这篇文章是本人刚开始学习hadoop大数据技术的操作步骤,很详细,适合入门的初学者:
这2天,先是在windows上装了个虚拟机,在虚拟机里centos下,用docker搭建了一个hadoop大数据开发环境(详见上篇博客),但是用eclipse远程连接过去时,不知道怎么连到docker里面去;所以又在windows下搭建了个hadoop开发环境,中间遇到了些问题,花费了很多时间,现在把经验记录在这里,供入门者参考。
流程:直接解压官网下载hadoop安装包到本地->最小化配置4个基本文件->执行1条启动命令->启动成功。
1、解压hadoop:出来一个目录,例如:D:\hadoop-2.7.2;
2、新建环境变量到HADOOP_HOME中,值为解压的那个目录,在PATH里加上%HADOOP_HOME%\bin;如下图:
![]()

3、下载hadoop在windows上运行需要winutils支持和hadoop.dll等文件,直接解压后把文件丢到D:\hadoop-2.7.2\bin目录中去,将其中的hadoop.dll在c:/windows/System32下也丢一份;如下图:

4、去D:\hadoop-2.7.2\etc\hadoop找到下面4个文件并按如下最小配置粘贴上去:
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>hdfs-site.xml ,格式化namedode时会自动生成这些文件路径,file:/hadoop/data/dfs/namenode,会在hadoop安装目录的根目录下生成这些文件路径, (备注:replication 是数据副本数量,默认为3,salve少于3台就会报错)

<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoop/data/dfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/hadoop/data/dfs/datanode</value>
</property>
</configuration>mapred-site.xml(没有的话,可以复制这个文件(mapred-site.xml.template)修改下)
![]()
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>这里注意一点就是,格式化namenode时,只需要首次安装启动时执行一次就可以了,多次执行这个命令会出现问题,下面也会附上这个问题的解决办法。
5、启动windows命令行窗口,进入hadoop-2.7.2\bin目录,执行下面2条命令,先格式化namenode再启动hadoop
(1)格式化namenode,进入目录cd /d D:\hadoop-2.7.2\bin ,执行: hadoop namenode -format ;
(2)启动hadoop,进入sbin目录,接上条,执行:cd ..\sbin 等价于(cd /d D:\hadoop-2.7.2\sbin),执行:start-all.cmd
后续重启的话,无需再格式化namenode,只要stop-all.cmd再start-all.cmd就可以了。
(3)启动后,可以用浏览器到localhost:8088看mapreduce任务,到localhost:50070->Utilites->Browse the file system看hdfs文件。
6、照上面的操作安装并启动hadoop后,接下来在eclipse里配置hadoop开发环境:
下载eclipse插件并丢到eclipse的pulgin(有的是:dropins)目录下,重启eclipse,Project Explorer出现DFS Locations;路径如下:

7、点击Window->点Preferences->点Hadoop Map/Reduce->填D:\hadoop-2.7.2并OK;
8、见截图:
点击Window->点Show View->点MapReduce Tools下的Map/Reduce Locations->点右边角一个带+号的小象图标"New hadoop location"->eclipse已填好默认参数,但以下几个参数需要修改以下,参见上文中的两个配置文件core-site.xml和hdfs-site.xml:
General->Map/Reduce(V2) Master->Port改为9001
General->DSF Master->Port改为9000
Advanced paramters->dfs.datanode.data.dir改为ffile:/hadoop/data/dfs/datanode
Advanced paramters->dfs.namenode.name.dir改为file:/hadoop/data/dfs/namenode



9、点击Finish后在DFS Locations右键点击左边三角图标,出现hdsf文件夹,可以直接在这里操作hdsf,右键点击文件图标选"Create new Dictionery"即可新增,再次右键点击文件夹图标选Reflesh出现新增的结果;此时在localhost:50070->Utilities->Browse the file system也可以看到新增的结果;
10、新建hadoop项目:File->New->Project->Map/Reduce Project->next->输入自己取的项目名如hadoop再点Finish,分别见java包和Java类,如下图:

11、WordCount代码的例子如下:
package test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
/**
* Hadoop - 统计文件单词出现频次
* @author antgan
*
*/
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
}
public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
// 判断output文件夹是否存在,如果存在则删除
Path path = new Path(args[1]);// 取第1个表示输出目录参数(第0个参数是输入目录)
FileSystem fileSystem = path.getFileSystem(conf);// 根据path找到这个文件
if (fileSystem.exists(path)) {
fileSystem.delete(path, true);// true的意思是,就算output有东西,也一带删除
}
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}12、点击hadoop(自己起的名),右键:先建文件夹,再上传文件到该目录下:


13、运行,arguments里面输入:hdfs://localhost:9000/input hdfs://localhost:9000/output


可能会遇到的问题如下:
初学者可能会遇到这个问题,在第一次格式化dfs后,启动并使用了hadoop,后来又重新执行了格式化命令(hdfs namenode -format),这时namenode的clusterID会重新生成,而datanode的clusterID 保持不变。导致namenode节点无法启动,报错的表现就是:eclipse里可以上传文件到HDFS,但文件内容为空。
例如如下报错:
2014-06-18 20:34:59,622 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool <registering> (Datanode Uuid unassigned) service to localhost/127.0.0.1:9000
java.io.IOException: Incompatible clusterIDs in /usr/local/hadoop/hdfs/data: namenode clusterID = CID-af6f15aa-efdd-479b-bf55-77270058e4f7; datanode clusterID = CID-736d1968-8fd1-4bc4-afef-5c72354c39ce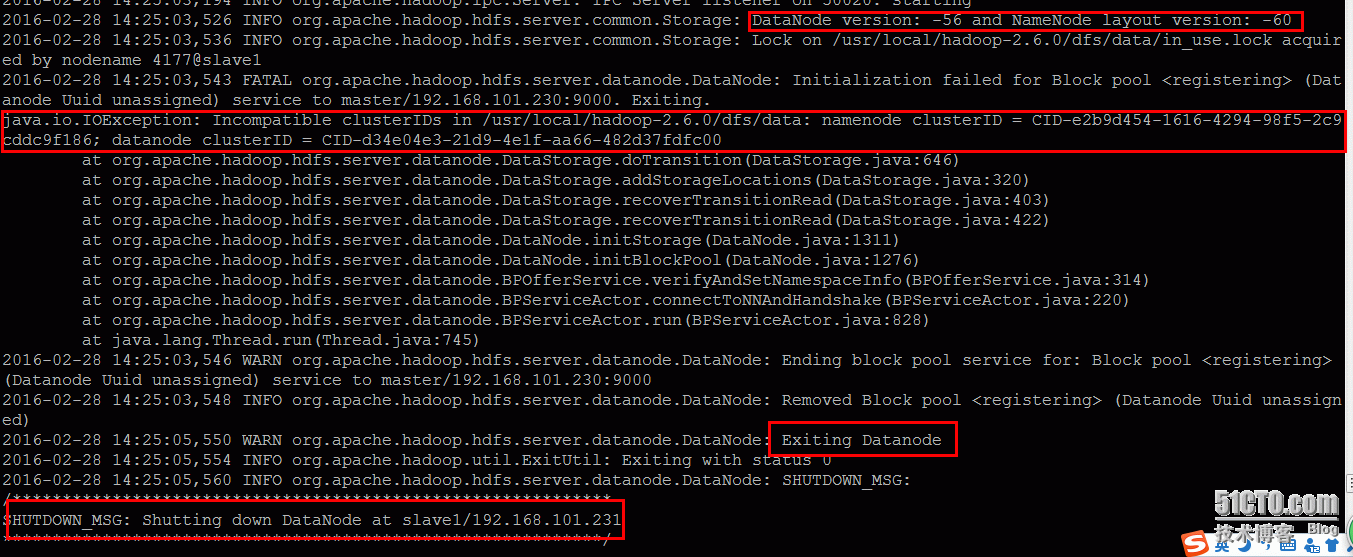
解决办法:
1、windows下:
在windows下,在安装目录的根目录下,启动hadoop后会自动生成一个文件夹,例如,我的hadoop安装在software下面,但hadoop数据文件会生成在hadoop那个文件夹下(在hdfs-site.xml 里配置的),这点可以从日志里面看出来,所以,报错仔细观察日志很重要!!!

 ,将这个目录下的文件都删除,可以在hdfs-site.xml里配置修改路径。重新格式化, hadoop namenode -format ,再启动,start-all.cmd。
,将这个目录下的文件都删除,可以在hdfs-site.xml里配置修改路径。重新格式化, hadoop namenode -format ,再启动,start-all.cmd。
2、linux下:(可以通过日志找对应的目录,这个路径是在hdfs-site.xml里配置的)
1、停止dfs
$./stop-dfs.sh
2、删除在hdfs中配置的data目录和tmp目录
$ rm -r /home/data
$ rm -r /home/tmp
重新创建data目录和tmp目录
$ mkdir data
$ mkdir tmp
3、重新格式化namenode
$ hadoop namenode -format
4、重新启动dfs
$./start-dfs.sh
5、查看dfs
$ jps