1,百度搜索Tesseract-OCR下载 Tesseract-orc-setup-3.02.02.exe 。要记得自己的安装目录(博主的安装路径为:C:\Program Files(x86)\Tesseract-OCR),等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包 其他语言各版本的识别包下载 ,如简体字识别包对应的是chi_sim.traineddata ,繁体字识别包对应的是chi_tra.traineddata 。
还有其他的安装包下载地址:
稳定版:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-3.05.01.exe
开发版:https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
2,我安装的是开发版
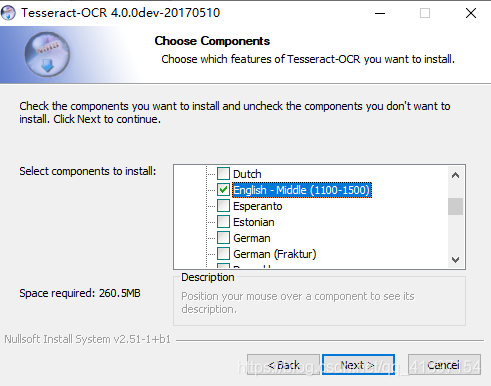
这里可以展开选择自己喜欢的语言包,由于我处理的是旧报纸系列,所以繁体字、简体字最好都有,顺便把英文的也留下叭
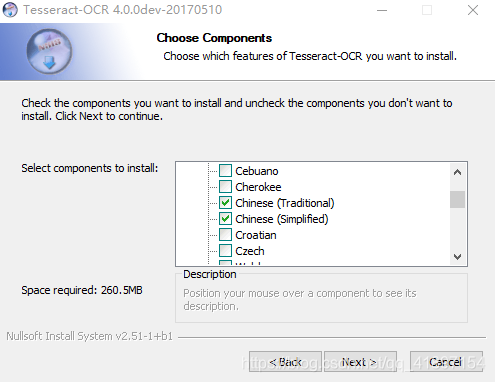
选择安装位置

开始菜单名称(目前不知道是用来干嘛的)
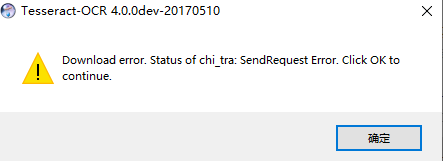
报错了,如下
解决方法
https://blog.csdn.net/qq_41897154/article/details/109499741
发现一个大佬的建议,先留着地址https://github.com/PaddlePaddle/PaddleOCR
看到一个字库制作的,感觉有点厉害