Eclipse配置hadoop开发环境
1. 下载 hadoop-eclipse-plugin-2.6.0.jar
https://github.com/winghc/hadoop2x-eclipse-plugin/tree/v2.6.0
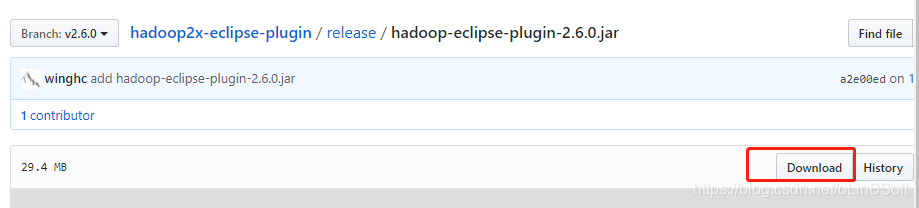
2. 复制下载的 hadoop-eclipse-plugin-2.6.0.jar文件到 eclipse的plugins目录
3.重启eclipse
点击新建-》项目,可以看见Map/Reduce Project
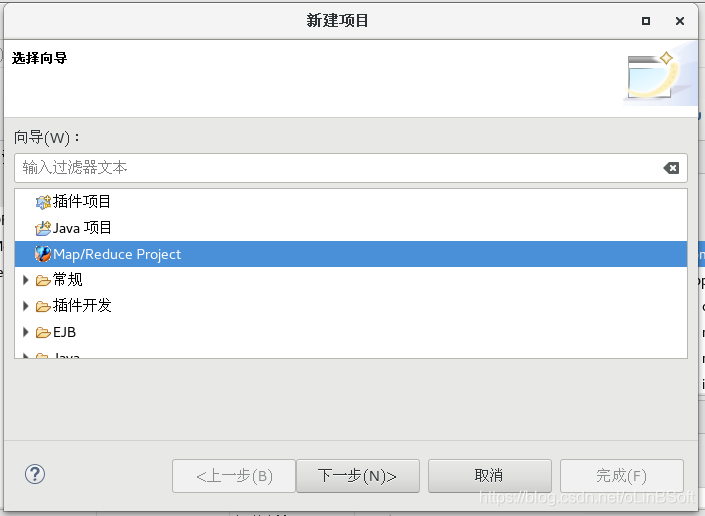
4. 创建Map/Reduce Project项目测试
新建一个 wordcount项目,再新建一个WorkCount类,直接复制hadoop安装带的example的workcount源码
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}5. 导出jar文件
直接点击“文件-》导出”
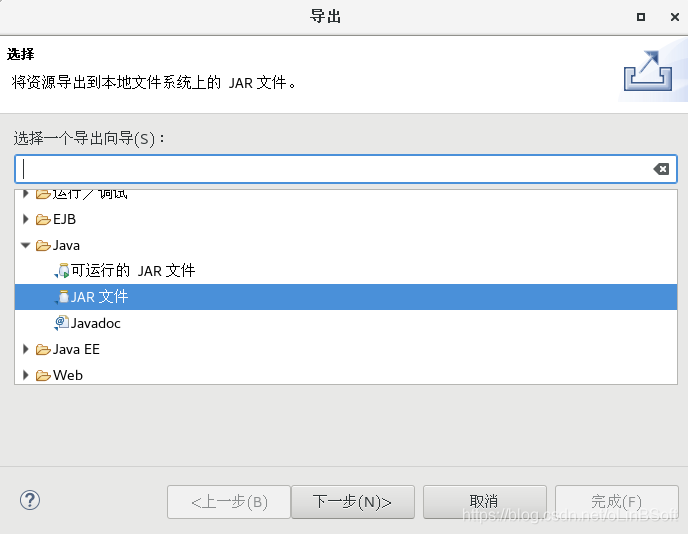
导出WordCount.jar
6.执行测试
hadoop fs -put hello.txt /user/root //上传测试需统计单词的文件
hadoop jar WordCount.jar WordCount /user/root/hello.txt /user/root/wcout //执行测试单词统计作业
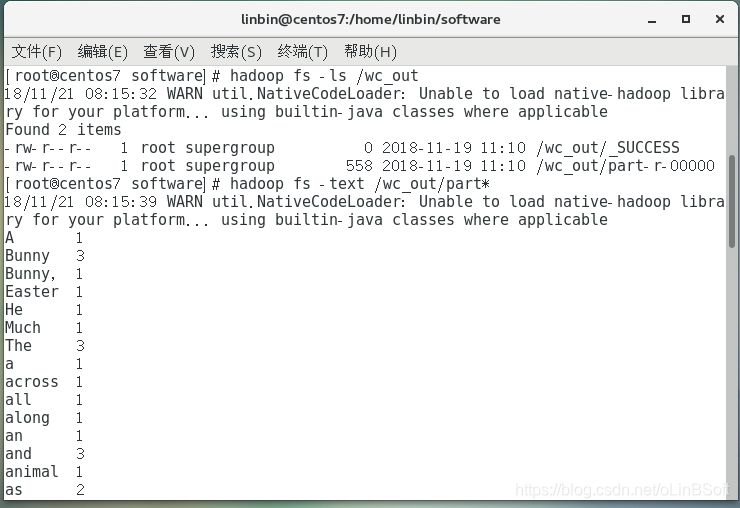
hadoop fs -ls /user/root/wcount //查看输出结果目录
hadoop fs -text /user/root/wcount/part* // 查看统计果
也可以通过 http://centos7:8088/cluster/apps 查看作业调度执行信息
接下来可以参考wordcount设计自己的统计作业程序