN { cnt = 2; cnt **= 4; print "Counter =", cnt }'
echo -e "\n关系操作符:"
awk 'BEGIN { a = 10; b = 10; if (a == b) print "a == b" }'
awk 'BEGIN { a = 10; b = 20; if (a != b) print "a != b" }'
awk 'BEGIN { a = 10; b = 20; if (a < b) print "a < b" }'
awk 'BEGIN { a = 10; b = 10; if (a <= b) print "a <= b" }'
awk 'BEGIN { a = 10; b = 20; if (b > a ) print "b > a" }'
echo -e "\n逻辑操作符:"
awk 'BEGIN { num = 5; if (num >= 0 && num <= 7) printf "%d is in octal format\n", num }'
awk 'BEGIN { ch = "\n"; if (ch == " " || ch == "\t" || ch == "\n") print "Current character is whitespace." }'
awk 'BEGIN { name = ""; if (! length(name)) print "name is empty string." }'
echo -e "\n三元操作符:"
awk 'BEGIN { a = 10; b = 20; (a > b) ? max = a : max = b; print "Max =", max }'
echo -e "\n一元操作符:"
awk 'BEGIN { a = -10; a = +a; print "a =", a }'
awk 'BEGIN { a = -10; a = -a; print "a =", a }'
echo -e "\n指数操作符:"
awk 'BEGIN { a = 10; a = a ^ 2; print "a =", a }'
awk 'BEGIN { a = 10; a ^= 2; print "a =", a }'
echo -e "\n字符串连接操作符:"
awk 'BEGIN { str1 = "Hello, "; str2 = "World"; str3 = str1 str2; print str3 }'
echo -e "\n数组成员操作符:"
awk 'BEGIN { arr[0] = 1; arr[1] = 2; arr[2] = 3; for (i in arr) printf "arr[%d] = %d\n", i, arr[i] }'
echo -e "\n正则表达式操作符用~和!~分别代表匹配和不匹配:"
awk '$0 ~ 9' marks.txt
awk '$0 !~ 9' marks.txt
echo -e "\n正则表达式:AWK在处理正则表达式方面是非常强大的:"
echo -e "cat\nbat\nfun\nfin\nfan" | awk '/f.n/'
echo -e "This\nThat\nThere\nTheir\nthese" | awk '/^The/'
echo -e "knife\nknow\nfun\nfin\nfan\nnine" | awk '/n$/'
echo -e "Call\nTall\nBall" | awk '/[CT]all/'
echo -e "Call\nTall\nBall" | awk '/[^CT]all/'
echo -e "Call\nTall\nBall\nSmall\nShall" | awk '/Call|Ball/'
echo -e "Colour\nColor" | awk '/Colou?r/'
echo -e "ca\ncat\ncatt" | awk '/cat*/'
echo -e "111\n22\n123\n234\n456\n222" | awk '/2+/'
echo -e "Apple Juice\nApple Pie\nApple Tart\nApple Cake" | awk '/Apple (Juice|Cake)/'
echo -e "\n数组:AWK支持关联数组,也就是说,不仅可以使用数字索引的数组,还可以使用字符串作为索引,而且数字索引也不要求是连续的.数组不需要声明可以直接使用."
echo "创建数组的方式非常简单,直接为变量赋值即可:"
awk 'BEGIN { fruits["mango"] = "yellow"; fruits["orange"] = "orange"; print fruits["orange"] "\n" fruits["mango"] }'
echo "删除数组元素使用delete语句:"
awk 'BEGIN { fruits["mango"] = "yellow"; fruits["orange"] = "orange"; delete fruits["orange"]; print fruits["orange"] }'
echo -e "在AWK中,只支持一维数组,但是可以通过一维数组模拟多维,例如我们有一个3x3的三维数组\n100 200 300\n400 500 600\n700 800 900"
awk 'BEGIN {
array["0,0"] = 100;
array["0,1"] = 200;
array["0,2"] = 300;
array["1,0"] = 400;
array["1,1"] = 500;
array["1,2"] = 600;
# print array elements
print "array[0,0] = " array["0,0"];
print "array[0,1] = " array["0,1"];
print "array[0,2] = " array["0,2"];
print "array[1,0] = " array["1,0"];
print "array[1,1] = " array["1,1"];
print "array[1,2] = " array["1,2"];
}'
echo -e "\n流程控制:与大多数语言一样:"
awk 'BEGIN {
num = 11;
if (num % 2 == 0) printf "%d is even number.\n", num;
else printf "%d is odd number.\n", num
}'
awk 'BEGIN {
a = 30;
if (a==10) print "a = 10";
else if (a == 20) print "a = 20";
else if (a == 30) print "a = 30";
}'
echo -e "\n循环操作:与C语言一样,主要包括 for,while,do...while,break,continue语句,还有一个exit语句用于退出脚本执行:"
awk 'BEGIN { for (i = 1; i <= 5; ++i) print i }'
awk 'BEGIN {i = 1; while (i < 6) { print i; ++i } }'
awk 'BEGIN {i = 1; do { print i; ++i } while (i < 6) }'
awk 'BEGIN {
sum = 0;
for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) break; else print "Sum =", sum
}
}'
awk 'BEGIN {
for (i = 1; i <= 20; ++i) {
if (i % 2 == 0) print i ; else continue
}
}'
awk 'BEGIN {
sum = 0;
for (i = 0; i < 20; ++i) {
sum += i; if (sum > 50) exit(10); else print "Sum =", sum
}
}'
# 自定义函数的调用
awk -f functions.awk以上内容主要摘自: