参考:https://jingyan.baidu.com/article/219f4bf788addfde442d38fe.html
1、下载图形识别工具Tesseract-ocr,下载路径https://github.com/UB-Mannheim/tesseract/wiki,选择相应的版本进行安装。
2、下载完成后,进行安装,安装时可以根据自己的需求选择安装,可以直接全选。

3、安装完后配置环境变量,将安装路径配置到path中:D:\Program Files (x86)\Tesseract-OCR,然后添加一个系统变量:变量名TESSDATA_PREFIX,变量值D:\Program Files (x86)\Tesseract-OCR\tessdata。

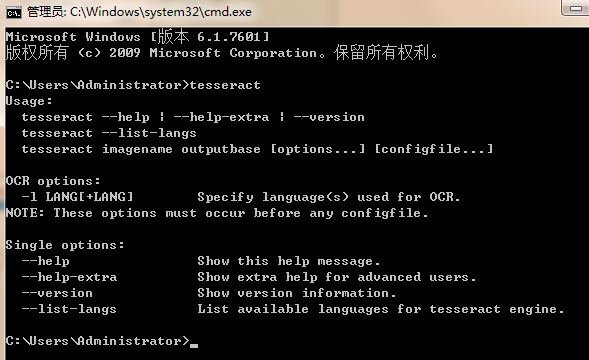
4、配置完环境变量中,在命令行输入tesseract进行检验,如图所示就安装配置成功了。
5、初步使用tesseract,在命令行中进入到指定图片路径,如下图的图片。

然后在命令行中输入命令tesseract 1.jpg t1-l chi_sim+equ+eng,输入命令行后,在该路径下会生成识别图片后的文件(1.jpg是当前目录中的1.jpg图片,t1是指定结果输出到文本文件,-l是指定使用的包,chi_sim是中文识别包,equ是数学公式包,eng是英文包),如图:

图片文字识别虽然有些不正确,但是识别正确率还是挺高的。平常想要识别图片中的文字,可以直接用这个工具,不错哦!