首先,kafka是什么:
kafka 是一个分布式消息队列系统,用于大数据分析,其中主要是日志分析系统:
然后思考一下以下几个场景:
-
我想分析一下用户行为(pageviews),以便我能设计出更好的广告位
-
我想对用户的搜索关键词进行统计,分析出当前的流行趋势。这个很有意思,在经济学上有个长裙理论,就是说,如果长裙的销量高了,说明经济不景气了,因为姑娘们没钱买各种丝袜了。
-
有些数据,我觉得存数据库浪费,直接存硬盘又怕到时候操作效率低。
这个时候,我们就可以用到分布式消息系统了。虽然上面的描述更偏向于一个日志系统,但确实kafka在实际应用中被大量的用于日志系统。
这些场景都有一个共同点:数据是由上游模块产生,上游模块,使用上游模块的数据计算、统计、分析,这个时候就可以使用消息系统,尤其是分布式消息系统!
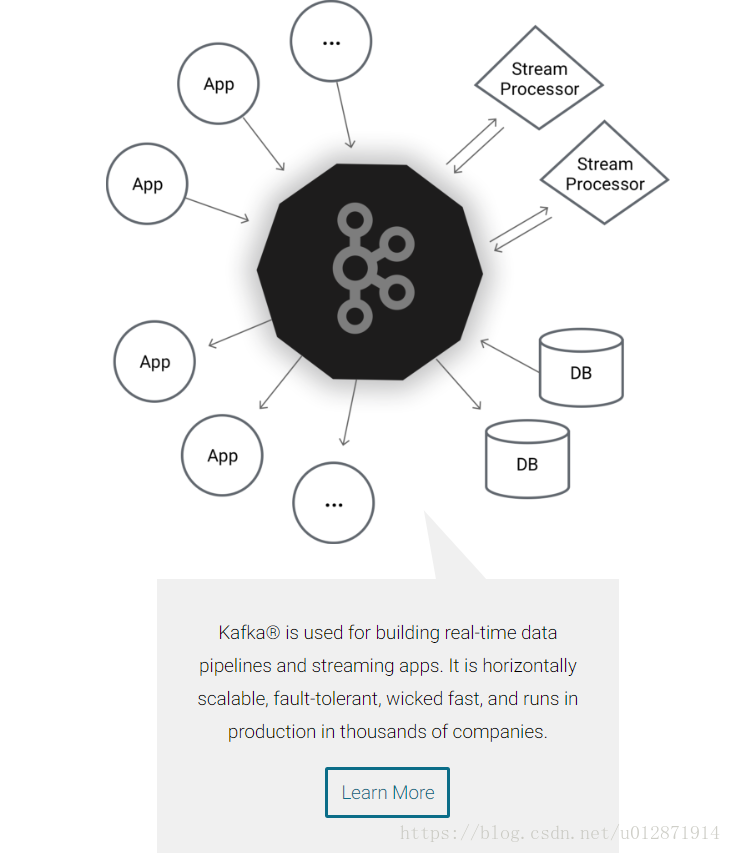
二. 基本概念
1、 AMQP协议(Advanced Message Queuing Protocol,高级消息队列协议)
AMQP是一个标准开放的应用层的消息中间件(Message Oriented Middleware)协议。AMQP定义了通过网络发送的字节流的数据格式。因此兼容性非常好,任何实现AMQP协议的程序都可以和与AMQP协议兼容的其他程序交互,可以很容易做到跨语言,跨平台。
2、 一些基本的概念
-
消费者:(Consumer):从消息队列中请求消息的客户端应用程序
-
生产者:(Producer) :向broker发布消息的应用程序
-
AMQP服务端(broker):用来接收生产者发送的消息并将这些消息路由给服务器中的队列,便于fafka将生产者发送的消息,动态的添加到磁盘并给每一条消息一个偏移量,所以对于kafka一个broker就是一个应用程序的实例
-
主题(Topic):一个主题类似新闻中的体育、娱乐、教育等分类概念,在实际工程中通常一个业务一个主题。
-
分区(Partition):一个Topic中的消息数据按照多个分区组织,分区是kafka消息队列组织的最小单位,一个分区可以看作是一个FIFO( First Input First Output的缩写,先入先出队列)的队列。
生产者生产(push)消息、kafka集群、消费者获取(pull)消息这样一种架构,kafka集群中的消息,是通过Topic(主题)来进行组织的. 生产者可以选择自己喜欢的序列化方法对消息内容编码。
kafka分区是提高kafka性能的关键所在,当你发现你的集群性能不高时,常用手段就是增加Topic的分区,分区里面的消息是按照从新到老的顺序进行组织,消费者从队列头订阅消息,生产者从队列尾添加消息。
Kafka has four core APIs:
kafka有四个核心的API:
- The Producer API allows an application to publish a stream of records to one or more Kafka topics(生产者api:允许一个应用将流记录发布个一个或多个topic).
- The Consumer API allows an application to subscribe to one or more topics and process the stream of records produced to them(消费者api:允许一个应用订阅一个或者多个topic并且处理塔门生产的流记录数据).
- The Streams API allows an application to act as a stream processor, consuming an input stream from one or more topics and producing an output stream to one or more output topics, effectively transforming the input streams to output streams(流API:允许一个应用作为流处理器,处理输入数据并且将输出数据流输出至多个topic,高效的).
- The Connector API allows building and running reusable producers or consumers that connect Kafka topics to existing applications or data systems. For example, a connector to a relational database might capture every change to a table(允许刚建立或正在执行的可重复使用的生产者和消费者来连接多个topics).
Kafka 作为消息系统的优点:
传统消息系统有两种实现方式:queuing(队列方式)和 Publish–subscribe(发布订阅方式)
前者优点是易于扩展,缺点是无法实现多个订阅者(每个进程取完消息,消息就没有了)
后者优点是可以实现多个订阅者,缺点是不易于扩展(需要将每条消息广播给每个订阅者)
而Kafka的 consumer group 概念结合了这两种设计思想,通过将多个consumer分组,在组内采用队列方式处理消息,对于不同的组采用发布订阅方式,发布至所有的组。
除了作为消息系统使用外,Kafka还可以作为分布式存储系统,以及流处理系统来使用(Streaming API)