进入Hadoop 主目录下
创建 mkdir opt 创建一个opt 目录
xftp上传文件

上传完成 ll 查看文件
tar:压缩、解压缩 tar -xzf 文件名(输文件名时可以输入前面几个字母后按Tab键) -C 目录
解压完成, 配置环境变量
修改环境配置的文件 vi ~/.bashrc

保存退出
更新环境变量
source ~/.bashrc
输入Java查看成功
Hadoop环境变量配置
切换到Hadoop下:

解压缩 tar -xzf hadoop-2.7.5.tar.gz
配置环境变量

echo export HADOOP_HOME="pwd" >> ~/.bashrc
查看文件 cat bashrc

配置HADOOP_CONF_DIR

(1)配置PATH vi ~/.bashrc (删除上面的PATH,重新写入一个新的)
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

更新配置文件:source ~/.bashrc
输入Hadoop 测试环境变量
配置静态文件:
切换到root 用户
查看网段:ifconfig
路径:vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改BOOTPROTO=static onroot = yes
添加
IPADDR=192.168.33.110 (33设置成你的网段,最后随便设置,请牢记这个ip)
NETMASK=255.255.255.0
GATEWAY=192.168.33.2(这里的33也请改成你的网段)
DNS1=202.106.0.20

重启network systemctl restart network
重新登陆 切换root用户
修改主机名 vi /etc/hostname
修改主机映射 vi /etc/hosts

保存退出,
重启 reboot
修改win下的映射


修改完成 重新连接linux
进入配置目录:

(1)配置 core-site.xml
在configuration添加以下内容 然后保存退出
<property>
<name>fs.defaultFS</name>
<value>hdfs://python2:9000</value>
</property>
(1)配置hdfs-site.xml
在configuration添加以下内容 然后保存退出
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/opt/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/opt/tmp/dfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>python2:50070</value>
</property>
(1)配置mapred-site.xmll
ll查看当前目录会发现没有mapred-site.xml文件,只有一个mapred-site.xml.template的文件,我们复制一份命名为mapred-site.xml: cp mapred-site.xml.template mapred-site.xml
在configuration添加以下内容 然后保存退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(1)配置yarn-site.xml
在configuration添加以下内容 然后保存退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>python2</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
(1)修改 slaves
slaves
配置datanode的主机名称
python 05
切换到root 用户下:
关闭防火墙
临时关闭:systemctl stop firewalld
永久关闭:systemctl disable firewalld
查看状态:systemctl status firewalld
关闭selinux
临时关闭:setenforce 0
永久关闭:vi /etc/selinux/config
修改 SELINUX =disabled
getenforce:查看状态
重启机器 reboot
重新连接,登录hadoop
执行hdfs文件系统格式化:hdfs namenode -format
1.配置ssh无密码登录
输入ssh-keygen -t rsa 一直回车
ssh-copy-id 你想登录到的计算机名 输入hadoop的密码

启动服务 start-dfs.sh
start-yarn.sh
启动所有服务:start-all.sh
jps:查看启动的服务
浏览器访问,输入python2:50070
1.创建一个目录 hadoop fs -mkdir -p /user/hadoop
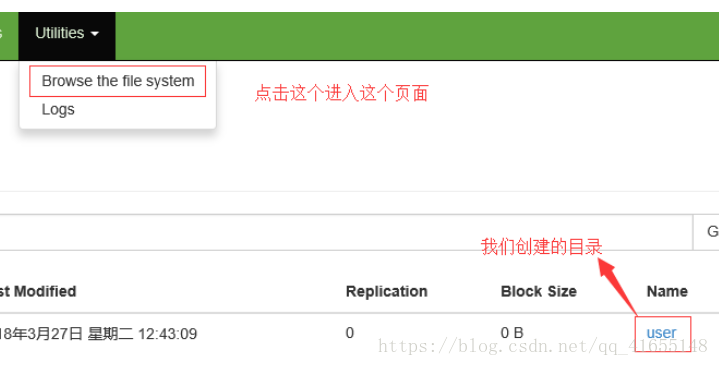
新建一个文件 :touch data.txt 并写一点内容
上传文件:

查看:点击user 进入查看
一.Anaconda的安装
1.安装前需要安装bzip2 yum -y install bzip2
(1)需要root用户,切换用户
1.开始安装Anaconda bash Anaconda3-5.0.1-Linux-x86_64.sh




更新环境变量
source ~/.bashrc
查看jupter地址 jupyter-notebook --ip python2
查看的时候有时候报错权限不够
切换到root用户下:
sudo chmod 777 /run/user/0/
切换到Hadoop下: su hadoop
再执行:jupyter-notebook --ip python02

1.进浏览器,输入你复制的地址
一.spark的安装

1.解压缩到 opt目录 tar -xzf spark-2.2.1-bin-hadoop2.7.tgz -C opt

1.更新环境变量
测试: