从一个大体思路角度记录一下学习的过程。细节不写在这里。
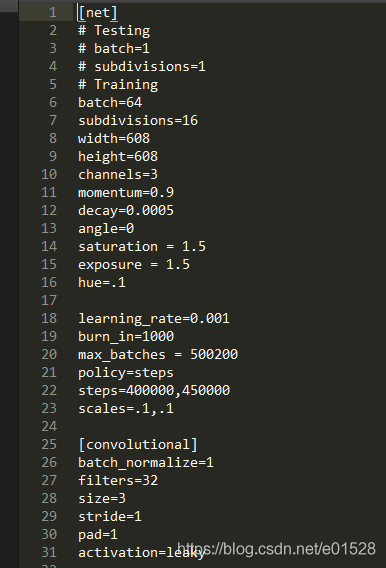
输入文件:只需要一个cfg文件即可。
整体思路:先为网络定义一个Darknet类,然后里面肯定有init,foward函数,这里还有load_weight函数,在init初始化的时候,需要将利用cfg构建一个网络框架。具体关系在forward函数中。
更详细的说法:
1. 转换输入:根据cfg文件,先把每个block单独存储(作为字典),放到blocks(列表)当中。
2. 根据blocks中的block字典信息可以创建module(nn.Sequential()),放到module_list(nn.moduleList)当中。其中涉及到不认识的层,route、shortcut和yolo层无法确定分给哪一个,我们先创建新的层,初始化在新层的init里面,但不在新层类的forward函数。具体操作,再说。(其实是放到了实现最后一步的darknet类的forward当中)【其实还不直接写到最初的forward里面,这样调用简单】
为网络定义一个Darknet类
class Darknet(nn.Module):
def __init__(self, cfgfile):
super(Darknet, self).__init__() # 初试化self,先调用他的父类 nn.Module的init
self.blocks = parse_cfg(cfgfile) # 存入blocks字典,调用blocks[i]["type"]
self.net_info, self.module_list = create_modules(self.blocks) # 根据type,构建框架
def forward(self, x, CUDA):
...
return detections
def load_weights(self, weightfile):
"""
# 从下载的weight当中取出来,原本是1行,然后view_as 成 bn.里面的维度
# 最后copy_到 bn.bias.data等 参与训练
"""
...一、在init的时候,需要利用cfg构建网络框架。需要创建两个函数parse_cfg(cfgfile) 和 create_modules(self.blocks)
首先选用了cfg.txt,利用def parse_cfg(cfgfile):返回blocks。blocks _>[[{},{}...{}][{},{}...{}]...]]里面每个dict存储了每个的类别即block["type"],以及其他的关键字key,value = line.split("=") 最后blocks.append(block),然后def create_modules(blocks): return (net_info, module_list)运用torch模块构造模型架构。
def parse_cfg(cfgfile):
...
block = {}
blocks = []
for line in lines:
if line[0] == "[":
if len(block) != 0: #
blocks.append(block) #
block = {} #
block["type"] = line[1:-1].rstrip()
else:
key,value = line.split("=")
block[key.rstrip()] = value.lstrip()
blocks.append(block)二 、 再定义forward函数: def forward(self, x, CUDA):
值得学习的有:
一、在init里的create_module构架框架的时候。
module_list的应用,这一点在另外一篇博客里有写。nn.moduleList 和Sequential由来、用法和实例 —— 写网络模型。在循环前 module_list = nn.ModuleList(),构造blocks的循环 for index, x in enumerate(blocks[1:]):,里面写model=nn.Sequential()然后判断是哪一种层,再module.add_module("conv_{0}".format(index), conv)添加进来,每次循环末尾,利用moduleList的方法module_list.append(module),然后循环。
在循环前还需要的是(也是构造模型值得学习的地方)需要定义输入和输出的filters,因为conv等层需要。总结为:看不同module的参数的需要。
# 循环前需要定义
module_list = nn.ModuleList() #大module列表
prev_filters = 3 #每一层输入的filter
output_filters = [] #每一个层的输出的filter
# 开始循环,不断创造module,然后add_module进去,在append到module_list中
for index, x in enumerate(blocks[1:]):
...
module = nn.Sequential() #不断创造新的module
if (x["type"] == "convolutional"):
filters= int(x["filters"]) #本层输出的filter
conv = nn.Conv2d(prev_filters, filters, kernel_size, stride, pad, bias = bias)
module.add_module("conv_{0}".format(index), conv) #
module_list.append(module) #列表存储所有module
prev_filters = filters #将下一层的输入的filter 替换为 上一层的输出的filter,
output_filters.append(filters) #存储这一层的输出,route等层需要二、是route层和yolo层以及shortcut层,如何根据nn.module新建这些层呢?
首先对于route和shortcut层只是对不同的层之间进行连接操作。所以不需要新的参数输入。
class EmptyLayer(nn.Module):
def __init__(self):
super(EmptyLayer, self).__init__()但是yolo层用于predict每个anchor的概率涉及到了anchor。还是总结为看参数,输入输出。
所以yolo'层 def __init__(self, anchors):
class DetectionLayer(nn.Module):
def __init__(self, anchors):
super(DetectionLayer, self).__init__()
self.anchors = anchors具体的实现放在forward当中。通过迭代blocks(blocks是一个列表,里面放着每一个block的字典)取出block字典,判断如果是route需要对输入的特征图x进行什么操作,然后保存i层输入到output[i]。
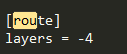
首先分析route层,两种情况,一种是跳到倒数4层,对它进行操作; x = outputs[i -4]
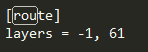
一种是对倒数1层和第61层进行合并操作,torch.cat((outputs[i -1],outputs[i + 61]),1) #nchw合并channel
其次shortcut比较简单,就是纯粹的一个把上一层和某一层相加 : x = outputs[i-1] + outputs[i+from_] #相加就好
最后是yolo层,比较复杂单开一个。
下面是forward的全部。
def forward(self, x, CUDA):
modules = self.blocks[1:]
outputs = {} #We cache the outputs for the route layer
write = 0
for i, module in enumerate(modules):
module_type = (module["type"])
if module_type == "convolutional" or module_type == "upsample":
x = self.module_list[i](x)
elif module_type == "route":
layers = module["layers"]
layers = [int(a) for a in layers]
if (layers[0]) > 0:
layers[0] = layers[0] - i
if len(layers) == 1:
x = outputs[i + (layers[0])]
else:
if (layers[1]) > 0:
layers[1] = layers[1] - i
map1 = outputs[i + layers[0]]
map2 = outputs[i + layers[1]]
x = torch.cat((map1, map2), 1)
elif module_type == "shortcut":
from_ = int(module["from"])
x = outputs[i-1] + outputs[i+from_]
elif module_type == 'yolo':
anchors = self.module_list[i][0].anchors
#Get the input dimensions
inp_dim = int (self.net_info["height"])
#Get the number of classes
num_classes = int (module["classes"])
#Transform
x = x.data
#将x由 n c w h _> n w*h*3 c
#batch_size, 3*85, grid_size, grid_size)——》(batch_size, grid_size*grid_size*3, 5+类别数量)
#在这个过程当中趁机 利用sigmod 将xywh改过来,因为需要xc和sigmod函数,回归嚒
x = predict_transform(x, inp_dim, anchors, num_classes, CUDA)
if not write: #if no collector has been intialised.
detections = x
write = 1
else:
detections = torch.cat((detections, x), 1)
outputs[i] = x
return detections